
This article focuses on the machine learning aspects of the problem, and the use of pattern recognition techniques leading to interesting, new findings about twin primes. Twin primes are prime numbers p such that p + 2 is also prime. For instance, 3 and 5, or 29 and 31. A famous, unsolved and old mathematical conjecture states that there are infinitely many such primes, but a proof still remains elusive to this day. Twin primes are far rarer than primes: there are infinitely more primes than there are twin primes, in the same way that that there are infinitely more integers than there are prime integers.
Here I discuss the results of my experimental math research, based on big data, algorithms, machine learning, and pattern discovery. The level is accessible to all machine learning practitioners. I first discuss my experimentations in section 1, and then how it relates to the twin prime conjecture, in section 2. In section 3, I discuss a generalization. Mathematicians may be interested as well, as it leads to a potential new path to prove this conjecture. But machine learning readers with little time, not curious about the link to the mathematical aspects, can read section 1 and skip section 2.
I do not prove the twin prime conjecture (yet). Rather, based on data analysis, I provide compelling evidence (the strongest I have ever seen), supporting the fact that it is very likely to be true. It is not based on heuristic or probabilistic arguments (unlike this version dating back to around 1920), but on hard counts and strong patterns.
This is not different from analyzing data and finding that smoking is strongly correlated to lung cancer: the relationship may not be causal as there might be confounding factors. In order to prove causality, more than data analysis is needed (in the case of smoking, of course causality has been firmly established long ago.)
1. The Machine Learning Experiment
We start with the following sieve-like algorithm. Let SN = { 1, 2, …, N } be the finite set consisting of the first N strictly positive integers, and p be a prime number. Let Ap be a strictly positive integer, smaller than p. Remove from SN all the elements of the form Ap, p + Ap, 2p + Ap, 3p + Ap, 4p + Ap and so on. After this step, the number of elements left will be very close to N (p – 1) / p = N (1 – 1/p). Now, remove all elements of the form p – Ap, 2p – Ap, 3p – Ap, 4p – Ap and so on. After this step, the number of elements left will be very close to N (1 – 2/p). Now pick up another prime number q and repeat the same procedure. After this step, the number of elements left will be very close to N (1 – 2/p) (1 – 2/q), because p and q are co-prime (because they are prime to begin with.)
If you repeat this step for all prime numbers p between p = 5 and p = M (assuming M is a fixed prime number much smaller than N, and N is extremely large and you let N tends to infinity) you will be left with a number of elements that is still very close to
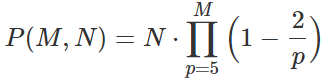
where the product is over prime numbers only.
Let us introduce the following notations:
- S(M, N) is the set left after removing all the specified elements, using the above algorithm, from SN
- C(M, N) is the actual number of elements in S(M, N)
- D(M, N) = P(M, N) – C(M, N)
- R(M, N) = P(M, N) / C(M, N)
In the context of the twin prime conjecture, the issue is that M is a function of N, and the above very good approximation, that is, replacing C(M, N) by P(M, N), is no longer good. More specifically, in that context, M = 6 SQRT(N), and Ap = INT(p/6 + 1/2) where INT is the integer part function. The ratio R(M, N) would still be very close to 1 for most choices of Ap, assuming M is not too large compared to N, unfortunately, Ap = INT(p/6 + 1/2) is one of the very few for which the approximation fails. On the plus side, it is also one of the very few that leads to a smooth, predictable behavior for R(M, N). This is what makes me think it could lead to a proof of the twin prime conjecture. Note that if M is very large, much larger than N, say M = 6N, then C(M, N) = 0 and thus R(M, N) is infinite.
Below is a plot displaying D(M, N) at the top, and R(M, N) at the bottom, on the Y-axis, for N = 400,000 and M between 5 and 3,323 on the X-axis. Only prime values of M are included, and Ap = INT(p/6 + 1/2).
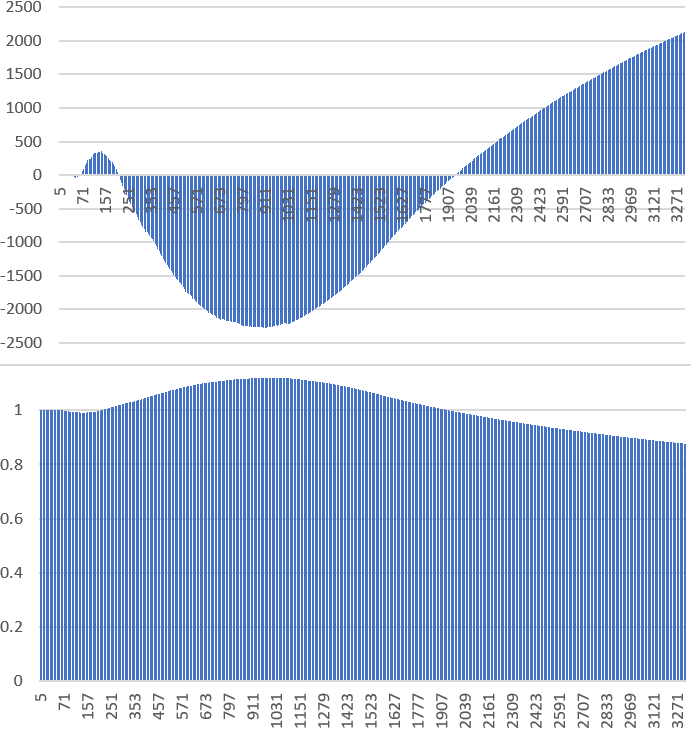
It shows the following patterns:
- For small values of M, R(M, N) is very close to 1.
- Then as M increases, R(M, N) experiences a small dip, followed by a maximum at some location M0 on the X-axis. Then it smoothly decreases well beyond the critical value M1 = 6 SQRT(N). It reaches a minimum at some location M2 (not shown in the plot) followed by a rebound, increasing again until M3 = 6N, where R(M, N) is infinite. The value of M0 is approximately 3 SQRT(N) / 2.
To prove the twin prime conjecture, all is left if the following: proving that M0 < M1 (that is, the peak always takes place before M1, regardless of N) and that R(M0, N), as a function of N, does not grow too fast. It seems the growth is logarithmic, but even if R(M0, N) grows as fast as N / (log N)^3, this is slow enough to prove the twin prime conjecture. Detailed explanations are provided in section 2.
The same patterns are also present if you try other values of N. I tested it for various N‘s, ranging from N = 200 to N = 3,000,000. The higher N, the smoother the curve, the stronger the patterns. It also occurs with some other peculiar choices for Ap, such as Ap = INT(p/2 + 1/2) or Ap = INT(p/3 + 1/2), but not in general, not even for Ap = INT(p/5 + 1/2).
It is surprising that the curve is so smooth, given the fact that we work with prime numbers, which behave somewhat chaotically. There has to be a mechanism that causes this unexpected smoothness. A mechanism that could be the key to proving the twin prime conjecture. More about this in section 2.
2. Connection to the Twin Prime Conjecture
If M = 6 SQRT(N) and Ap = INT(p/6 + 1/2), then the set S(M, N) defined in section 1, contains only elements q such that 6q – 1 and 6q + 1 are twin primes. This fact is easy to prove, see here. It misses a few of the twin primes (the smaller ones) but this is not an issue since we need to prove that S(M, N), as N tends to infinity, contains infinitely many elements. The number of elements in S(M, N) is denoted as C(M, N).
Let us define R1(N) = R(M1, N) and R0(N) = R(M0, N). Here M1 = 6 SQRT(N) and M0 is defined in section 1, just below the plot. To prove the twin prime conjecture, one has to prove that R1(N) < R0(N) and that R0(N) does not grow too fast, as N tends to infinity.
The relationship R1(N) < R0(N) can be written as P(M1, N) / R0(N) < C(M1, N). If the number of twin primes is infinite, then C(M1, N) tends to infinity as N tends to infinity. Thus if P(M1, N) / R0(N) also tends to infinity, that is, if R0(N) / P(M1, N) tends to zero, then it would prove the twin prime conjecture. Note that P(M1, N) is asymptotically equivalent (up to a factor not depending on N) to N / (log M1)^2, that is, to N / (log N)^2. So if R0(N) grows more slowly than (say) N / (log N)^3, it would prove the twin prime conjecture. Empirical evidence suggests that R0(N) grows like log N at most, so it looks promising.
The big challenge here, to prove the twin prime conjecture, is that the observed patterns (found in section 1 and used in the above paragraph), however strong they are, may be very difficult to formally prove. Indeed, my argumentation still leaves open the possibility that there are only a finite number of twin primes: this could happen if R0(N) grows too fast.
The next step to make progress would be to look at small values of N, say N = 100, and try to understand, from a theoretical point of view, what causes the observed patterns. Then try to generalize to any larger N hoping the patterns can be formally explained via a mathematical proof.
The table below summarizes the main results of my computations. It is available here.
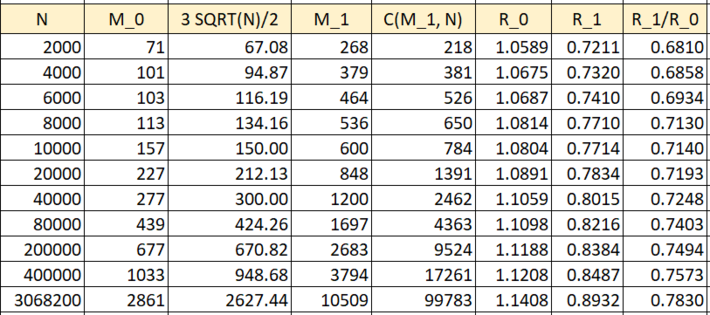
Note that if M1 = 6 SQRT(N), then the set S(M1, N) is a subset of the following sequence: A002822. In particular, if N = 3,068,200, then S(M1, N) contains all the 99,998 elements of A002822 (mapping to the first 99,998 twin primes if you ignore {3, 5}) up to 3,068,165, except for the first 215 entries. Thus C(M1, N) = 99,998 – 215 = 99,783 as shown in the above table. If M1 < 6 SQRT(N), then S(M1, N) not only misses more elements of A002822, but it also includes elements that are not in A002822. Thus the reason to call M1 = 6 SQRT(N) the critical point. The last element q = 3,068,165 corresponds to the twin primes 6q – 1 = 18,408,989 and 6q + 1 = 18,408,991. See also here.
3. Generalization
The concepts discussed here also apply to cousin primes, sexy primes, prime numbers, and other related-prime numbers. This section is still under construction. In the meanwhile, I invite you to check my latest update on this topic, on MathOverflow, here.
To receive a weekly digest of our new articles, subscribe to our newsletter, here.
About the author: Vincent Granville is a data science pioneer, mathematician, book author (Wiley), patent owner, former post-doc at Cambridge University, former VC-funded executive, with 20+ years of corporate experience including CNET, NBC, Visa, Wells Fargo, Microsoft, eBay. Vincent is also self-publisher at DataShaping.com, and founded and co-founded a few start-ups, including one with a successful exit (Data Science Central acquired by Tech Target). You can access Vincent’s articles and books, here. A selection of the most recent ones can be found on vgranville.com.
{kind=link}