
This tutorial describes theory and practical application of Support Vector Machines (SVM) with R code. It’s a popular supervised learning algorithm (i.e. classify or predict target variable). It works both for classification and regression problems. It’s one of the sought-after machine learning algorithm that is widely used in data science competitions.

What is Support Vector Machine?
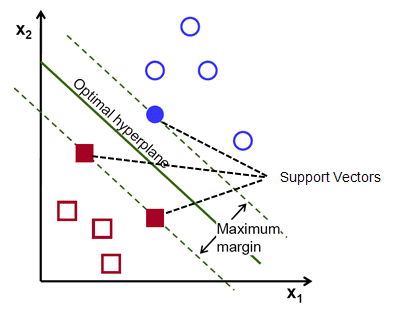
The main idea of support vector machine is to find the optimal hyperplane (line in 2D, plane in 3D and hyperplane in more than 3 dimensions) which maximizes the margin between two classes. In this case, two classes are red and blue balls. In layman’s term, it is finding the optimal separating boundary to separate two classes (events and non-events).
Why Hyperplane?
Hyperplane is just a line in 2D and plane in 3D. In higher dimensions (more than 3D), it’s called hyperplane. SVM help us to find a hyperplane (or separating boundary) that can separate two classes (red and blue dots).
What is Margin?
It is the distance between the hyperplane and the closest data point. If we double it, it would be equal to the margin.
Objective : Maximize the margin between two categories
How to find the optimal hyperplane?
In your dataset, select two hyperplanes which separate the data with no points between them and maximize the distance between these two hyperplanes. The distance here is ‘margin’.
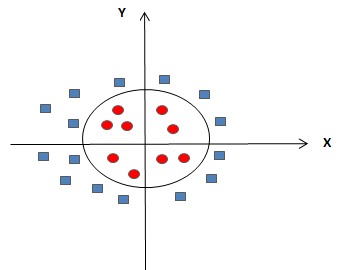 |
| SVM : Nonlinear Separable Data |
%20from%20Scratch%20in%20R){kind=link}