
In this article, we explore a new type of generalized univariate normal distributions that satisfies useful statistical properties, with interesting applications. This new class of distributions is defined by its characteristic function, and applications are discussed in the last section. These distributions are semi-stable (we define what this means below). In short it is a much wider class than the stable distributions (the only stable distribution with a finite variance being the Gaussian one) and it encompasses all stable distributions as a subset. It is a sub-class of the divisible distributions.
Content of this article:
- New two-parameter distribution G(a, b): introduction, properties
- Generalized central limit theorem
- Characteristic function
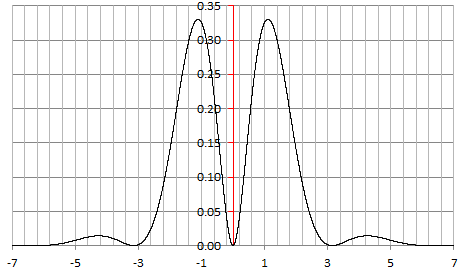
- Density: special cases, moments, mathematical conjecture
- Simulations
- Weakly semi-stable distributions
- Counter-example
- Applications and conclusions
Read the full article here.
{kind=link}