
Summary: Real Time Computer Vision (RTCV) that requires processing video DNNs at the edge is likely to be the next killer app that powers a renewed love affair with our mobile devices. The problem is that current GPUs won’t cut it and we have to wait once again for the hardware to catch up.

The entire history of machine learning and artificial intelligence (AI/ML) has been a story about the race between techniques and hardware. There have been times when we had the techniques but the hardware couldn’t keep up. Conversely there have been times when hardware has outstripped technique. Candidly though, it’s been mostly about waiting for the hardware to catch up.
You may not have thought about it, but we’re in one of those wait-for-tech hardware valleys right now. Sure there’s lots of cloud based compute and ever faster GPU chips to make CNN and RNN work. But the barrier that we’re up against is latency, particularly in computer vision.
If you want to utilize computer vision on your cell phone or any other edge device (did you ever think of self-driving cars as edge devices) then the data has to make the full round trip from your local camera to the cloud compute and back again before anything can happen.
There are some nifty applications that are just fine with delays of say 200 ms or even longer. Most healthcare applications are fine with that as are chatbots and text/voice apps. Certainly search and ecommerce don’t mind.
But the fact is that those apps are rapidly approaching saturation. Maturity if you’d like a kinder word. They don’t thrill us any longer. Been there, done that. Competing apps are working for incremental share of attention and the economics are starting to work against them. If you’re innovating with this round-trip data model, you’re probably too late.
What everyone really wants to know is what’s the next big thing. What will cause us to become even more attached to our cell phones, or perhaps our smart earbuds or augmented glasses. That thing is most likely to be ‘edge’ or ‘real time computer vision’ (RTCV).
What Can RTCV Do that Regular Computer Vision Can’t
Pretty much any task that relies on movie-like live vision (30 fps, roughly 33 ms response or better) can’t really be addressed by the round-trip data model. Here are just a few: drones, autonomous vehicles, augmented reality, robotics, cashierless checkout, video monitoring for retail theft, monitoring for driver alertness.
Wait a minute you say. All those things currently exist and function. Well yes and no. Everyone’s working on chips to make this faster but there’s a cliff coming in two forms. First, the sort of Moore’s law that applies to this round-trip speed, and second the sheer volume of devices that want to utilize RTCV.
What about 5G? That’s a temporary plug. The fact is that the round-trip data architecture is at some level always going to be inefficient and what we need is a chip that can do RTCV that is sufficiently small enough, cheap enough, and fast enough to live directly on our phone or other edge device.
By the way, if the processing is happening on your phone then the potential for hacking the data stream goes completely away.
AR Enhanced Navigation is Most Likely to be the Killer App
Here’s a screen shot of an app called Phiar, shown by co-founder and CEO Chen Ping Yu at last week’s ‘Inside AI Live’ event. 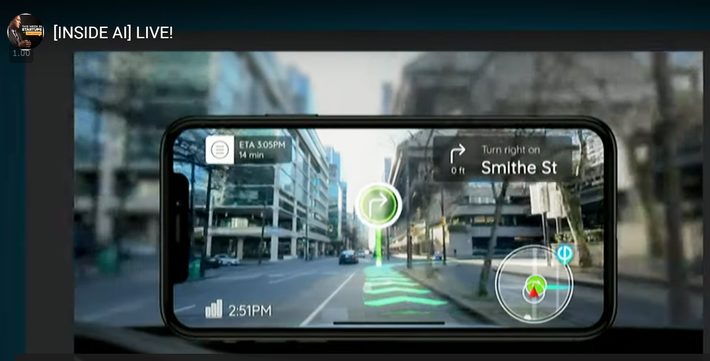
Chen Ping’s point is simple. Since the camera on our phone is most likely already facing forward, why not just overlay the instruction directly on the image AR-style and eliminate the confusion caused by having to glance elsewhere at a more confusing 2D map.
This type of app requires that minimum 30 FPS processing speed (or faster). Essentially AR overlays on real time images is the core of RTCV and you can begin to see the attraction.
The Needed Compute is Just Going Wild
Even without RTCV, our most successful DNNs are winning by using increasingly larger amounts of compute.
Gordon Wilson, CEO of RAIN Neuromorphics used this graph at that same ‘Inside AI Live’ event to illustrate these points. Since our success with AlexNet in 2012 to AlphaGo in 2018, the breakthrough winners have done it with a 300,000x increase in needed compute.
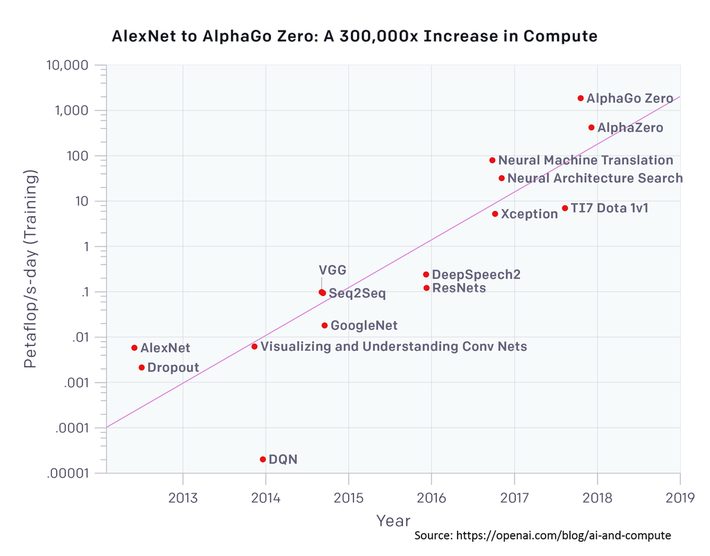
That doubling every 3 ½ months is driven by ever larger DNNs with more neurons processing more features and ever larger datasets. And to be specific, it’s not that our DNNs are just getting deeper with more layers, the real problem is that they need to get wider, with more input neurons corresponding to more features.
What’s Wrong with Simply More and Faster GPUs?
Despite the best efforts of Nvidia, the clear king of GPUs for DNN, the hardware stack needed to train and run computer vision apps is about the size of three or four laptops stacked on top of each other. That’s not going to fit in your phone.
For some really interesting technical reasons that we’ll discuss in our next article, it’s not likely that GPUs are going to cut it for next gen edge processing of computer vision in real time.
The good news is that there are on the order of 100 companies working on AI-specific silicon, ranging from the giants like Nvidia down to a host of startups. Perhaps most interesting is that this app will introduce the era of the neuromorphic chip. More on the details next week.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 1.5 million times.
He can be reached at:
{kind=link}