

In this article, I illustrate the concept of asymmetric key with a simple example. Rather than discussing algorithms such as RSA, (still widely used, for instance to set up a secure website) I focus on a system easier to understand, based on random permutations. I discuss how to generate these random permutations and compound them, and how to enhance such a system, using steganography techniques. I also explain why permutation-based cryptography is not good for public key encryption. In particular, I show how such as system can be reverse-engineered, no matter how sophisticated it is, using cryptanalysis methods. This article also features some nontrivial, interesting asymptotic properties of permutations (usually no taught in math classes) as well as the connection with a specific kind of matrices, yet using simple English rather than advanced math, so that this article can be understood by a wide audience.
1. Description of my public key encryption system
Here x is the original message created by the sender, and y is the encrypted version that the receiver gets. The original message can be described as sequence of bits (zeros and ones). This is the format in which is it is internally encoded on a computer or when traveling through the Internet, be it encrypted or not, as computers only deal with bits (we are not talking about quantum computers or quantum Internet here, which operate differently).
The general system can be broken down into three main-components:
- Pre-processing: blurring the message to make it appear like random noise
- Encryption via bit-reshuffling
- Decryption
We now explain these three steps. Note that the whole system processes information by blocks, each block (say 2048 bits) being processed separately.
1.1. Blurring the message
This steps consist in adding random bits at the end of each block (sometimes referred to as padding), then perform a XOR to further randomize the message. The bits to be added consist of zeroes and ones in such a proportion that the resulting, extended block has roughly 50 percent of zeroes and ones. For instance, if the original block contains 2048 bits, the extended blocks may contain up to 4096 bits.
Then, use a random string of bits, for instance 4096 binary digits of square root of two, and do a bitwise XOR (see here) with the 4096 bits obtained in the previous step. The resulting bit string is the input for the next step.
1.2. Actual encryption step
The block to be encoded is still denoted as x, though it is assumed to be the output of the previous step discussed in section 1.1, not part of the original message. The encryption step transforms x into y, and the general transformation can be described by
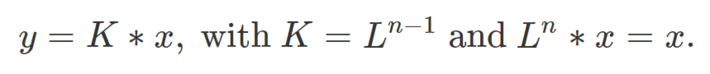
Here * is an associative operator, typically the matrix multiplication or the composition operator between two functions, the latter one usually denoted as o as in (f o g)(x) = f(g(x)). The transforms K and L can be seen as permutation matrices. In our case they are actual permutations whose purpose is to reshuffle the bits of x, but permutations can be represented by matrices. The crucial element here is that L * K = L^n = I (that is, L at power n is the identity operator): this allows us to easily decrypt the message. Indeed, x = L * y. We need to be very careful in our choice of L, so that the smallest n satisfying L^n = I is very large. More on this in section 2. This is related to the mathematical theory of finite groups, but the reader does not need to be familiar with group theory to understand the concept. It is enough to know that permutations can be multiplied (composed), elevated to any power, or inversed, just like matrices. More about this can be found here.
That said, the public and private keys are:
- Public key: K (this all the sender needs to know to encrypt the block x as as y = K * x)
- Private keys: n and L (kept secret by the recipient); the decrypted block is x = L * y
1.3. Decryption step
I explained how to retrieve the block x in section 1.2 when you actually receive y. Once a block is decrypted, you still need to reverse the step described in section 1.1. This is accomplished by applying to x the same XOR as in section 1.1, then by removing the padding (the extra bits that were added to pre-process the message).
2. About the random permutations
Many algorithms are available to reshuffle the bits of x, see for instance here. Our focus is to explain the most simple one, and to discuss some interesting background about permutations, in order to reverse-engineer our encryption system (see section 3).
2.1. Permutation algebra: basics
Let’s begin with basic definitions. A permutation L of m elements can be represented by a m-dimensional vector. For instance L = (5, 4, 1, 2, 3) means that the first element of your bitstream is moved to position 5, the second one to position 4, the third one to position 1, and so forth. This can be written as L(1) = 5 , L(2) = 4, L(3) = 1, L(4) = 2, and L(5) = 3. Now the square of L is simply L(L), and the n-th power is L(L(L…))) where L appears n times in that expression. The order of a permutation (see here) is the smallest n such that L^n is the identity permutation.
Each permutation is made up of a number of usually small sub-cycles, themselves treated as sub-permutations. For instance, in our example, L(1) = 5, L(5) = 3, L(3) = 1. This constitutes a sub-cycle of length 3. The other cycle, of length 2, is L(2) = 4, L(4) = 2. To compute the order of a permutation, compute the orders of each sub-cycle. The least common multiple of these orders is the order of your permutation. The successive powers of a permutation have the same sub-cycle structure. As a result, if K is a power of L, and L has order n, then both L^n and K^n are the identity permutation. This fact is of crucial importance to reverse-engineer this encryption system.
Finally, the power of a permutation can be computed very fast, using the exponentiation by squaring algorithm, applied to permutations. Thus even if the order n is very large, it is easy to compute K (the public key). Unfortunately, the same algorithm can be used by a hacker to discover the private key L, and the order n (kept secret) of the permutation in question, once she has discovered the sub-cycles of K (which is easy to do, as illustrated in my example). For the average length of a sub-cycle in a random permutation, see this article.
2.2. Main asymptotic result
The expected order n of a random permutation of length m (that is, when reshuffling m bits) is
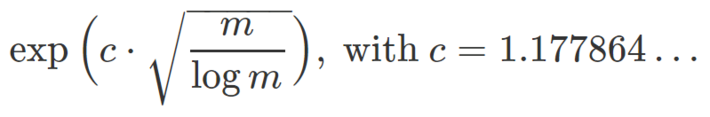
For details, see here. For instance, if m = 4,096 then n is approximately equal to 6 x 10^10. If m = 65,536, then n is approximately equal to 2 x 10^37. It is possible to add many bits all equal to zero to the block being encrypted, to increase its size m and thus n, without increasing too much the size of the encrypted message after compression. However, if used with a public key, this encryption system has a fundamental flaw discussed in section 3, no matter how large n is.
2.3. Random permutations
The easiest way to produce a random permutation of m elements is as follows.
- Generate L(1) as a pseudo random integer between 1 and m. If L(1) = 1, repeat until L(1) is different from 1.
- Assume that L(1), …, L(k-1) have been generated. Generate L(k) as a pseudo random integer between 1 and m. If L(k) is equal to one of the previous L(1), …, L(k-1), or if it is equal to k, repeat until this is no longer the case.
- Stop after generating the last entry, L(m).
I use binary digits of irrational numbers, stored in a large table, to simulate random integers, but there are better (faster) solutions. Also, the Fisher-Yates algorithm (see here) is more efficient.
3. Reverse-engineering the system: cryptanalysis
To reverse-engineer my system, you need to be able to decrypt the encrypted block y if you only know the public key K, but not the private key L nor n. As discussed in section 2, the first step is to identify all the sub-cycles in the permutation K. This is easily done, see example in section 2.1. Once this is accomplished, compute all the orders of these sub-cycle permutations and compute the least common multiple of these orders. Again, this is easy to do, and this allows you to retrieve n even though it was kept secret. Now you know that K^n is the identity permutation. Compute K at power n-1, and apply this new permutation to the encrypted block y. Since y = K * x, you get the following:
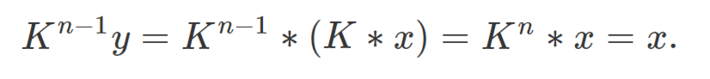
Now you’ve found x, problem solved. You can compute K at the power n-1 very fast even if n is very large, using the exponentiation by squaring algorithm mentioned in section 2.1. Of course you also need to undo the step discussed in section 1.1 to really fully decrypt the message, but that is another problem. The goal here was simply to break the step described in section 1.2.
In order to make a secure system, one must choose a transform K that is very difficult to invert, and permutations or permutation matrices (which can be hacked using the same technique) do not fit the bill. Permutation-based encryption may still be a good idea for symmetric key systems, that is, when no public key is involved.
To receive a weekly digest of our new articles, subscribe to our newsletter, here.
About the author: Vincent Granville is a data science pioneer, mathematician, book author (Wiley), patent owner, former post-doc at Cambridge University, former VC-funded executive, with 20+ years of corporate experience including CNET, NBC, Visa, Wells Fargo, Microsoft, eBay. Vincent is also self-publisher at DataShaping.com, and founded and co-founded a few start-ups, including one with a successful exit (Data Science Central acquired by Tech Target). You can access Vincent’s articles and books, here.
{kind=link}