
The goal of both logical and physical architecture specifications is to define and document the logical and physical components of a system, respectively, in order to provide clarity around how those component elements relate to one another. The artifacts resulting from either effort could be text documentation, or diagrams, and both have their own advantages and drawbacks.
This is an extract is taken from Hands-On Software Engineering with Python which is written by Brian Allbee and published by Packt.
Text documentation is usually quicker to produce, but unless there is some sort of architectural documentation standard that can be applied, the formats can (and probably will) vary from one system team to another, at a minimum. That sort of variance can make it difficult for the resulting artifacts to be understandable outside the team that it originated with. If there is not a lot of movement of developers between teams, or a significant influx of new developers to teams, that may not be a significant concern. It can also be difficult to ensure that all of the moving parts or the connections between them are fully accounted for.
The primary advantage to diagrams is the relative ease with which they can be understood. If the diagram has obvious indicators, or symbols that unambiguously indicate, for example, that one component is a database service and another is an application, then the difference between them becomes obvious at a glance. Diagrams also have the advantage of being more easily understandable to non-technical audiences.
In both cases, text-based or diagram-based documents are, obviously, most useful if they are well-constructed, and provide an accurate view or model of the system.
Logical architecture
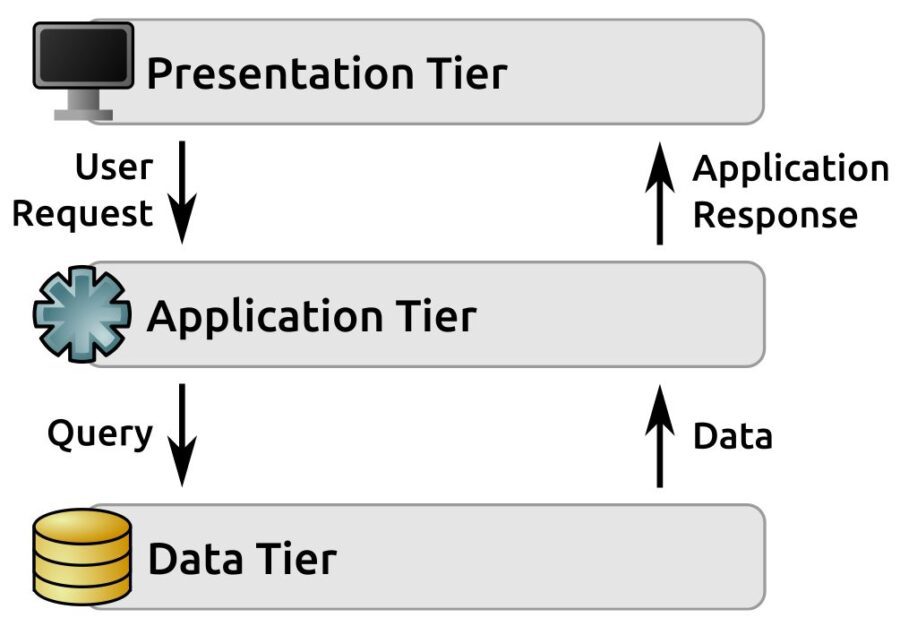
Development is often going to be more concerned with the logical architecture of a system than with the physical. Provided that whatever mechanisms needed are in place for the actual code in a system to be deployed to, live on, connect to, and use the various physical components that relate to the logical components, and that any physical architecture constraints are accounted for, little more information is generally needed, so where any given component lives just isn’t as important from that perspective. That often means that a physical architecture breakdown is at best a nice-to-have item, or maybe a should-have at most. That also assumes that the structure in question isn’t something that’s so commonplace that a need for it to be documented surfaced. There are, for example, any number of systems in the wild that follow the same common three-tier structure, with a request-response cycle that progresses as follows:
- A user makes a request through the Presentation Tier
- That request is handed off to the Application Tier
- The application retrieves any data needed from the Data Tier, perhaps doing some manipulation or aggregation of it in the process
- The Application Tier generates a response and hands it back to the Presentation Tier
- The Presentation Tier returns that response to the user
It looks a little like this:
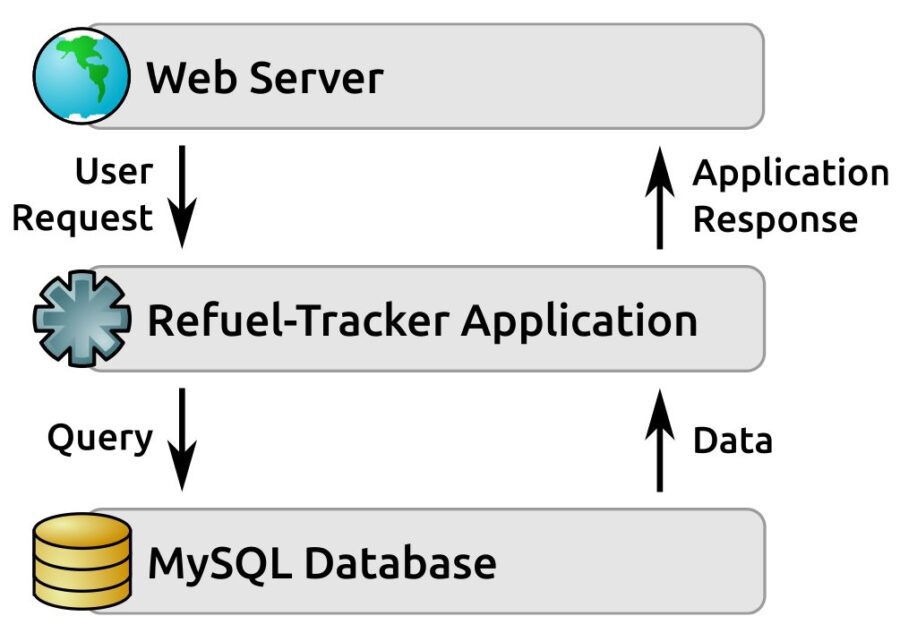
This three-tier architecture is particularly common in web applications, where:
- The Presentation Tier is the web-server (with the web browser being no more than a remote output-rendering component)
- The Application Tier is code called by, and generating responses to, the web server, written in whatever language and/or framework
- The Data Tier is any of several back-end data-store variants that persist application data between requests
Consider, as an example, the following logical architecture for a refueling-tracking system concept. It serves as a good example of this three-tier architecture as it applies to a web application, with some specifically identified components:
Physical architecture
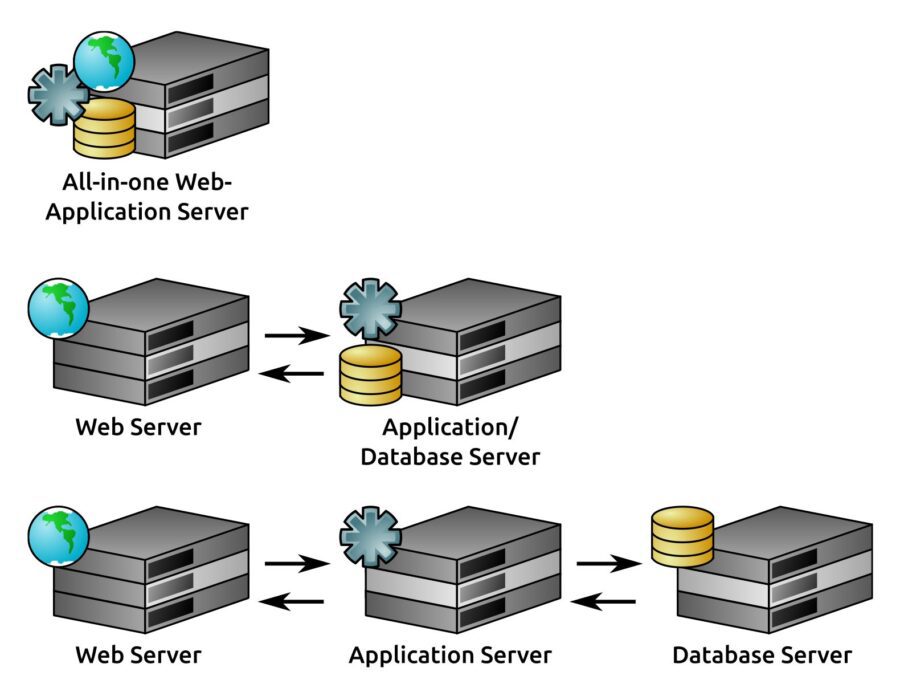
The primary difference between logical and physical architecture documentation is that, while logical architecture’s concerns end with identifying functional elements of the system, physical architecture takes an additional step, specifying actual devices that those functional elements execute on. Individual items identified in logical architecture may reside on common devices, physically.
Really, the only limitations are the performance and capabilities of the physical device. This means that these different physical architectures are all logically identical; they are all valid ways of implementing the same three-tier web application’s logical architecture:
The impact of virtualization and cloud
With the current enthusiasm for virtualization, serverless, and cloud-based technologies in the industry provided by public and private cloud technologies such as Amazon Web Services and VMware, whether a physical architecture specification really is a physical architecture often becomes something of a semantics quibble. While, in some cases, there may not be a single, identifiable physical computer the way there would be if there was a dedicated piece of server hardware, in many cases that distinction is irrelevant. If it acts like a distinct physical server, it can be treated as one for the purposes of defining a physical architecture. In that case, from a documentation standpoint, there is no knowledge value lost in treating a virtual server like a real one.
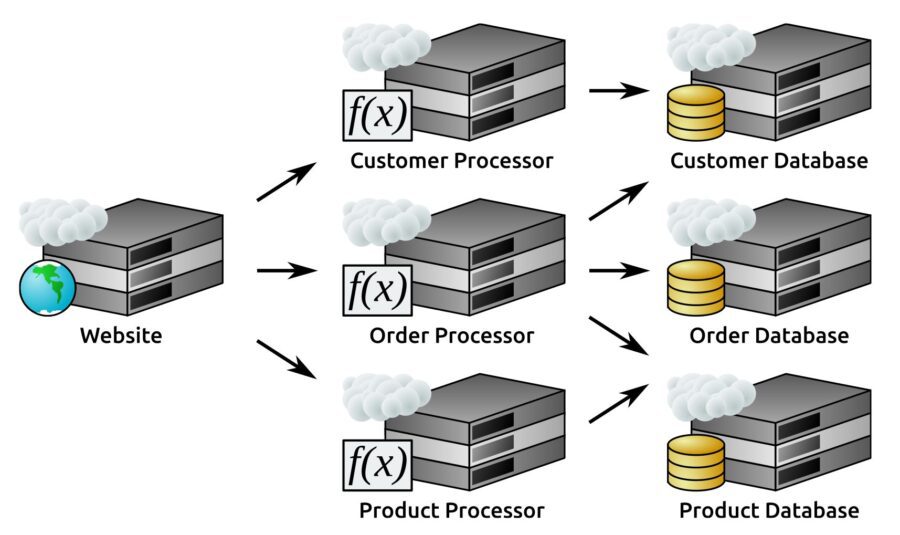
When considering many serverless elements in a system,several can still be represented as a physical architecture element as well – so long as it acts like a real device from the perspective of how it interacts with the other elements, the representation is adequate.That is, given a hypothetical web application that lives completely in some public cloud, where:
That cloud allows serverless functions to be defined
Functions will be defined for processing the following, with back-end databases for each of those entities also living in the cloud:
- Customers
- Products
- Orders
A corresponding physical architecture might look something like this:
An example real-world implementation of this serverless architecture can be implemented in all three of the big-name public clouds: Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP).
Each of these public cloud platforms provides virtual server-instances that could serve the website and maybe databases. The processor servers in this structure could use serverless functions (AWS Lambda, or Cloud Functions in Azure and GCP) to drive the interactions between the website and the databases as the website sends events to the functions in the processor elements.
If you are a developer having basic understanding of programming and its paradigms and want to skill up as a senior programmer then Packt’s latest book Hands-On Software Engineering with Python is for you.
{kind=link}