
Our world is fuelled by information, today more than ever before. Social media, technology, the internet at large – all of these contribute to a curious society who will not tolerate a knowledge gap, especially when it comes to business and government. The amount of data online is staggering, and if unlocked, could contribute to a more efficient, responsive and effective society, spurring on economic growth and unleashing limitless potential.
A Global Picture of Open Datasets
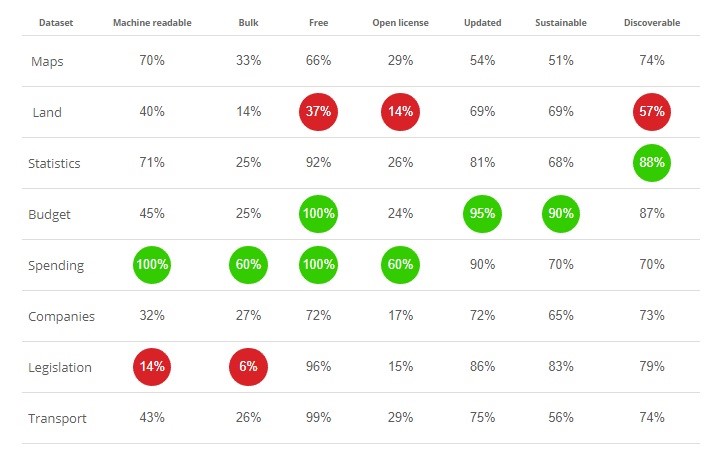
Across studies of more than 115 countries, open data in some form or another is available in 97%. However, this statistic may paint a rosier picture than is actually the case. Only 74% of the datasets are up to date, and only 24% of it can be accessed and downloaded without a license. A little over half of the data available can be accessed in a reusable way, making 47% impossible to utilize for further study or comparability. Below you can see some of the common barriers to access for open data around the world, and how they compare between categories.
Let’s look a little closer to home, at the statistics for open data within the US. Looking at a map of all the States, the comprehensiveness of their key datasets shows an uneven knowledge-base. While some States like Colorado score A+ in a category like Companies, (the register of all corporations that exist within the State) others like California are scored F. This score is brought down by similar factors to the worldwide data, such as the datasets being incomplete, unverifiable, in-comparable, and with licensing restrictions.
It’s also important to recognize that individual cities may be more inclined to share open data, creating laws and initiatives to push the transparency and comprehensiveness of key datasets. Washington DC for example have evidence of their intention to begin publishing open datasets of city operational metrics in the District of Columbia as far back as 2006, while Connecticut mandated a state-wide open data portal in 2014. In cities without state-wide policies in place, the open data available may be skewed towards a smaller number of districts.
Understanding the Comparability of Open Data
The very nature of a lot of the datasets in use means that comparability is always going to be a tough nut to crack. For example, on issues like crime or healthcare, there are too many variables between States to reliably compare data and make intelligent conclusions. On the contrary however, some data will be easily compared across States – such as open data on inspections or permits, which are widely speaking similar from place to place and require municipal inspectors to adhere to national laws on compliance and health and safety.
Within a category, there is no set standard for how to organize and discover open data – which leads to some confusion when it comes to utilizing even comprehensive sources of key datasets. For example, in Kansas City, Missouri the open data regarding building permits is broken down by years and geographic location. This would force a researcher to comb through several disparate datasets to get a good understanding of the topic as a whole. In general, our researchers have found little correlation if any between quality and quantity of open data across the USA, with some States like Boston containing a limited number of datasets, and yet still covering a wide variety of topics. Others may have a huge amount of data, but as it is disorganized or incomplete – the value of this data is questionable.
Apertio: Cutting Through the Noise
Apert.io is the first global database and search engine for open data, starting with the US, and constantly expanding its reach. It has the largest coverage in the world, with more than 2000 open data sites included, which together hold trillions of records. From a single point of access, data that was historically out of reach for the masses is now discoverable, available and easy to access.
With in-data search, Apert.io is ahead of the competition, uncovering the insights within the data, rather than relying on publisher’s classifications – many of which are incomplete or inaccurate. In this way, our data is both comprehensive and comparable, allowing users to find the data that truly addresses their needs. Data analysts can quickly and accurately find the information they’re looking for, while data publishers can get a true benchmark of their peers’ data publications in terms of both quantity and quality.
Uncovering the hidden gems of open data shouldn’t be held back by issues of comprehensiveness or comparability, and at Apert.io – we’re leading the way.
{kind=link}