
This article was written on OpenAI.
We’ve created images that reliably fool neural network classifiers when viewed from varied scales and perspectives. This challenges a claim from last week that self-driving cars would be hard to trick maliciously since they capture images from multiple scales, angles, perspectives, and the like.
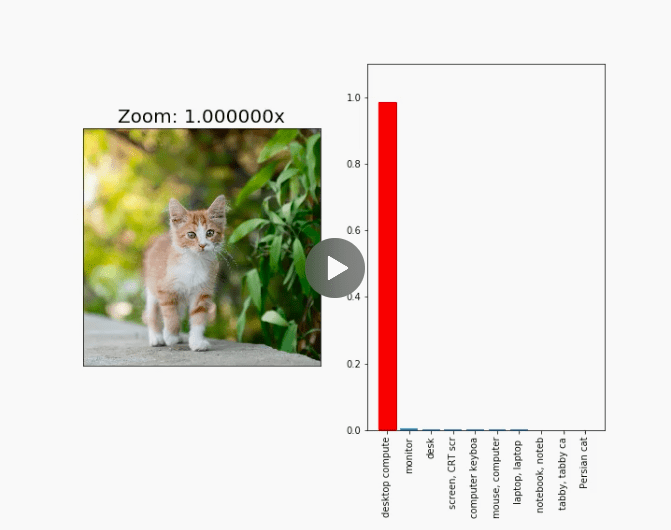
Scale-invariant adversarial examples
Adversarial examples can be created using an optimization method called projected gradient descent to find small perturbations to the image that arbitrarily fool the classifier.
Instead of optimizing for finding an input that’s adversarial from a single viewpoint, we optimize over a large ensemble of stochastic classifiers that randomly rescale the input before classifying it. Optimizing against such an ensemble produces robust adversarial examples that are scale-invariant.
Transformation-invariant adversarial examples
By adding random rotations, translations, scales, noise, and mean shifts to our training perturbations, the same technique produces a single input that remains adversarial under any of these transformations.
To read the whole article, with illustrations and their explanations, click here.
DSC Ressources
- Free Book and Resources for DSC Members
- New Perspectives on Statistical Distributions and Deep Learning
- Deep Analytical Thinking and Data Science Wizardry
- Statistical Concepts Explained in Simple English
- Machine Learning Concepts Explained in One Picture
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Find a Job
- Post a Blog | Forum Questions
{kind=link}