
I loved playing StarCraft, though I seldom played against other humans (my sons in particular, because they absolutely kick my butt). But ah, there is finally revenge for “Dad the Data Nerd”, and it’s known as AlphaStar. AlphaStar was developed by Google’s DeepMind AI group to leverage artificial intelligence (AI) to master the game of StarCraft.

StarCraft is much trickier for AI to master than games like Go and Mario Bros because of its unbounded complexity, continuously-changing gameplay (rather than the distinct events which occur when players take turns), evolving battlefield situations and dependency on constantly tweaking one’s in-game strategy. AlphaStar achieves StarCraft domination using a multi-agent learning algorithm that integrates different advanced analytic algorithms including:
- Supervised Learningthat seeks to quantify the patterns and relationships that lead to certain known outcomes from labeled training data sets (labels such as game victory or defeat).
- Reinforcement Learningthat exploits a trial-and-error way of learning based upon maximizing rewards while minimizing costs.
I want to spend the rest of this blog doing a deep dive on Reinforcement Learning, because to me it is the trial-and-error nature of learning that places Reinforcement Learning squarely in the heart of future Artificial Intelligence aspirations.
Primer on Reinforcement Learning
The goal of Reinforcement Learning is for an autonomous “agent” to learn a successful strategy from experimental trial-and-error within the bounds of a certain operational situation. With the optimal strategy, the agent is able to actively adapt to the changing environment to maximize future rewards while minimizing costs (see Figure 1).
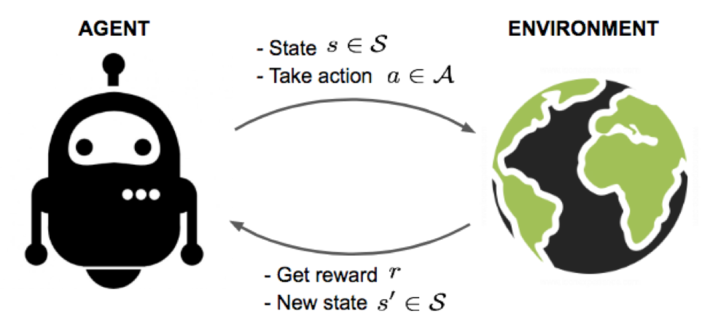
Figure 1: An agent interacts with environment, trying to take smart actions to maximize cumulative rewards
In the blog Artificial Intelligence is not ‘Fake” Intelligence, I discuss how Reinforcement Learning helps software agents take actions in an environment to maximize cumulative rewards while minimizing costs. Reinforcement learning uses trial-and-error to map situations to actions to maximize rewards and minimize costs. Actions may affect immediate rewards, but actions may also affect subsequent or longer-term rewards, so the full extent of rewards must be considered when evaluating the reinforcement learning effectiveness (hint: this is key).
Reinforcement Learning learns by replaying a certain situation (a specific game, vacuuming the house, driving a car) millions of times. The program is rewarded when it makes a good decision and given no reward (or punished) when it loses or makes a bad decision. This system of rewards and punishments strengthens the connections to eventually make the “right” moves without programmers explicitly programming the rules into the game. Yep, Reinforcement Learning is like playing the kids game of Hotter-Colder (except I don’t remember punishment being part of that game).
Reinforcement Learning in Your Home
As an example of Reinforcement Learning in action, the Roomba Model 980 uses it to automate the vacuuming of your house. The 980 transverses the house, identifies obstacles, and remembers which routes work best to clean the house. It literally builds a map of the house and uses each vacuuming excursion to refine and update that map (see Figure 2).
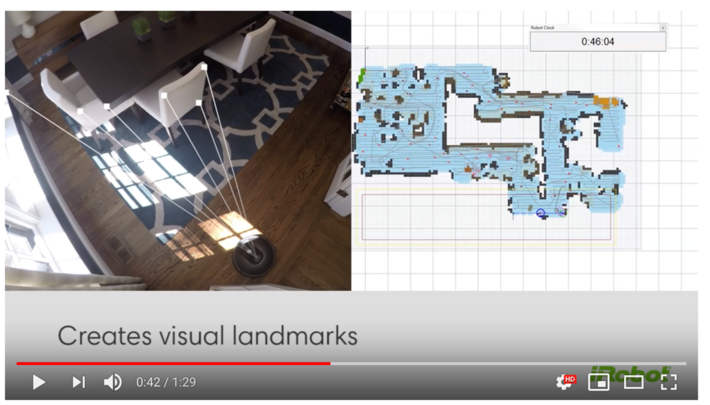
Figure 2: Source: “Roomba 980 Robot Vacuum Cleans a Whole Level of Your Home”
The reinforcement learning powering the Roomba 980 makes the Roomba much more agile and a rapid learner than having to hand code a series of nested “if-then” rules (If “Tumble down stairs”, then “Mark avoid” else “Keep vacuuming”).
Unfortunately, the autonomous Roomba vacuum reminds me of the autonomous lawn mowers from the Jerry Lewis movie “It’s Only Money.” Yea, those things scared the hell out of me when I was a kid (and probably why I’ll never own an autonomous vehicle).

Figure 3: Killer autonomous lawnmowers hunting down Jerry Lewis…and he’s a nice guy!
Louis Kirsch has written a marvelous blog titled A Map of Reinforcement Learningthat provides a lot of information on Reinforcement Learning. The blog provides a great overview on the goals, methods and challenges associated with Reinforcement Learning (see Figure 4).
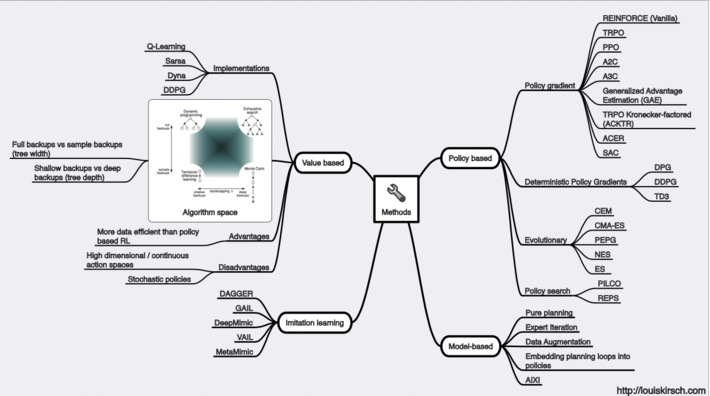
Figure 4: Reinforcement Learning Methods
The Dark Side
But ah, not all is rosy in the land of Reinforcement Learning. We are learning just how human-like reinforcement learning can become. For example, Google’s Reinforcement Learning routines developed a very human-like, cut-throat behavior in a fruit-picking simulation. To quote the article:
“The more intelligent the AI network is, the quicker it is to get aggressive in competitive situations where such aggression will pay off.”
Given the Reinforcement Learning objectives of maximizing rewards while minimizing costs, it makes perfect sense that in a situation of scarce resources, the Reinforcement Learning agent would become highly aggressive to ensure its own survival, even at the cost of the other agents.
As Reinforcement Learning algorithms find their way into more commercial and industrial products, we’re going to have to develop some guidelines to ensure that these products or machines don’t develop habits unintentionally harmful to humans. We are going to have to develop a Reinforcement Learning (AI) methodology that thoroughly and clearly:
- Articulates the Reward Structure. Development teams will need to meticulously research, understand, construct, and validate the rewards or Key Performance Indicators (KPI’s) against which the Reinforcement Learning algorithms will seek to optimize. This must include the development of a robust and comprehensive set of operational scenarios to make sure that one has thoroughly vetted the potential second and third order ramifications of these KPI’s. See the blog Unintended Consequences of the Wrong Measuresfor more details on the potential ramifications of poorly-constructed measures.
- Codifies the Cost Structure. Development teams will also need to thoroughly understand and quantify the costs and/or punishments. This will require a thorough exploration of the costs associated with False Positives and False Negatives. See the blog Using Confusion Matrices to Quantify the Cost of Being Wrongfor insights how to minimize the risks associated with False Positives and False Negatives.
Understanding how Reinforcement Learning works totally explains the behavior of the “Terminator” – it was only doing what its Reinforcement Learning model deemed necessary based upon the codified and articulated sets of rewards and punishment. I guess that could make things a bit scary…just like those dang autonomous killer lawn mowers in that Jerry Lewis movie. I guess I won’t be sleeping again tonight…

{kind=link}