
The title of the eBook is Dive in Deep Learning. Below I list the content of chapter 16, dealing with the math of deep learning. But the whole book (entirely free) is worth reading. This is an interactive deep learning book with code, math, and discussions. It is based on the NumPy interface.
Authors
- Aston Zhang, Amazon Senior Scientist, UIUC Ph.D.
- Zack C. Lipton, Amazon Scientist, CMU Assistant Professor, UCSD Ph.D.
- Mu Li, Amazon Principal Scientist, CMU Ph.D.
- Alex J. Smola, Amazon VP/Distinguished Scientist, TU Berlin Ph.D.
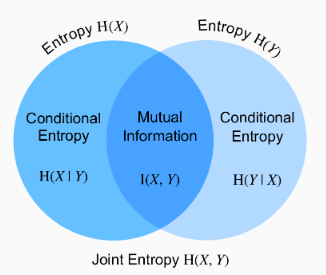
Source: section 9.3 in chapter 16
Below is the content about the math of deep learning (chapter 16.)
1. Linear Algebra
1.1. Geometry of Vectors
1.2. Dot Products and Angles
1.3. Hyperplanes
1.4. Geometry of linear transformations
1.5. Linear Dependence
1.6. Rank
1.7. Invertibility
1.8. Determinant
1.9. Eigendecompositions
1.10. Tensors and Common Linear Algebra Operations
1.11. Common Examples from Linear Algebra
1.12. Expressing in numpy
1.13. Summary
1.14. Exercises
2. Single Variable Calculus
2.1. Differential Calculus
2.2. Rules of Calculus
2.3. Summary
2.4. Exercises
3. Multivariable Calculus
3.1. Generalizing Differentiation
3.2. Geometry of gradients and gradient descent
3.3. A note on mathematical optimization
3.4. Multivariate Chain rule
3.5. The Backpropagation Algorithm
3.6. Hessians
3.7. A Little Matrix Calculus
3.8. Summary
3.9. Exercises
4. Integral Calculus
4.1. Geometric Interpretation
4.2. The Fundamental Theorem of Calculus
4.3. Change of Variables
4.4. A Comment on Sign Conventions
4.5. Multiple Integrals
4.6. Change of Variables in Multiple Integrals
4.7. Summary
4.8. Exercises
5. Random Variables
5.1. Continuous Random Variables
5.2. Summary
5.3. Exercises
6. Maximum Likelihood
6.1. The Philosopy
6.2. A Concrete Example
6.3. Numerical Optimization and the −log-Likelihood
6.4. Maximum likelihood for continuous variables
6.5. Summary
6.6. Exercises
7. Distributions
7.1. Bernoulli
7.2. Discrete Uniform
7.3. Continuous Uniform
7.4. Binomial
7.5. Poisson
7.6. Gaussian
7.7. Summary
7.8. Exercises
8. Naive Bayes
8.1. Optical Character Recognition
8.2. The Probabilistic Model for Classification
8.3. The Naive Bayes Classifier
8.4. Training
8.5. Summary
8.6. Exercises
9. Information Theory
9.1. Information
9.2. Entropy
9.3. Mutual Information
9.4. Kullback–Leibler Divergence
9.5. Cross Entropy
9.6. Summary
9.7. Exercises
Read this material here. For other useful tutorials, follow this link, or check my blogs.
{kind=link}