
This article was written by James Le. Here is a brief summary. Link to the full article is provided at the bottom. Some techniques are not mentioned in Le’s article, for instance neural networks, K-NN, density estimation, time series models, survival analysis, Markov chains, Bayesian statistics, graph models, and spatial processes. However his article is a great read, with the 10 topics explained in details, in a style accessible to the novice.
Regardless of where you stand on the matter of Data Science sexiness, it’s simply impossible to ignore the continuing importance of data, and our ability to analyze, organize, and contextualize it. With technologies like Machine Learning becoming ever-more common place, and emerging fields like Deep Learning gaining significant traction amongst researchers and engineers — and the companies that hire them — Data Scientists continue to ride the crest of an incredible wave of innovation and technological progress.
While having a strong coding ability is important, data science isn’t all about software engineering (in fact, have a good familiarity with Python and you’re good to go). Data scientists live at the intersection of coding, statistics, and critical thinking. As Josh Wills put it, “data scientist is a person who is better at statistics than any programmer and better at programming than any statistician.”
Why study Statistical Learning? It is important to understand the ideas behind the various techniques, in order to know how and when to use them. One has to understand the simpler methods first, in order to grasp the more sophisticated ones. It is important to accurately assess the performance of a method, to know how well or how badly it is working. Additionally, this is an exciting research area, having important applications in science, industry, and finance. Ultimately, statistical learning is a fundamental ingredient in the training of a modern data scientist. Examples of Statistical Learning problems include:
- Identify the risk factors for prostate cancer.
- Classify a recorded phoneme based on a log-periodogram.
- Predict whether someone will have a heart attack on the basis of demographic, diet and clinical measurements.
- Customize an email spam detection system.
- Identify the numbers in a handwritten zip code.
- Classify a tissue sample into one of several cancer classes.
- Establish the relationship between salary and demographic variables in population survey data.
Below are 10 statistical techniques you should master.
1. Linear Regression
- Simple Linear Regression
- Multiple Linear Regression
2. Classification
- Logistic Regression
- Discriminant Analysis
- Linear Discriminant Analysis
- Quadratic Discriminant Analysis
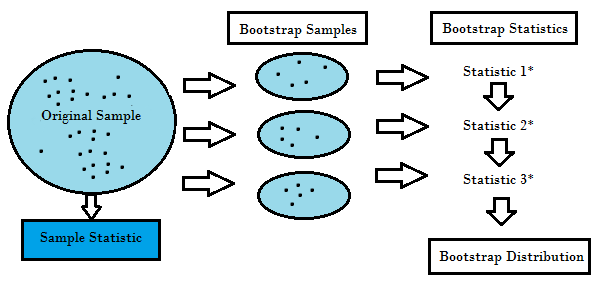
3. Resampling Methods
- Bootstrapping
- Cross Validation
4 . Subset Selection
- Foward
- Backward
- Stepwise
- Best
5 . Shrinkage
- Ridge Regression
6. Dimension Reduction
- Principal Components Regression
- Partial Least Squares
7 . Nonlinear Models
- Step Function
- Piecewise Function
- Splines
- Generalized Additive Model
8 . Tree-Based Methods
- Bagging
- Boosting
- Random Forests
9 . Support Vector Machines
10 . Unsupervised Learning
- Principal Component Analysis
- k-Means Clustering
- Hierarchical Clustering
To read the rest of the article, with illustrations, click here. These topics are also covered on DSC,use our search engine to explore and find many interesing articles about them.
DSC Resources
- Book and Resources for DSC Members
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Find a Job
- Post a Blog | Forum Questions
{kind=link}