
Our Telecom Client was developing a Big Data Product that will profile demography (Age, Gender, Income, Ethnicity, Marital Status) of the visitors of the stores receiving feed from the wi-fi routers placed in the stores. Client used to receive daily feed of router data in its server which were then uploaded in HDFS / Hive Tables in the data lake for analysis.
Maintaining data quality was a serious issue without which the reports would have been erroneous. A daily e-mail used to get generated by an automated R Code for a sanity check of last night’s data load. Serious issues used to get investigated and reported back for correction.
Two of the major issues in the data quality were to filter out drive-by data and employee data. Since the goal was to analyze store visitor data we need to exclude these noises for quality purpose.
Drive-by records were the wi-fi sessions that were generated by people who didn’t enter the store but generated short session in the wi-fi routers while they were passing by. A lot of analysis went through before filtering out the sessions with duration less than 90 seconds as the drive-by records.
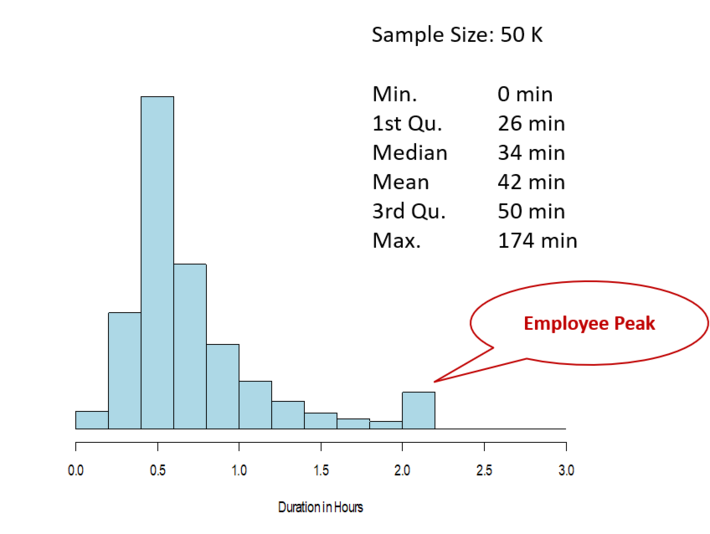 Above histogram presents the duration of wi-fi sessions from 50K records. The peak at 2 hour session was explained to be generated by employees in the store taking break at 2 hours interval. Thus any wi-fi session with duration around 2 hours were decided to be filtered out as the employee data.
Above histogram presents the duration of wi-fi sessions from 50K records. The peak at 2 hour session was explained to be generated by employees in the store taking break at 2 hours interval. Thus any wi-fi session with duration around 2 hours were decided to be filtered out as the employee data.
Many such data science analysis were performed to validate the features of the store visitor profiler that client developed for making corporate level and franchise level market decisions.
{kind=link}