
It’s that time of year again when I look into the Crystal Skull…er, ball, and make some predictions of the continuing challenges and new trends I foresee in Big Data and Data Science for the coming year.
It’s Data “Business Model” Transformation, not Digitalization

Digital Transformation moves beyond just “digitalization”. I chose “Groundhog Day” as representative of how people are confusing Digitalizationover and over again – which is the integration of digital technologies such as cloud native apps and mobile devices into existing operational processes – with Digital Transformation– which is about leveraging the economics of big data, IOT and advanced analytics (machine learning, deep learning, artificial intelligence) to uncover new sources of customer, operational and market value.
Digitalizationreplaces human-centric processes with sensors to gather usage or performance data, whileDigital Transformationuses digital technologies such as machine learning, deep learning and blockchain to create new sources of customer and market value, and re-engineer the organization’s business models (see Figure 1).

Figure 1: Digitalization versus Digital Transformation
See the blog “It’s Not Digital Transformation; It’s Digital ‘Business’ Transforma…” for more details on what Digital Transformation really entails.
Data Monetization Continues to Be the CIO’s #1 Challenge

I chose “Other People’s Money” as the movie that represents the challenge that the Chief Data Officer (CDO) faces in trying to drive data monetization. Part of the data monetization problem resides in the fact that many organizations perceive the term “monetization” as representing a “value in exchange” (what someone is willing to pay me for my data) versus “value in use” (leveraging the insights buried in the data to create new sources of value).
It’s an economics conversation, not an accounting conversation!
I predict that 2019 is the year when organizations’ Chief Data Officers laser-focus their charter around data monetization. However as I have stated in the past, I think leading organizations will rename the CDO title to “Chief Data Monetization Officer” to clarify the charter and differentiate the CDO/CDMO role from that of the CIO, who is focused on managing the infrastructure that supports the organization’s data (see Figure 2).
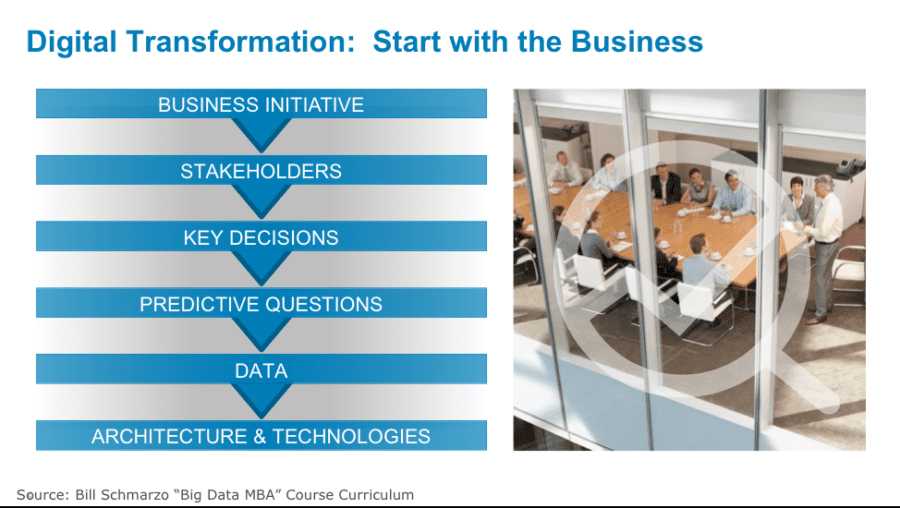
Figure 2: Data Monetization Starts with the Business
See the blog “Data Monetization? Cue the Chief Data Monetization Officer” for more details on the expanded role of the Chief Data Officer’s responsibility in driving an organization’s data monetization strategy.
Data Lakes Continue to Under-perform

I chose “Planes, Trains and Automobiles” as representative of the struggles that many organizations are having with their data lakes. Data lakes continue to under-deliver, but in 2019 organizations will realize that their data lake performance problems are not a technology issue, but is instead a focus issue. Too many organizations are too focused on using the data lake as a way to reduce the costs associated with data (via data warehouse ETL off-loading, data archiving and data staging). CIO’s are missing the bigger opportunity to convert their data lake into a collaborative value creation platform around which the business stakeholders and the data science team can collaborate to leverage data and analytics to power the organization’s key business initiatives such as reducing customer attrition, unplanned operational downtime, and obsolete and excessive inventory; or improving on-time deliveries (see Figure 3).
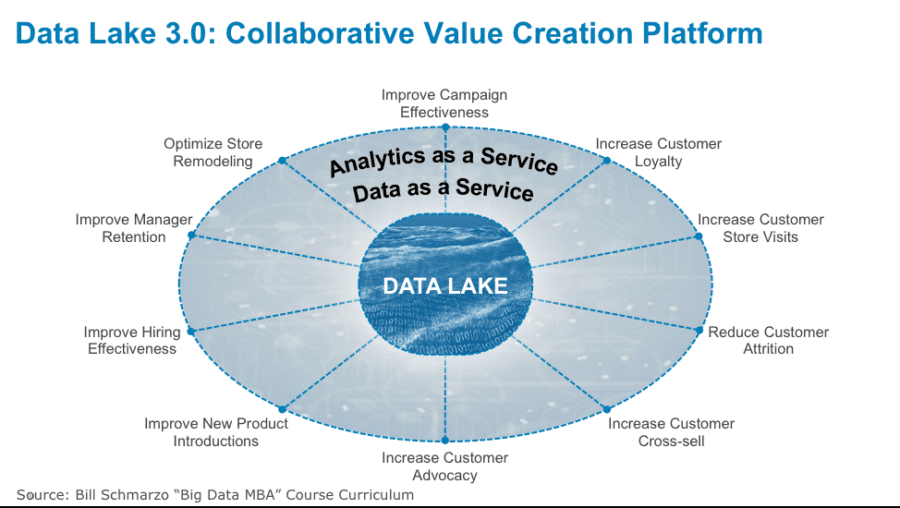
Figure 3: Data Lake is a Collaborative Value Creation Platform
See the blog “Realizing the Potential of Data Monetization…Do I Have Your Attenti…?” for more details on the transformation of the data lake into an organization’s collaborative value creation platform.
Data Engineering Gets Hot

I chose “Are We Done Yet?” to represent that 2019 is the year that Data Engineering gets its due respects as a full-fledged member of the data science community. A data scientist is only as effective as the data that they have with which to work, and for the data scientist to be effective, they need to have a data engineer partner-in-crime.
The data engineer:
- Co-develops the big data architecture that helps analyze and process data that the organization requires and further optimizes those systems to perform smoothly.
- Collects the data from a variety of traditional and non-traditional sources, stores it in a data lake, cleanses and integrates the data (data prep) for analysis.
- Evaluates, compares and improves the different approaches including design patterns innovation, data lifecycle design, data ontology alignment, annotated datasets, and elastic search approaches.
- “Wrangles” the data which transforms, maps and “munges” the raw data using algorithms (e.g. sorting, parsing) into predefined data structures, and deposits the results into a data lake for the data scientist (see Figure 4).
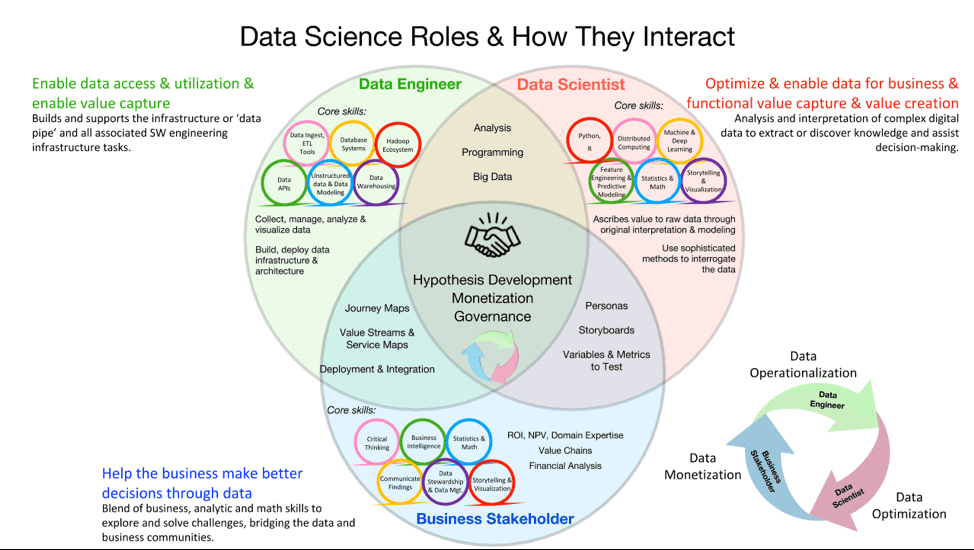
Figure 4: Data Science Community Roles and Responsibilities
See the blog “A Winning Game Plan for Building Your Data Science Team” for more details on the roles and responsibilities of your data science community members.
Over-hyping of AI Delays Business Benefits

I chose “Tin Men” to represent the over-hyping of Artificial Intelligence (AI) capabilities in 2019, which I expect will get even worse (I expect AI-infused Skippy peanut butter and Cap’n Crunch cereal are just around the corner!). The AI over-hyping around more cultural distractions and human job loss prognostications results in less progress in driving the commercialization and monetization of AI.
But folks are slowly starting to realize that AI, especially in the form of machine learning (i.e., linear regression, logistic regression, decision trees, K-Nearest Neighbor, Support Vector Machine), has been around for decades without causing any dramatic cultural shifts or demise of the human race. I have yet to see a K-means cluster (an unsupervised machine learning algorithm) round up helpless humans for death camps…yet.
Unfortunately, all the AI over-hyping and consternation will delay the business, operational and society benefits that AI (see Figure 5).
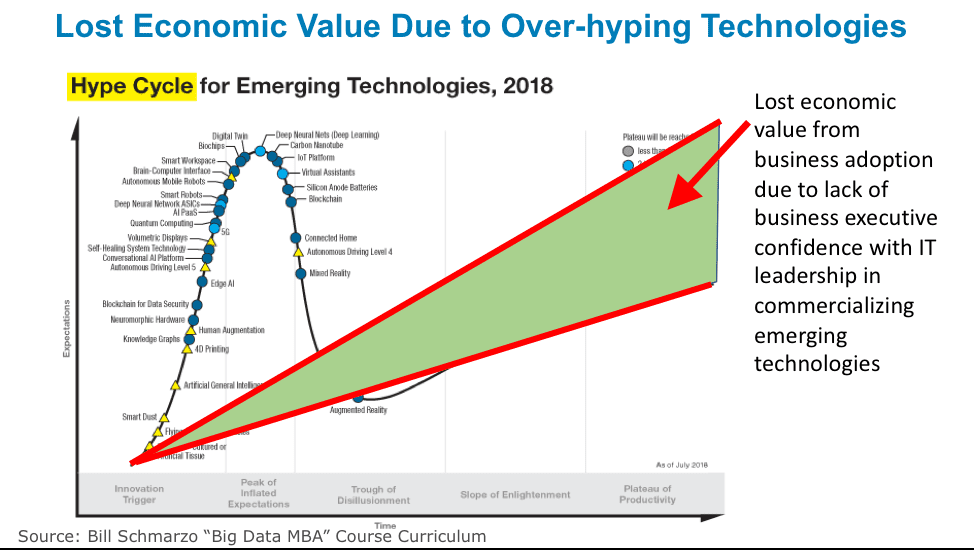
Figure 5: Economic Costs of Over-hyping New Technologies like AI
See the blog “Why Accept the Hype? Time to Transform How We Approach Emerging Tec…” for more details on the economic costs of over-hyping new technologies such as AI and Blockchain.
The Battle of Tomorrow Is at the Edge

I chose “Edge of Tomorrow” to represent the Battle for the IoT Edge(what, you don’t think that movie was a comedy?). And the battle for the IoT edge will be fought by Industrial (OT), not technology (IT), companies. The edge doesn’t start at the IoT gateway, the edge starts at the PLC and the sensors that are generating the data. These PLC’s are getting smarter as more storage, compute, machine learning and AI capabilities are pushed to the edge.
Too many IT companies think of the Internet of Things (IoT) as just another data source to be housed in their storage devices. But IoT is more than just another data source. IoT represents ability to take actions at point of data capture; to apply Machine Learning at data capture to optimize operational decisions.
That’s the power of the edge (see Figure 6).
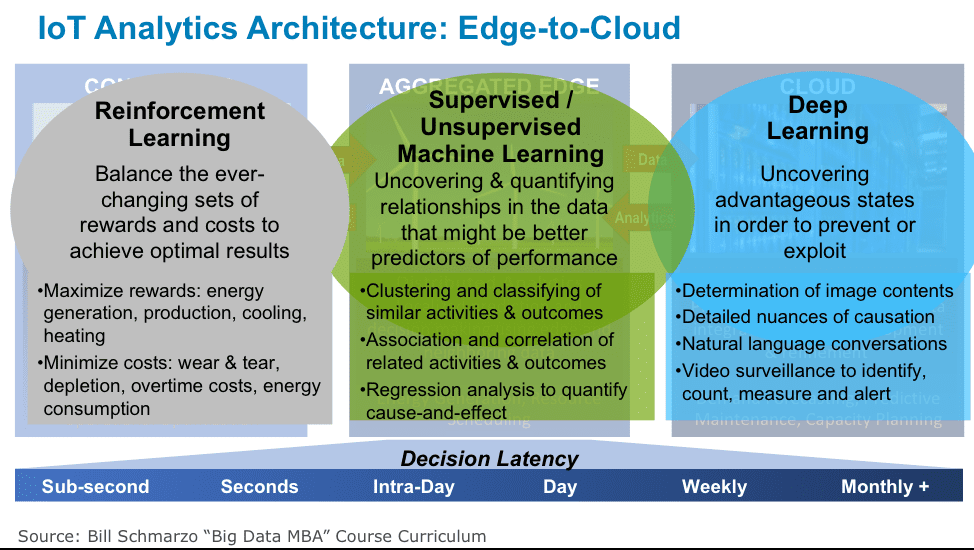
Figure 6: Advanced IoT Architecture Supports Edge Data Capture, Analytics and Actions
See the blog “Tomorrow’s Digital Transformation Battles Will Be Fought at the Edge” for more details about the data and analytic capabilities offered by the Internet of Things.
Finally, the “Game of Thrones” final season will decimate data and analytics nerds’ productivity in 2019 (See last year’s Game of Thrones blog Stopping the White Walkers of Data Monetization).
Winter is coming, baby!

{kind=link}