

Kubernetes is a technology that allows us to isolate an application. That is good but how can we scale this? Of course, we should create new containers.
But, how many containers should we have at the same time? How many servers should be involved? Who will monitor all nodes to balance loading and redirect queries to less loaded nodes? Also, how can we update our app without stopping? The answer is Kubernetes.
What is Kubernetes?
Kubernetes is an open-source container-orchestration system for automating application deployment, scaling, and management. It was originally designed by Google and is now maintained by the Cloud Native Computing Foundation.
Kubernetes manages out containers giving us a high-level API to control the whole system. What does this mean for the developer? This means that he does not need to worry about the number of nodes, about exactly where the containers are launched, or how they interact. He doesn’t have to deal with hardware optimization or worry about nodes that might be malfunctioning.
The other great news is that we have an abstract layer from a cloud solution provider (CSP). Of course, different CSPs have different API, but Kubernetes will always be the same. So you can easily change the provider to get better tariffs.
Kubernetes architecture
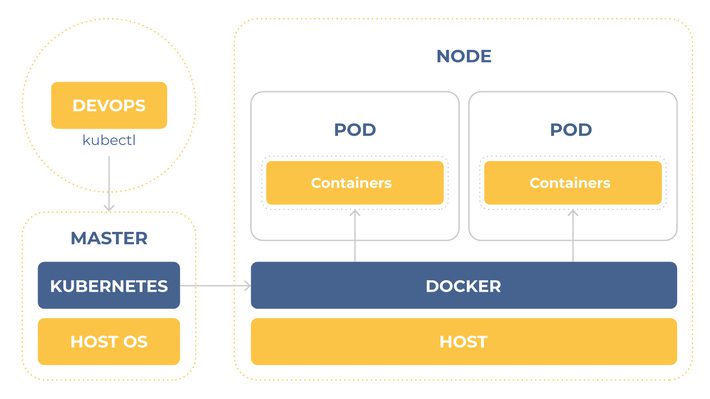
Kubernetes have a Master node. This node manages all others. Master consists of: etcd, API Server, Controller Manager, Scheduler.
Master node
etcd
It stores the configuration information which can be used by each of the nodes in the cluster. It is a high availability key-value store that can be distributed among multiple nodes. It is accessible only by the Kubernetes API server as it may have some sensitive information. It is a distributed key-value store that is accessible to all.
API Server
Kubernetes is an API server which provides all the operation on the cluster using the API. API server implements an interface, which means different tools and libraries can readily communicate with it. Kubeconfig is a package along with the server-side tools that can be used for communication. It exposes the Kubernetes API.
Controller Manager
This component is responsible for most of the collectors that regulate the state of the cluster and perform a task. In general, it can be considered as a daemon that runs in a non-terminating loop and is responsible for collecting and sending information to the API server. It works toward getting the shared state of the cluster and then make changes to bring the current status of the server to the desired state. The key controllers are the replication controller, endpoint controller, namespace controller, and service account controller. The controller manager runs different kinds of controllers to handle nodes, endpoints, etc.
Scheduler
This is one of the key components of Kubernetes master. It is a service in master responsible for distributing the workload. It is responsible for tracking the utilization of working load on cluster nodes and then placing the workload on which resources are available and accept the workload. In other words, this is the mechanism responsible for allocating pods to available nodes. The scheduler is responsible for workload utilization and allocating pod to a new node.
Slave node
The minimum runnable entity is called Pod. A pod is a group of containers that use the same resources and have common directories. Running a single container per pod is a common practice. Why the minimum unit is pod but not a container? For those cases where, for example, two containers need to share access to the same data warehouse, or if they are connected using the interprocess communication technique, or if they are closely connected for some other reason.
The other reason for using pod is that we can use not only Docker containers but also other containerization techniques as Rkt..
The next entity we need is a Service. Kubernetes services act as access points to pods that provide the same functionality as these pods. Services perform the solution of difficult tasks of working with pods and balancing the load between them.
But how service will recognize what Pods should it serve? Labels is a key-value pair that allow us to filter entities. Each pod can have more than one label. For example, microservice name and version. You can define a target filter for service or deployment strategy to define responsibilities. The service will redirect queries to the less loaded node and can set up new pods in one node if others will fall.
But what about Deployment? Can we achieve a zero stop time when updating our code? And what should we do if our code will have a fatal error? Just mention that our app can be distributed across a thousand nodes and operates thousands of containers. That is why the Deployment component exists. It allows as to update each node in zero-stop time mode and easily check out to the previous version of our app. The best part of this is that we can adjust all aspects of this process. You also can configure the CI process.
The other good thing is that Kubernetes has a special pod kube-dns, that works as a default DNS server. One of the important features of kube-dns is the fact that this sub creates a DNS record for each cluster service. This means that when we create a service with name my-service, it is assigned an IP address. An entry is made in kube-dns with information about the name and IP address of the service. This allows all submit to convert an address of the form http:// my-service to an IP address.
Use-cases
Microservices
Microservices is an important trend in software development that allows the application to handle a really huge amount of requests by horizontal scaling. Kubernetes provides fault tolerance and high availability. And configured CI process easily updates thousand of nodes.
Machine learning
Machine learning techniques are now widely used to solve real-life problems. Yet, the process of building an effective AI model and using it in production is complicated and time-consuming. Therefore, many companies would like to simplify this process and make the life of data scientists or ML engineers easier by introducing a toolkit to speed up the whole process. In this way, the number of operations necessary to deploy such an app will be significantly reduced, shortening the app’s time-to-market. In this scenario, enterprises can harness the power of Kubernetes, as all the calculations necessary to train the ML model are performed inside the K8s cluster. The data scientist or ML engineer will only need to clean the data and write the code. The rest will be handled by a toolkit based on Kubernetes. Such toolkits are already available on the market: Kubeflow by Google.
Heavy computing and High-performance computing
Anyone who has worked with Docker can appreciate the enormous gains in efficiency achievable with containers. But, sometimes we need to perform really complicated operations that require something more than only one machine. There are 2 ways: vertical and horizontal scaling. Vertical scaling is too costly and restricted by tech evolution, but horizontal requires something that able to orchestrate all containers in different machines. Kubernetes can help us in this field.
Conclusion
Kubernetes is a powerful orchestrator tool. It gives you a lot of abilities, such as easy zero-stop-time app updates, fault tolerance control, balance loading and communication configuration to perform such great things as heavy computing and high load processing. In addition, configuring Kubernetes, but not an infrastructure (IaaS) you will be able to easily change infrastructure provider without losing your progress.
{kind=link}