
A debate rages on page one of Hacker News about the merits of the world’s most downloaded time-series library. Facebook’s Prophet package aims to provide a simple, automated approach to the prediction of a large number of different time series. The package employs an easily interpreted, three-component additive model whose Bayesian posterior is sampled using STAN. In contrast to some other approaches, the user of Prophet might hope for good performance without tweaking a lot of parameters. Instead, hyper-parameters control how likely those parameters are a priori, and the Bayesian sampling tries to sort things out when data arrives.
Judged by popularity, this is surely a good idea. Facebook’s prophet package has been downloaded 13,698,928 times according to pepy. It tops the charts, or at least the one I compiled here where hundreds of Python time series packages were ranked by monthly downloads. Download numbers are easily gamed and deceptive but nonetheless, the Prophet package is surely the most popular standalone Python library for automated time series analysis.
Prophet’s Claims, and Lukewarm Reviews
The funny thing is though, that if you poke around a little you’ll quickly come to the conclusion that few people who have taken the trouble to assess Prophet’s accuracy are gushing about its performance. The article by Hideaki Hayashi is somewhat typical, insofar as it tries to say nice things but struggles. Yahashi notes that out-of-the-box, “Prophet is showing a reasonable seasonal trend unlike auto.arima, even though the absolute values are kind of off from the actual 2007 data.” However, in the same breath, the author observes that telling ARIMA to include a yearly cycle turns the tables. With that hint, ARIMA easily beats prophet in accuracy — at least on the one example he looked at.
Professor Nikolaos Kourentzes benchmarked prophet against several other R packages — namely the forecast package and the smooth package which you may have used, and also mapa and thief. His results are written up in this article which uses the M3 dataset and mean absolute scaled error (link). His tone is more unsparing. “Prophet performs very poorly… my concern is not that it is not ranking first, but that at best it is almost 16% worse than exponential smoothing (and at worst almost 44%!).”
What’s up with the top dog?
Is this a case of Facebook’s brand and marketing catapulting a mediocre algorithm to prominence? Or perhaps it is the echo-chamber effect (lots of people writing how-to articles on medium?). Let’s not be quick to judge. Perhaps those yet to be impressed by Prophet are not playing to its strengths, and those are listed on Facebook’s website. The software is good for “the business forecast tasks we have encountered at Facebook” and that, according to the site, means hourly, daily or weekly observations with strong multiple seasonalities.
In addition, Prophet is designed to deal with holidays known in advance, missing observations and large outliers. It is also designed to cope with series that undergo regime changes, such as a product launch, and face natural limits, due to product-market saturation. These effects might not have been well captured by other approaches. It doesn’t seem unreasonable then, to imagine that Prophet could work well on a domain it was built for. It is presumably under these conditions that the claim can be made, as it is on a 2017 Facebook blog post, that “Prophet’s default settings produce forecasts that are often [as] accurate as those produced by skilled forecasters, with much less effort.’’
The claim is pretty bold — as bold as Prophet itself, as we shall see. Not only does the software work better than benchmarks (though none are explicitly provided) but also human experts. Presumably, those human experts are able to use competing software in addition to drawing lines by hand … but what were they using, one might wonder? The same blog post suggests “as far as we can tell there are few open-source software packages for forecasting in Python.”
Here I’m sympathetic, conscious of the officious policing of firewalls that can occur at large companies. And that statement was made in 2017, I believe, though even accounting for the date, the lack of objective benchmarking strikes me as a tad convenient. My listing of Python time series packages is fairly long, as noted, though of course many have come along in the last three years.
Still, it shouldn’t be too hard to find something to test Prophet against, should it? A recent note suggests that prophet performs well in a commercial setting, but — you guessed it — does not explicitly provide a comparison against other Python packages. Nor here. An article by Navratil Kolkova is quite favorable too (pdf). The author notes that the results are relatively easy to interpret — which is certainly true. But was performance compared to anything? I’ll let you guess.
You will have surmised by now that the original Prophet paper, Forecasting at Scale by Taylor and Letham, is also blissfully comparison free (pdf). The article appears, slightly modified, in volume 72 of the American Statistician, 2018, so perhaps my expectations are unreasonable (pdf). The Prophet methodology is plausible, it must be said, and the article has been cited 259 times. The authors explain the tradeoffs well, and anyone looking to use the software will understand that this is, at heart, a low pass filter. You get what comes with that.
Objectively measured hard-to-beat accuracy might not be part of that bargain. As noted, I wasn’t the only person dying of curiosity on the matter of whether the world’s number one Python time series prediction library can actually predict stuff. A paper considering Prophet by Jung, Kim, Kwak and Park comes with the title A Worrying Analysis of Probabilistic Time-series Models for Sales Forecasting (pdf). As the spoiler suggests, things aren’t looking rosy. The authors list Facebook’s Prophet as the worst performing of all algorithms tested. Oh boy.
Ah, you object, but under what metric? Maybe the scoring rule used was unfair and not well suited to sales of Facebook portals? That may be, but according to those authors Prophet was the worst uniformly across all metrics — last in every race. Those criteria included RMSE and MAPE as you would expect, but also mean normalized quantile loss where (one might have hoped) the Bayesian approach could yield better distributional prediction than alternatives. The author’s explanation is, I think, worth reproducing in full.
The patterns of the time series are complicated and change dynamically over time, but Prophet follows such changes only with the trend changing. The seasonality prior scale is not effective, while higher trend prior scale shows better performance. There exist some seasonality patterns in the EC dataset, but these patterns are not consistent neither smooth. Since Prophet does not directly consider the recent data points unlike other models, this can severely hurts performance when prior assumptions do not fit.
In recent times, attention has turned to prediction of COVID-19 rather than product cycles. But again, Papanstefanopoulos, Lindardatos and Kotsiantis (pdf) find Prophet underperforms ARIMA. Stick to TBATS, their results advise. There’s no love either from Vishvesh Shah in his master’s thesis comparing SARIMA, Holt-Winters, LSTM and Prophet. Therein, Prophet is the least likely to perform the best on any given time series task. LSTM’s won out twice as often, and both were soundly beaten by the tried and tested SARIMA.
Woes continue for Prophet in the paper Cash Flow prediction: MLP and LSTM compared to ARIMA and Prophet by Weytjens, Lohmann and Kleinsteuber (download). I’ve included their summary table. Compared to the other papers is relatively favorable — as far as a head to head with ARIMA is concerned. However as you can see, neural networks easily best Prophet and ARIMA — at least in their setup.
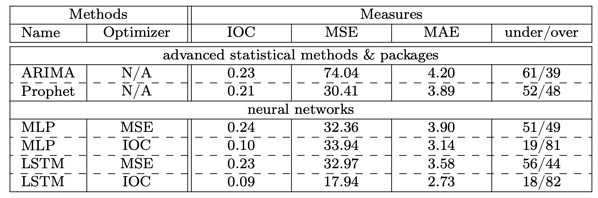
Is there a sweet spot for Prophet, somewhere where data hungry methods can’t trounce it, yet classical time series isn’t so strong? Determined to find a paper that compared Prophet favorably to anything, I finally located Samal, Babu, Das and Acharaya’s paper titled Time Series based Air Pollution Forecasting using SARIMA and Prophet Model (paper). Air pollution is a good choice, I feel, since multiple cycles might confuse some competing approaches. The authors find that Prophet wins, hoorah! But I’m not convinced, as this seems to be a relatively small sample with one absolutely enormous spike in the middle of the time series — seeming to make the RMSE something of a lottery.
That’s what worries me about Prophet. The smattering of favorable reviews all seem to involve one or two time series. I’m not sure what the FDA would think about that. The only wins seem to occur against relatively weak fields, usually two-horse races between ARIMA and Prophet. That seems to be the race that Prophet can win sometimes, as suggested by Cayir, Kozan and Yenidogan in Bitcoin Forecasting Using ARIMA and PROPHET (download). It should be noted that the authors perform manual pre-processing and feature selection, so arguably this isn’t forecasting at scale but we’ll call it a Prophet win.
Similarly, in the almost perfectly seasonal Kuwait electricity load time series studied by Almazrouee et al (paper) Prophet scores a victory over Holt-Winters. Just one time series there, however, and I would have thought auto-arima would be a better benchmark. A post by Michael Grogan (article) where passenger traffic is studied also helps highlight some of Prophet’s strengths — but again the win over ARIMA is for one time series only. As soon as we get to studies involving numerous time series, as with Al Yazdani’s use of FRED data (repo) or with Fred Viole’s comparison to NNS-ARMA back in 2017 (post), Prophet get’s stomped.
Taking Prophet for a Spin
I began writing this post because I was working on integrating Prophet into a Python package I call time machines, which is my attempt to remove some ceremony from the use of forecasting packages. These power some bots that the prediction network (explained at www.microprediction.com if you are interested). How could I not include the most popular time series package?
I hope you interpret this post as nothing more than an attempt to understand the quizzical performance results, without denying the possible utility of Prophet or its strengths (if nothing else it might be classified as a change-point detection package). I mean seriously, can Prophet really be all that bad? At minimum, all those who downloaded Prophet are casting a vote for interpretability, scalability and good documentation — but perhaps accuracy as well in a manner that is hard to grasp quantitatively.
Let’s be clear about one thing, nobody has a right to complain about open-source, freely distributed software that doesn’t live up to their expectations. They are free to make pull requests that improve it, and I hope that continues to be the case for Prophet. Also, I offer below what I hope is a simple, concrete way to improve forecasts made using Prophet.
And today I want to determine if there is something we can see with our eyes which argues for Prophet. Let’s brush aside the naysayers, and to some extent the error metrics, and give it a really good run over hundreds of different time series with diverse sources (you can browse the live streams I am referring too). Let’s also not fall into the trap of looking at the out of sample data while visually assessing Prophet — that would be unfair. I want to structure this so that you first see the data the way Prophet would — only the data you would train it on.
I happened to start with wait times at a hospital so we’ll run with that first. You can click through that link to see the nature of that time series but, as you can imagine, there is quite a lot of predictability to it. The data is sampled every 15 minutes, and that in theory plays to Prophet’s strengths. For those not familiar with Prophet, the following steps are undertaken:
- We marshal the time series, including timestamps and exogenous variables into a pd.DataFrame df say.
- We call m.fit(df) after each and every data point arrives, where m is a previously instantiated Prophet model. There is no alternative, as there is no notion of “advancing” a Prophet model without refit.
- We make a “future dataframe” called forecast say, that has k extra rows, holding the times when we want predictions to be made and also known-in-advance exogenous variables.
- We call m.predict(forecast) to populate the term structure of predictions and confidence intervals.
- We call m.plot(forecast) and voila!
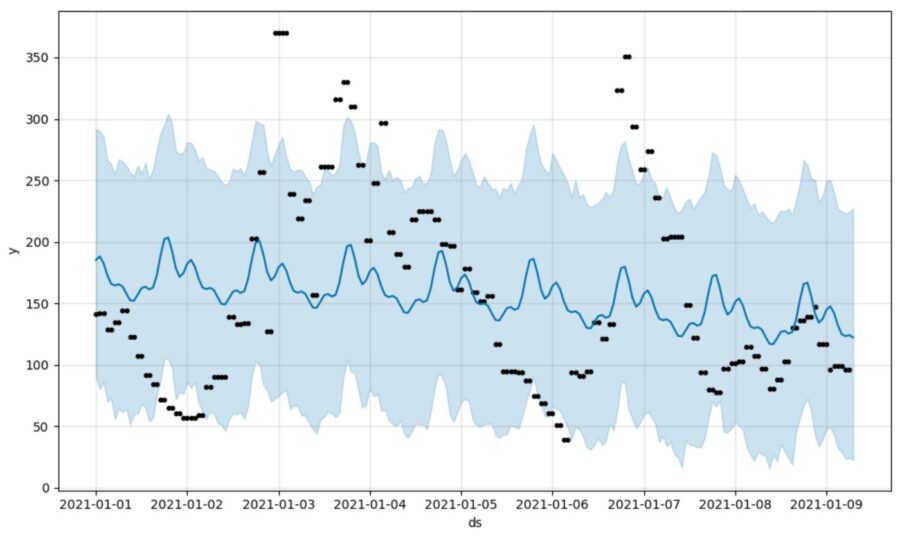
Well, that’s what you are supposed to do but personally, I’d rather gnaw my own leg off that do that every single time. I wrote a simple functional interface here where you can use one line of code instead, if you wish (it is explained in the README.md).
However the Prophet interface as provided is well documented and easy enough to use. The response to GitHub issues is also excellent — much better than the wait times at the ER we are plotting. The style is easy to follow — albeit rooted in an offline, tabular mode of work that isn’t the most convenient for deployment. Most will be familiar with it and not everyone will feel the need to mutter under their breathe about the wisdom of including pandas in a central role. The ceremony isn’t too bad, really.
These are important thumbs-ups for an open source project.
So what do we think of the output? The plot you see looks pretty, although the blue shading is a little seductive. Imagine all the other ways to paint that in and you start to realize a few of them might be quite a bit more convincing. Yes you can imagine my disappointment when, out-of-the-box, Prophet was beaten soundly by a “take the last value” forecast but probably that was a tad unlucky (even if it did send me scurrying to google, to see if anyone else had a similar experience).
Let’s try not to be too harsh. Firstly, any automated approach will come up against the no free lunch theorem sooner or later, to the extent that you buy that. Moreover as noted, one-step ahead forecasting isn’t exactly the raison-d’etre of Prophet. It is more for medium-to longer-term forecasting, presumably, where pronounced patterns persist and one must rail against serially correlated noise and regime changes. When I increased the lookahead (k>1 steps to forecast), the out-of-the-box Facebook Prophet did start to add value — as judged by root mean square error.
So Facebook has bequeathed the world something useful, potentially. Sure, this might not be everyone’s idea of automatic time series forecasting if a last value cache can beat it sometimes and you have to chaperone it around such cases, but I only supplied it with a rolling window of 200 data points (~2 days) initially which might not be “fair”. You can see from the picture above it is somewhat shy about the daily effect, and who wouldn’t be after two days? When we include 400 trailing data points, Reverend Bayes — the ghost in the machine — says “yup, I see something more.” Then, you get a better tracking forecast.
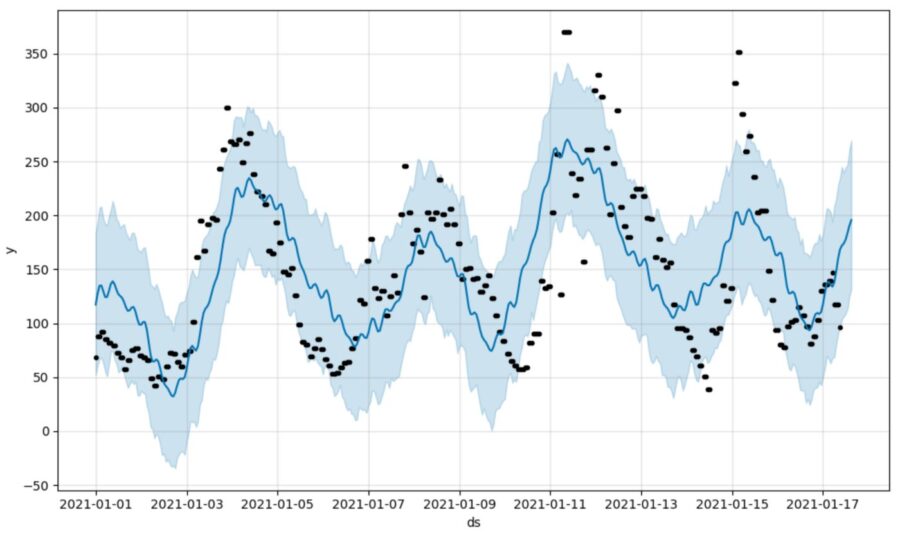
Unfortunately, this picture still doesn’t scream at me that Prophet is doing a good job — depending on your purpose. Look at the serial correlation in the model residuals, for one thing. What the picture really does is help us understand why Prophet might do a consistently bad job of predicting some real world time series (as judged by error metrics).
The Prophet generative model also suggests that where cycles occur which are rhythmic but not precisely so, things might go wrong. In these instances, it seems to me that that Prophet — which is actually a simple combination of three terms — will make some really courageous predictions.
What’s Going On?
Perhaps we start by looking at some of the more bold Prophet predictions.
In this discussion we need to redefine “bold”, as compared to what you’re probably accustomed to if you use, say, Kalman filters, DLMs or the like. Of course, with any time series model, there will be predictions we think push the upper or lower envelopes — but with Prophet we go further. There are really strong views. For example, what would you think the next number in this sequence will be?
69, 55, 55, 53, 53, 41, 41, 28, 28, 35,…
Is 181 the first number that comes to mind? Me neither, and that’s where one starts to wonder if the Prophet approach is salvageable from the standpoint of error metrics — notwithstanding the anecdotal success people have apparently had using it to forecast sales (you know, compared to those “expert” forecasters).
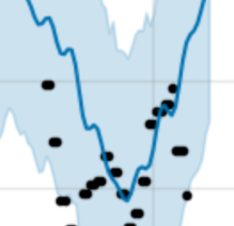
I guess nobody gets to be a famous Prophet by making mundane safe predictions, but at minimum, one should be aware of some Prophet mechanics. For instance, the last 20% of data points are not used to estimate the trend component. Did you know that? Did you expect that? I didn’t. Let it sink in.
As we zoom in on the left, we see the data takes a turn but Prophet sails on — perhaps because of this particular quirk but also because Mr. Markov Chain Monte Carlo doesn’t necessarily have enough possibilities to explore. In some real world applications, those data points are going for a bonafide walk. It might not be noise obscuring a cycle, but rather real, predictable falloff in hospital wait times. It is just that today’s falloff doesn’t happen to occur at precisely the same time as yesterday.
For this reason, I’d be shy of asserting that this methodology will be accurate in the presence of overlapping cycles, even if it can sometimes do quite well. The generative model suggests, on the contrary, some brittleness. Needless to say, those time series that are actually hard to predict (say financial price time series) are probably going to provide an even stiffer challenge to Prophet — not that I imagine anyone is about to make a firm two-sided market in bitcoin based on what comes out of Prophet. Not anyone who has read this far, anyway.
Now it isn’t a bad thing to try to ignore noise. The issue, however, is that a slightly different generative model might also ignore noise pretty well, but would have woken up the Reverand Bayes (or Laplace maybe) at some point when all the model residuals were on the same side for an extended run. Prophet doesn’t care. Prophet is a honey-badger. Prophet carries on. Prophet is, I suggest, for when you view the projections from the furthest seat of the conference room, and you’re the impatient non-technical boss, and you just want to know if beanie babies are selling or not.
But even then I’m a little skeptical that Prophet is going to do a better job of dealing with noise than some other filtering approaches, because Prophet assumes gaussian measurement errors — which is pretty much giving up the battle before you start. Asking Bayes to save you from chasing outliers while you tell it they are gaussian is like asking a dog not to chase its tail.
Unless … you also constrain it in other rather draconian ways. To do so can come at a price. To illustrate, the y-axis shows travel times on a section of the New Jersey turnpike. You can see what I mean about the difficulty of applying Bayes Rule, when your model spans a tiny fraction of the space of all possible time series. No human expert would provide the same extrapolation, which I think you’ll agree is pretty darn dreadful.
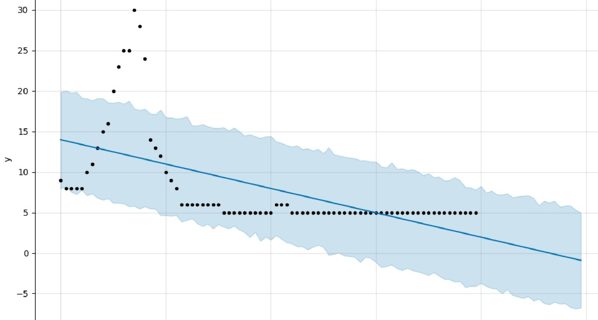
Trajectories can exhibit cyclical patterns and yet, on balance, this probably fails the “six-year-old daughter test”. So, too, the following example where first graders with markers would do a better job at extrapolation. Like Prophet, I’ve made you blind to the source of this data but rest assured these are real, instrumented data points.
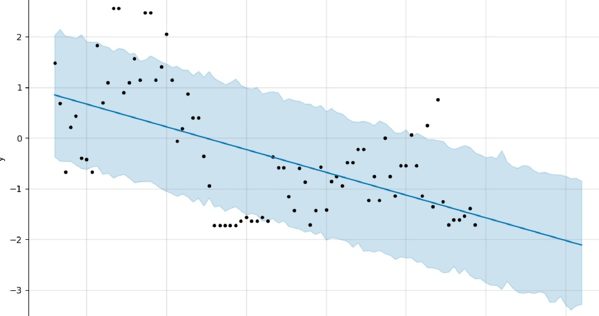
How much would you really wager that this is going to head to -2? I’ll take the other side in size if that’s really your median, since the average of my two six-year-old daughters’ estimates comes to -1.2, approximately. Here I’m sorry not to be more web-adept, because a button toggling the blue shading would probably remove some bias. Try to remove it from your visual calculation, if you can.
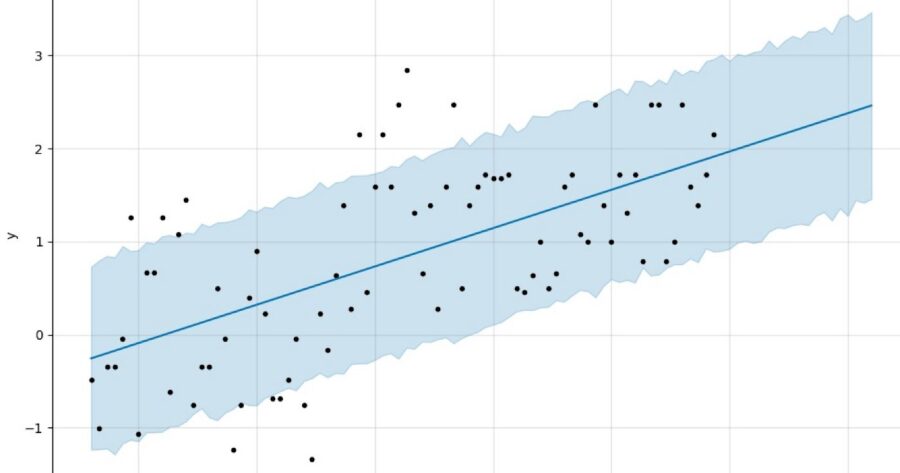
Similarly, while some might buy a consistent trend in the plot below, I think it is safer (and pragmatic from the perspective of minimizing squared error over many similar time series) to suggest that we are likely going to be in the vicinity of 1.5–2.0, not 2.5, in the near future. Perhaps some of the longer-term trend can enter the picture, but shrunk towards zero.
Prophet isn’t shy though.
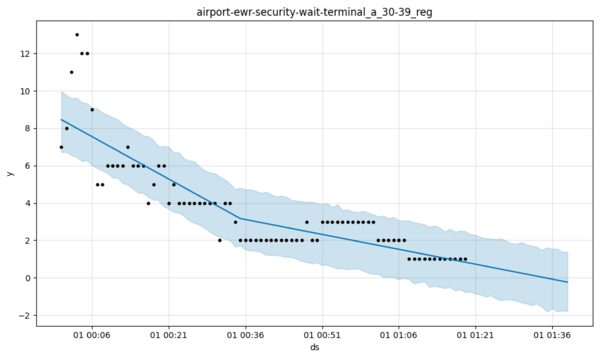
In a similar vein, do you expect the wait time at Newark Airport to go negative any time soon? Now we’re reinserting our generalized intelligence and that seems unfair but even so, if a time series has never, ever gone below a certain level, isn’t it pretty cheeky to predict that it will, with high probability, do precisely that? That might be an easy way to improve the generative model just a tad.
Notice in the plot below that, in Prophet’s defense, it has tried to find the change-point. However the lack of flexibility with trend is the issue. Here I wager it will get beaten by the last value cache more often than not, never mind something more sophisticated. A log transform might not save it, nor a longer horizon.
Again, it is easy to criticize and hard to implement. These examples are, as noted, just my own wrestling with the methodology in an effort to understand how it might be improved. In the Prophet generative model, there are not too many levers to pull, really (and those that exist can, perhaps, over-identify structure that isn’t really there, perhaps, if there is no other recourse for Bayes Rule).
One wouldn’t want to ruin Prophet in the process of improving it. The relatively fast model fitting is essential, since this has to occur every time a new data point arrives (there is no state, or notion of carrying forward the Prophet model from one point to the next). One of the benefits of a relatively simple parsimonious model is the ability to sail through noise. Here it is doing a good job, no?
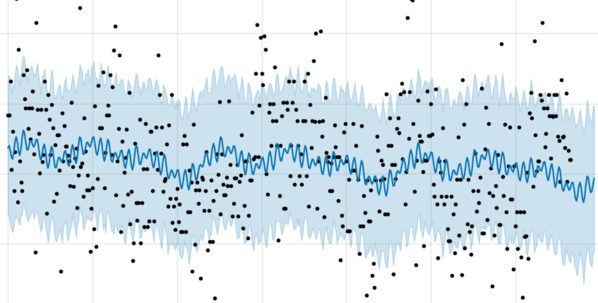
It may seem like I’m nit-picking here, but the imagination of sinusoidal structure you see above is going to chip away at the chances of a low root mean square error — as compared to something else closer to a martingale. To put a more positive spin on this, one might argue that if you only care about the overall picture — say panned out — then you might be indifferent to the wiggles that contribute to least square error but don’t harm your insight. I’m not sure how to really turn that vague defense of Prophet into a more formal one, however.
I’m also concerned that Prophet will process time series in a way that makes for predictable “anchor points,” if we allow ourselves to relax the idea that it is trying to create point estimates judged by some scoring rule — a task it apparently isn’t naturally succeeding at. If you are making markets, you don’t want that. But one way to defend Prophet theoretically — and here I’m just throwing up ideas — is to judge it based on how well it helps subsequent processing (that is to say, some metric applied to Prophet used in conjunction with some other method, presumably one that fixes up the serially correlated errors, and so forth, or at minimum uses it for change-point detection).
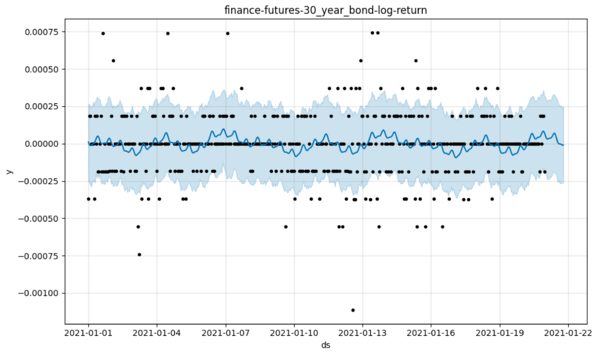
However, it isn’t just the predictability of those wiggles but also their magnitude that concerns me. Here’s a real market time series where we look at ticks up and down for the 30-yr bond. I would want to shrink those predictions towards zero, and time series filters designed for that purpose do precisely that. But I admit the picture isn’t proof that Prophet is inherently unworkable for microstructure — just a cause for concern. A fair analysis would use the full posterior.
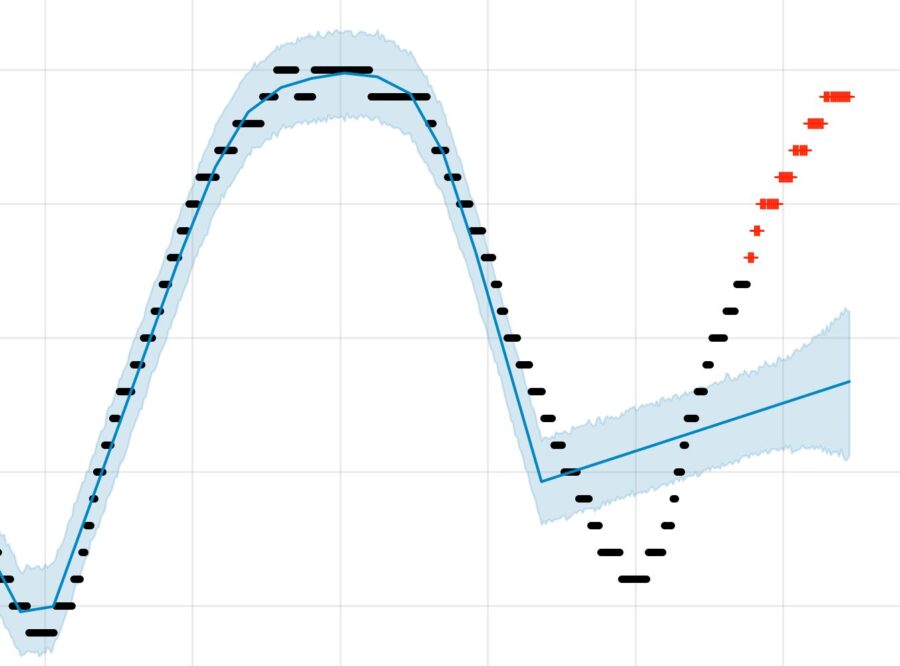
Setting aside the fact that few will be tempted to use Prophet for a market making mid price anyway, you can also see why it might not be topping the league tables for easier-to-predict things either, no matter what metric is applied. With only trend to play with, there are going to be plenty of interpolations and extrapolations that beg the question. In the time series below, Prophet doesn’t get a prize here for predicting a trend inside any of the three seeming regimes — any model given a hundred data points or more should do okay. It does make a bold extrapolation, however, as you can see.
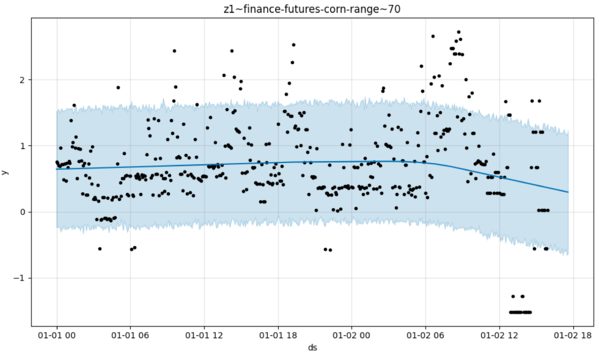
Sometimes those guesses will be right, but I’d be inclined to treat Prophet as a signal generator at best, which is to say we could use it as a feature. Out of the box, my gut says this model will effect poorly calibrated estimates (i.e. estimates that could easily be improved by some meta-model analyzing its proclivity to make mistakes). For instance, here is Prophet seemingly failing to discern any signal at all in the ranges taken by the price of corn over fixed intervals (a measure of volatility). But there is a pattern, unless my eyes deceive me.
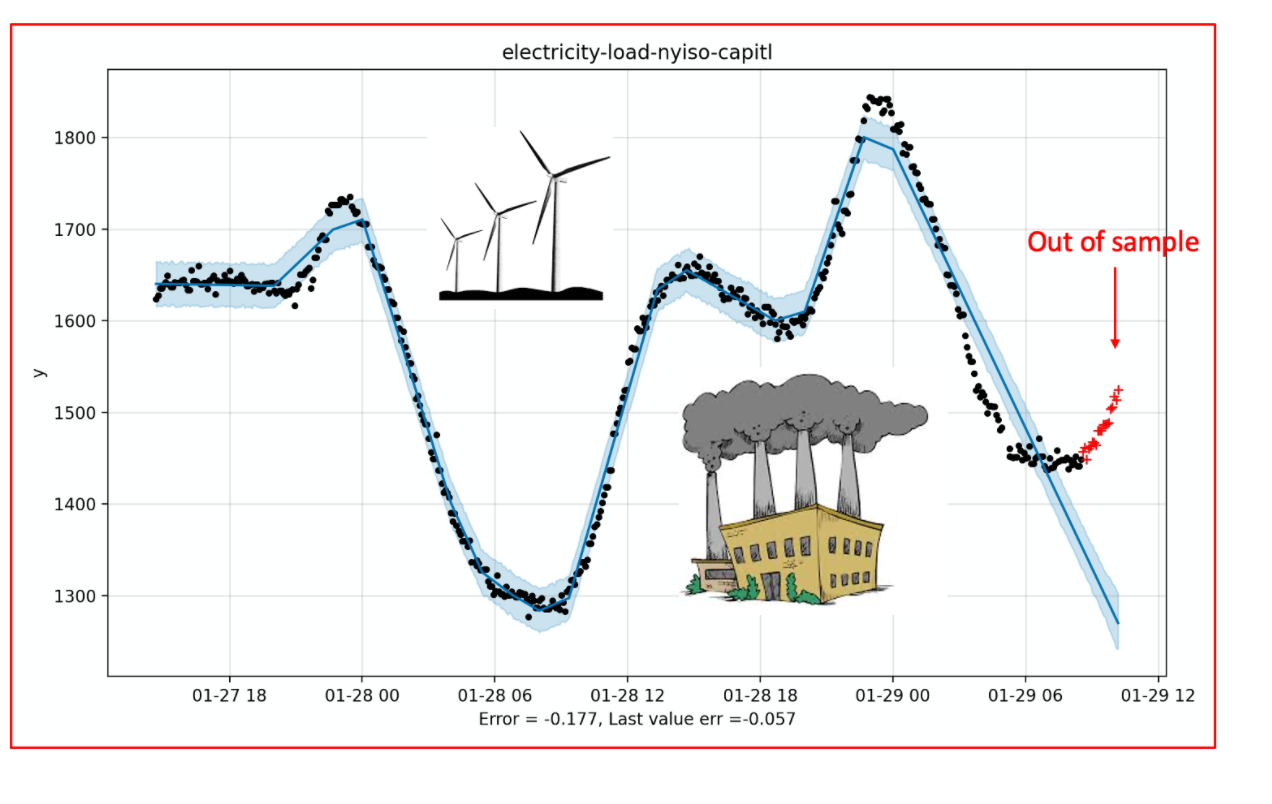
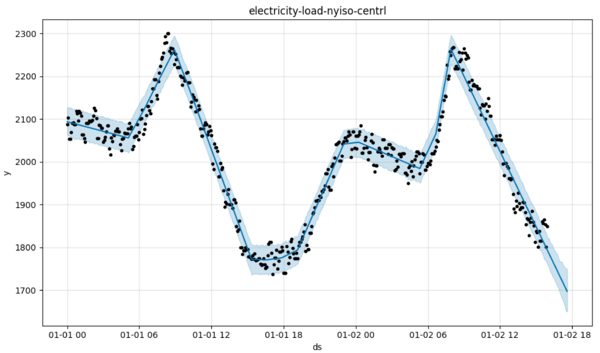
Prophet needs regularity, and sometimes it gets it. The best possible scenario, it would seem, is one in which a quantity follows a piecewise linear path. In nature, one has to hunt and peck to find them, but it isn’t impossible. Hey, check out New York’s electricity production!
And yet even here we see the flaw in Prophet. Its basis manages to span the space in this example — fortuitously one might think — but when compared to other approaches (such as state space models) it is placing a really big bet on certain types of path — such as that straight line continuing. Glance at the cover image of this post for the end of a similar story.
In contrast, if you model with gaussian processes, Kalman filters or the like, you are also performing a Bayesian calculation but doing it over a much larger space of possibilities. That’s why, in my humble prior opinion pending a more formal analysis, Prophet’s numbers aren’t likely to be very impressive.

In other domains, the generative model paucity is — I would suggest — glaringly obvious. For example, if you wanted to model traffic flow, or the rise and fall and rise of epidemics, just about any sensible generative model would be able to trace out bursty behavior, should that be required of it by the model.
I completely accept that this might not have been the motivation for Prophet. And on the flip side, perhaps there is a relatively easy way to improve the software. Even a one-parameter family might be able to model the length of a queue, if push came to shove (which it sometimes does in New York City traffic). The underlying MCMC can handle anything (thanks Professor Gelman) so why not?
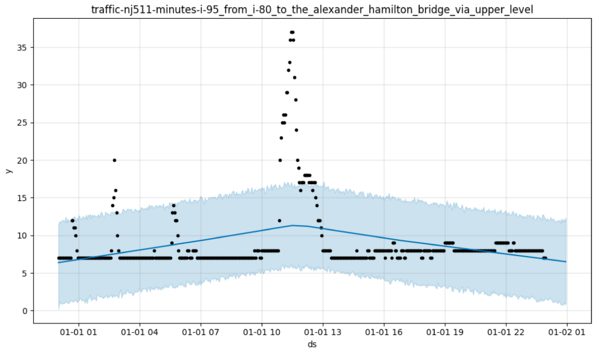
You’d want Prophet to be able to model travel times between I-80 and the Alexander Hamilton bridge, for instance, whereas at present Prophet doesn’t cope with that — unless I have some horrible bug in my code. The generative model doesn’t want to discern the phenomenon that is seemingly evident in the data. Just imagine how bad the out-of-sample performance of this model is going to be compared to, say, an ARIMA with change-point detection or even a Kalman filter.
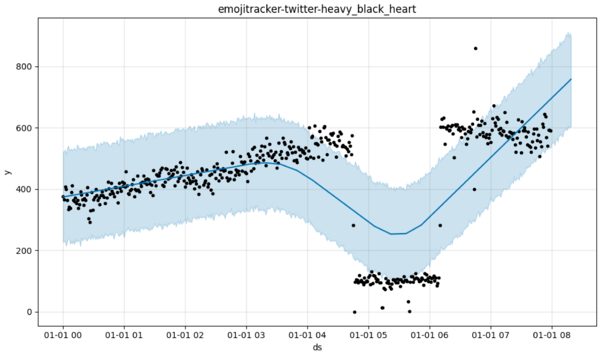
By design, Prophet’s generative model might treat all manner of disturbances as noise, no matter how prolonged they are or whether they are the dominant feature of the data. I won’t tell you what the example below represents, except to say that — like all of the series I am presenting — it is real. I want you to imagine how many real-world time series this might represent (Prophet is really going to enrage Albert-Laszlo Barabas, author of Bursts).
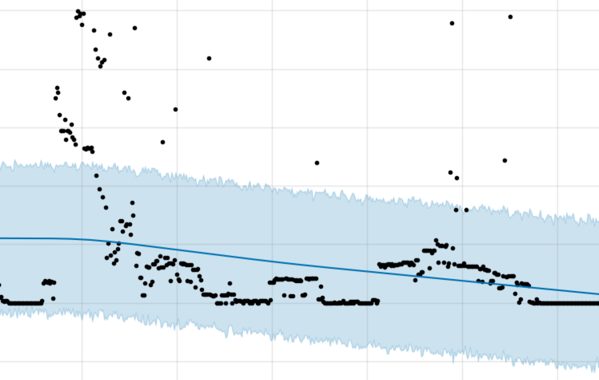
This series could be mentions of GameStop on reddit, or solar activity, or the number of Trump’s tweets (note the flatline at the end). Maybe it is the progress of a chemical reaction, or cyber-attack occurrences. The point is it could represent any number of things and Prophet may, out of the box, do an utterly terrible job of modeling all of them. More kindly, we’d say it is sometimes going to move, like the Lord, in mysterious ways.
Oh, you say, but Prophet is trying to pick up on the overall trend — nothing more. Okay, but then what do you make of the number of comments on the front page of Hacker News right now? Is it trending up or down?
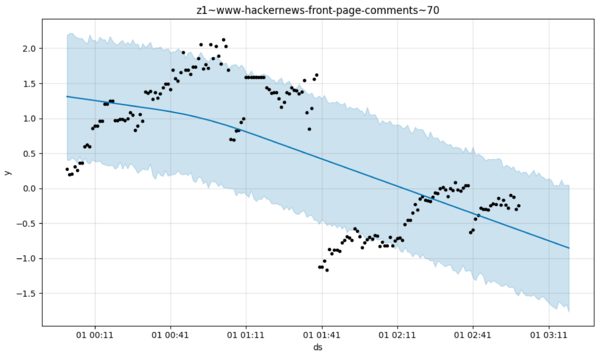
I’m going with trending up here after a pronounced change-point that should, I would think, be quite similar to a change in a product you’d see in those sales time series where Prophet (we are told) excels. If this were sales of second hand exercise bikes instead (perhaps over a longer time horizon) I’d think things were looking rosy. Prophet says no, they are headed down, down, down.
Here a more neutral forecast is going to have lower mean square error, surely. My point, to reiterate, is that Prophet is very strongly opinionated despite its use of Bayes Rule because the generative model represents a sparse set of possibilities. Way too sparse for my liking. To return to the example that started all this, Prophet might lead you to believe that due to one particularly bad day, hospital wait times at Piedmont-Atlanta are going to trend upwards indefinitely.
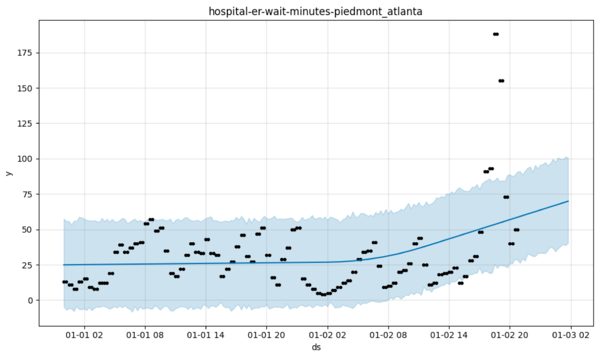
I think we know that’s kind of ridiculous, and I can’t imagine an “expert forecaster” presenting that one to the board room. So no, Facebook Prophet has not solved the problem of automating forecasting. But it is a noteworthy and interesting attempt, and hopefully contributors will continue to push it forward. There are also simple things you can do to improve your own use of Prophet.
Reigning in Prophet for Better Accuracy
Now, having shown you in-sample data, let’s look at some examples with the truth revealed. You’ll see that some of those wagers made by Prophet do pay out. For example, here’s Prophet predicting the daily cycle of activity in bike sharing stations close to New York City hospitals. It does a nice job of anticipating the dropoff, don’t you think?
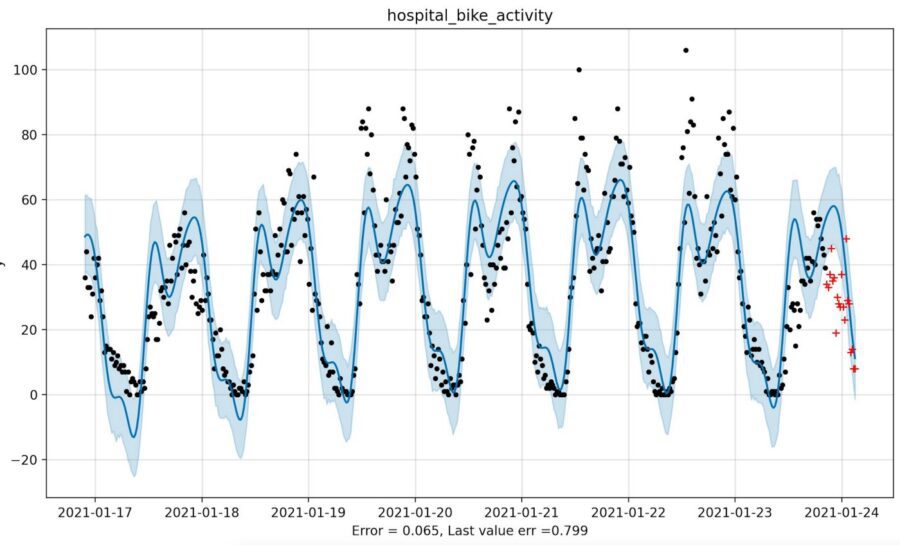
And in the example below, Prophet anticipates the uptick in trading volume for heating oil futures. That isn’t evident from looking at the last few data points, so we might give it credit (though a skeptic might suggest that this was lucky, and only due to the mis-fitting of a sinusoid to a straight line just prior).
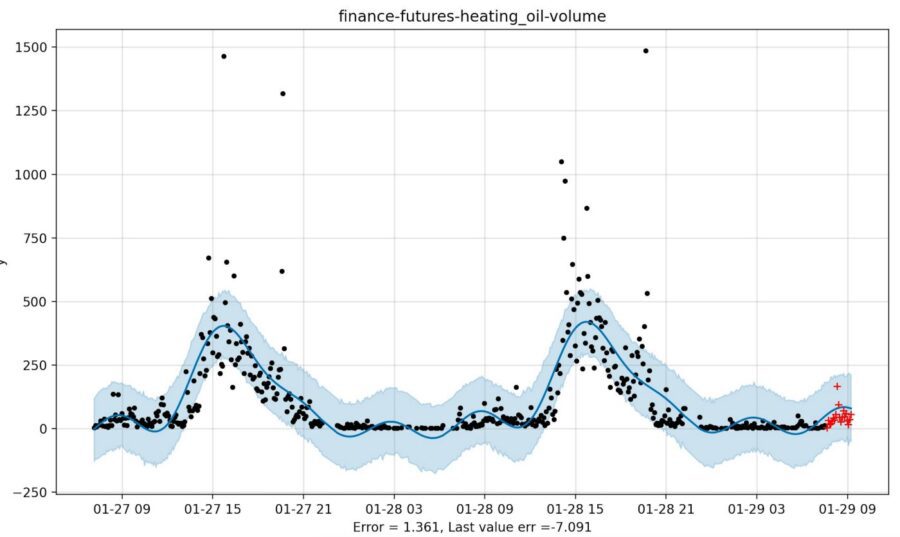
These examples help Prophet in the race for a low mean square error. Now it’s true that there can be an element of dumb luck with this metric. Here’s an example of Prophet being more accurate than the last value, but, um …
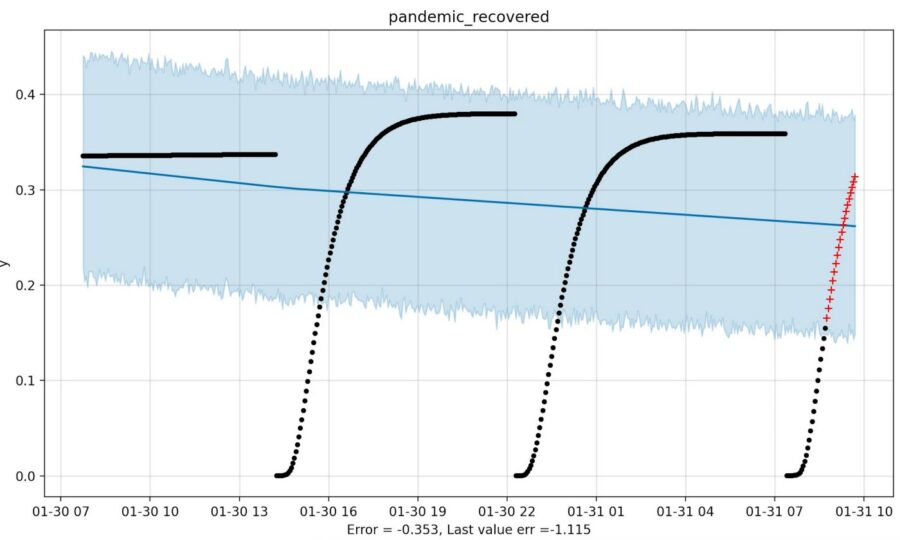
Yeah.
Let’s move on! Yes, something has gone terribly wrong here and I suspect it relates to the Fourier transform of an epidemic. But again I’m tempted to make excuses for Prophet (we could fix it by pre-processing using the Lambert W function, of course!). Similarly, in the example below I suspect but did not verify, that a change in hyper-parameters will help.
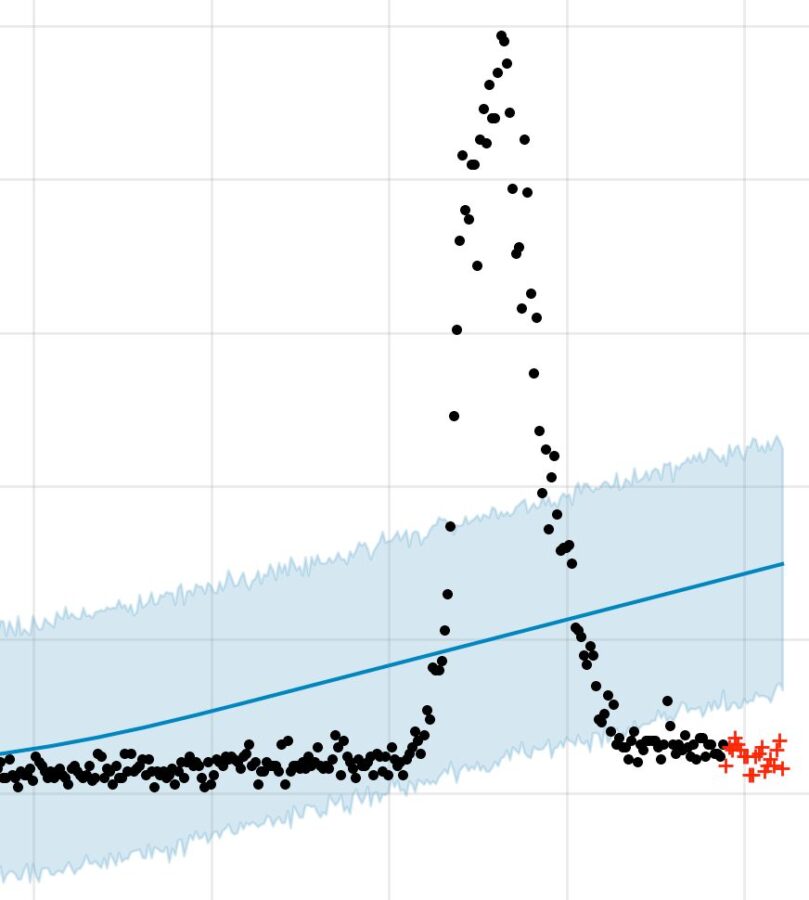
Furthermore, there are cases where Prophet shouldn’t really be punished by the error metric as much as it is.
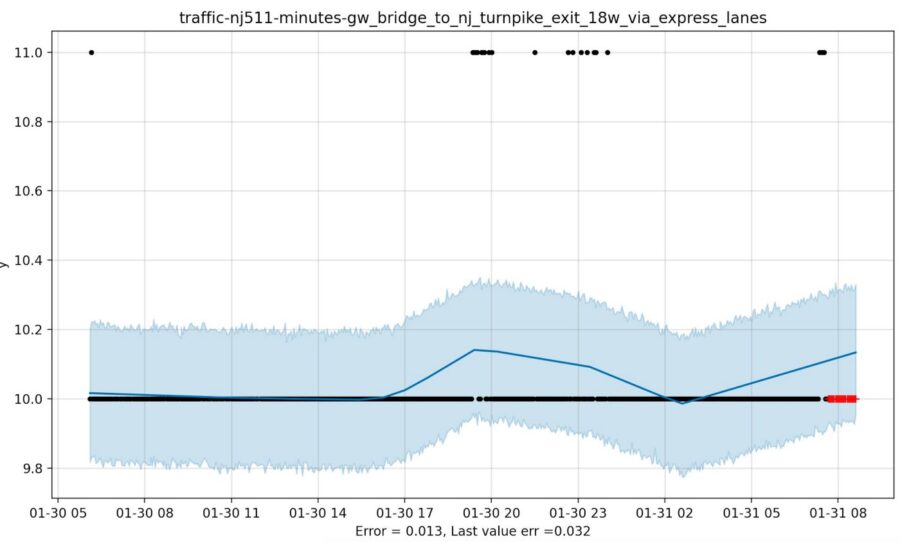
Pretty boring time series, eh? Traffic flows smoothly in the HOV (at least during COVID-19) except for a few times when it doesn’t. Not everyone will like Prophet’s answer to this question (not Mr. Least Squared Error anyway) but Prophet is trying, nobly, to tell us something. I think we should listen.
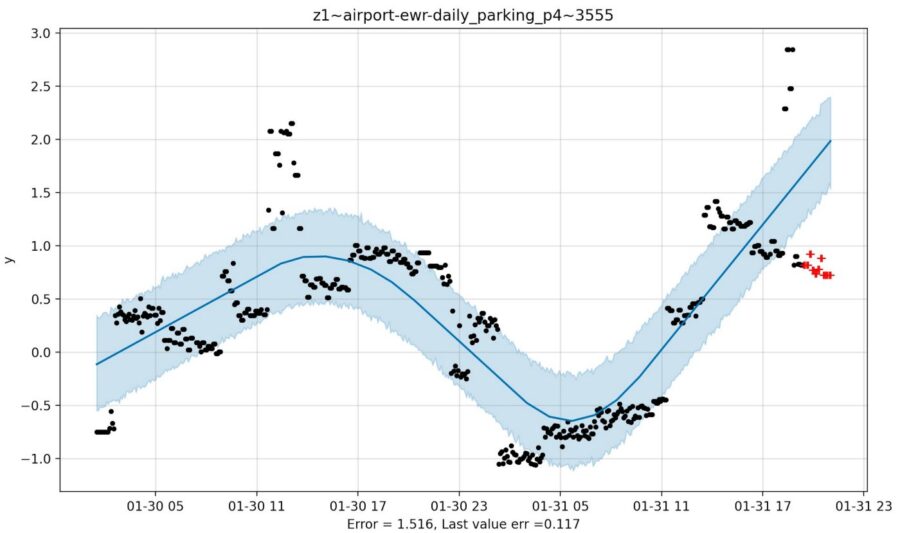
But the question is how, when and how much to listen? For instance, if the last couple of data points are indicating the beginning of a decline cycle, as with parking occupancy at Newark Airport you see below, but Prophet thinks the trend will continue, I’d be inclined to shrink Prophet’s prediction back towards the average of the last few data points. I guess it is easy to say that when you see the red out-of-sample points.
Motivated by these examples, here’s a really simple hack that seems to improve prophet
- Look at the last five data points, and compute their standard deviation.
- Construct an upper bound by adding m standard deviations to the highest data point, plus a constant. Similarly for a lower bound.
- If Prophet’s prediction is outside these bounds, use an average of the last three data points instead.
As elementary as this sounds, it really works — even when forecasting way ahead. For example, when selecting random time series from this list, giving Prophet 500 points to train on, and requesting a prediction 50 steps ahead, this simple heuristic with m=3 decreased the root mean square error by a whopping 25% (on those cases where it applied, not overall). The hack is roughly as effective, it would seem, when forecasting 20 steps ahead using m=1.5.
I don’t claim that this heuristic is optimal in any sense — I’m merely noting this particular rule as it was the first thing I tried. Any reasonable shrinkage will probably serve a similar purpose, likely with even better results. One could, of course, do all manner of related things such as use some combination of Prophet with other predictions.
Even the mere possibility of differencing the series would remove the gains Prophet makes over the last value cache on those occasions when the trend is linear and it makes most of its hay. That’s because there are plenty of examples where differencing is all you need to increase an already existing advantage held by the last value estimator over Prophet. For instance, here Prophet declines to chase the Loch Ness Monster any further whereas any half-way reasonable extrapolation would do so.
I don’t know how Nessie got away this time, but consider it part of the mysterious allure of Prophet.
In fairness, differencing could also serve Prophet well and one can surely wield it in many interesting ways, either as a signal generator, or part of a more comprehensive pipeline. The seemingly poor performance reported in the articles I noted does not preclude this, and there are certainly subtleties associated with assessment of time series modeling in the presence of serially correlated errors. One might argue that this is all a giant inverse problem and there is no definitive evaluation — though if statistical solipsism is the only defense we may have bigger problems.
To close, let me say that this post ended up being more negative than I expected and, like Nessie, my opinion may rise in the future when I understand the implications of the Prophet generative model better, and either modify it or find better ways to identify its strengths. The unanswered question here is why Prophet is so popular, and this surely merits a better explanation than I have given. I think there are probably statistical angles I am not seeing — something reflecting the fact that people are voting with their eyeballs when they use Prophet.
The pragmatic advantage of being able to forecast many different time series with some degree of accuracy and no tweaking should not be underestimated. This, assuredly, is driving the popularity of prophet and it speaks to the accomplishment. I, for one, will continue to play with Prophet and I’d encourage you to do the same. That said, I do think that those of you writing “introduction to forecasting” articles for your fellow data scientists might want to scan a little further down the list I’ve provided, and give the little guys a good run as well. For instance auto_ts attempts to tell you when Prophet is being outperformed by alternatives, just to pick one.
An Ongoing Assessment, and Elo ratings
I have begun a more systematic assessment of Prophet, as well as tweaks to the same. As with this post, I’m using a number of different real world time series and analyzing different forecast horizons. The Elo ratings seem to be indicative of Prophet’s poor performance — though I’ll give them more time to bake. However, unless things change my conclusions are:
- It is just way too easy to improve Facebook Prophet with dead simple hacks. Notice that on the leaderboards for 1-step ahead forecasting (here) and most of the others, the fbprophet_cautious algorithm is performing better than fbprophet_univariate. The former curtails “crazy” predictions by Prophet, whereas the latter runs the factory default settings.
- In keeping with some of the cited work, I find that Prophet is beaten by exponential moving averages at every horizon thus far (ranging from 1 step ahead to 34 steps ahead when trained on 400 historical data points). More worrying, the moving average models don’t calibrate. I simply hard wired two choices of parameter.
I think you can create a much better time series approach than Prophet. If you have ideas, and can render them with a simple “skater” signature (explained in the README.md) I’d love to include them.
This article originally appeared on the microprediction blog.To ensure articles like this are in your thread, or category updates here, consider following microprediction on LinkedIn. We’re trying to make powerful, bespoke AI free and convenient, and you are welcome to contribute in large or small ways – even win a competition or two. If you have a suggestion, please file an issue.
{kind=link}