
Summary: The ability to train large scale CNNs directly on your cell phone without sending the data round trip to the cloud is the key to next gen AI applications like real time computer vision and safe self-driving cars. Problem is our current GPU AI chips won’t get us there. But neuromorphic chips look like they will.
 This article is particularly fun for me since it brings together two developments that I didn’t see coming together, real time computer vision (RTCV), and neuromorphic neural nets (aka spiking neural nets).
This article is particularly fun for me since it brings together two developments that I didn’t see coming together, real time computer vision (RTCV), and neuromorphic neural nets (aka spiking neural nets).
We’ve been following neuromorphic nets for a few years now (additional references at the end of this article) and viewed them as the next generation (3rd generation) of neural nets. This was mostly in the context of the pursuit of Artificial General Intelligence (AGI) which is the holy grail (or terrifying terminator) of all we’ve been doing.
Where we got off track was in thinking that neuromorphic nets that are just in their infancy were only for AGI. Turns out that they facilitate a lot of closer-in capabilities, and among them could be real time computer vision (RTCV). Why that’s true turns out to have more to do with how neuromorphics are structured than what fancy things they may be able to do. Here’s the story.
Real Time Computer Vision
In our last article we argued that RTCV will be the next killer app that makes us once again fall in love with our phones and other mobile devices. Problem is that the road map to get there can’t be supported by our current GPU chips or the architecture that requires that the signal go from the phone to the cloud and back again.
That round trip data flow won’t support the roughly 30 frames per second processing RTCV needs, and current chips can’t be made small enough to fit directly on the phone. This is a benchmark case where extremely powerful CNN edge compute is needed.
Problem with Current GPUs
This story was told quite eloquently by Gordon Wilson, CEO of RAIN Neuromorphics at the ‘Inside AI Live’ conference and I will borrow from his explanation.
The first part of the story is to remember that CNNs are based on matrix multiplication. Basically this requires that all the elements in the matrix be multiplied by all the values in the additional dimension. In other words lots of small independent operations.

So the matrix algebra can calculate all the values in the three dimensional matrix necessary for the classification of images through the convolution + RELU and pooling steps of a CNN.
The happy breakthrough we had several years ago was in recognizing that GPU chips (graphical processing units) were doing a very similar thing in which each of the elements of the matrix was a pixel on a screen that needed to be recalculated very rapidly to keep up with the movie-like animation.
GPUs did that by using a chip architecture in which a separate and very simple processing and storage unit was created for each element of the matrix. Doing these calculations in parallel made the screen refresh very fast.
Turns out that pixels on a screen are a very close analog to the weights of the neurons in the convolution value capture step of the CNN. GPUs could do this in parallel for each neuron making it finally fast enough to keep up with our compute needs.
GPUs architecture has been largely unchanged since at least 2006 and it’s likely that most cloud compute AI data center chips will continue to look like this for years to come. This works quite well for the types of image compute AI problems we’ve been encountering. Problem is it won’t scale up to the level needed for RTCV.
It’s simple mechanics. To process problems that have greater dimensions (both width – features, and depth – layers), the chips would have to grow at a rate of n2 (number of nodes squared). But the GPUs we have based on the simple von Neumann architecture are already approaching a kind of Moore’s law limit.
Last week, Intel announced that their premier GPU-based AI stack had outperformed NVIDIA’s best GPU stack by processing 7878 images per second on the ResNet 50 test compared to NVIDIA’s 7844 images. That’s where we are, improvements of 0.4% are considered a big deal.
Another Architecture You May Not Have Heard Of
Another chip architecture that has been getting a lot of attention lately is analog crossbar CNN accelerators. That’s a mouthful, but as simply as I can explain it, this is a basic tiny wire grid where voltages representing the input values enter one axis and the values representing the values passed on to the next level exit on the other axis. The values at the intersections of the two sets of grid wires can be read directly (analog) as representing the weights of the nodes.
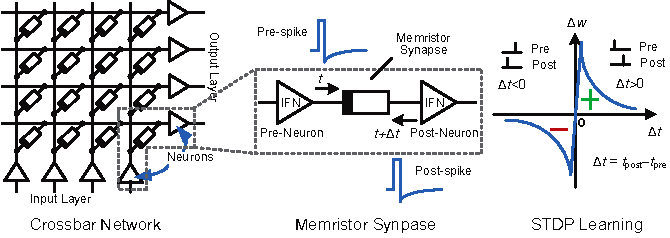
Typically these are found on very small silicon devices called memristors and don’t rely on the von Neumann architecture of process + storage at each intersection (node). As a result they are extremely fast, small, and low power.
The problem is that the physical representation of the CNN on the memristor requires as many input and output nodes as the CNN you want to train. As that number is very large for RTCV, there simply isn’t enough space on a chip. So like GPUs, they fail to scale adequately for this type of application.
Sparsity
Over about the last 18 months the academic research community has been demonstrating that traditional CNNs can be compressed by as much as 90% by simply leaving out the nodes that don’t add to the final calculation. The concept is known as sparsity.
Our CNNs (and our crossbar networks) are all fully connected meaning that every node in a layer is connected to every other node in the next layer. The brain doesn’t work this way and we’ve long suspected that CNNs could be made more compact, and therefore require less compute if only we could figure out which nodes to eliminate.
So far researchers haven’t been able to anticipate in advance which 90% of nodes to leave out during training but they have made some advances in slimming down pretrained CNNs by eliminating the non-value creating nodes. Indications are that sparse CNNs could be 90% smaller and therefore faster and less power hungry. Some tests show they can even be more accurate.
Neuromorphic Chips
Neuromorphic chips as a group are based on design elements that more closely mimic how the brain actually works. That includes the concept of sparsity (not all brain neurons are ‘fully connected’). It also includes the concept of interpreting the spiking signal train produced by the neurons. Is there information in the amplitude, the number of recurring spikes, the time delay between spikes, or all of these?
IBM created the TrueNorth neuromorphic chip for DARPA from a project that started in 2008. Long term startups like Numenta are exploring even more fundamental brain phenomena like hierarchical temporal memory and have commercial licensed products. BrainChip Holdings out of California is listed on the Australian stock exchange and has neuromorphic chips that learn casino games like blackjack from video feeds already in use in Las Vegas casinos to spot cheaters.
The point is that the developing field of neuromorphic chips is not a single concept or architecture and the goals of the individual startups are not the same. However, RAIN Neuromorphics that presented at the ‘Inside AI Live’ conference is focused on sparsity and the edge compute applications like RTCV.
 A picture of their first product comprised of a network of randomly generated nano-wires looks surprisingly like the sparse connections in brain neurons. Their reported performance also has the breakthrough characteristics of representing a very large CNN in an extremely miniaturized and low power chip.
A picture of their first product comprised of a network of randomly generated nano-wires looks surprisingly like the sparse connections in brain neurons. Their reported performance also has the breakthrough characteristics of representing a very large CNN in an extremely miniaturized and low power chip.
Per Gordon Wilson their CEO it may take a few more years to make the chip as small as they want but it appears their roadmap will take them to a chip that could indeed fit in your cell phone and train a large scale CNN on-the-fly.
And that is how neuromorphic chips may well rekindle our love affair with our cell phones by enabling the next generation of video-like applications like AR enhanced navigation. There are 4 billion cell phone users in the world and whole new generations of self-driving vehicles just waiting for this.
Other articles on Neuromorphic Neural Nets
A Wetware Approach to Artificial General Intelligence (AGI)
Off the Beaten Path – HTM-based Strong AI Beats RNNs and CNNs at Prediction and Anomaly Detection
The Three Way Race to the Future of AI. Quantum vs. Neuromorphic vs. High Performance Computing
In Search of Artificial General Intelligence (AGI)
More on 3rd Generation Spiking Neural Nets
Beyond Deep Learning – 3rd Generation Neural Nets
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 1.5 million times.
He can be reached at:
{kind=link}