
This article was written by Sarthak Jain.
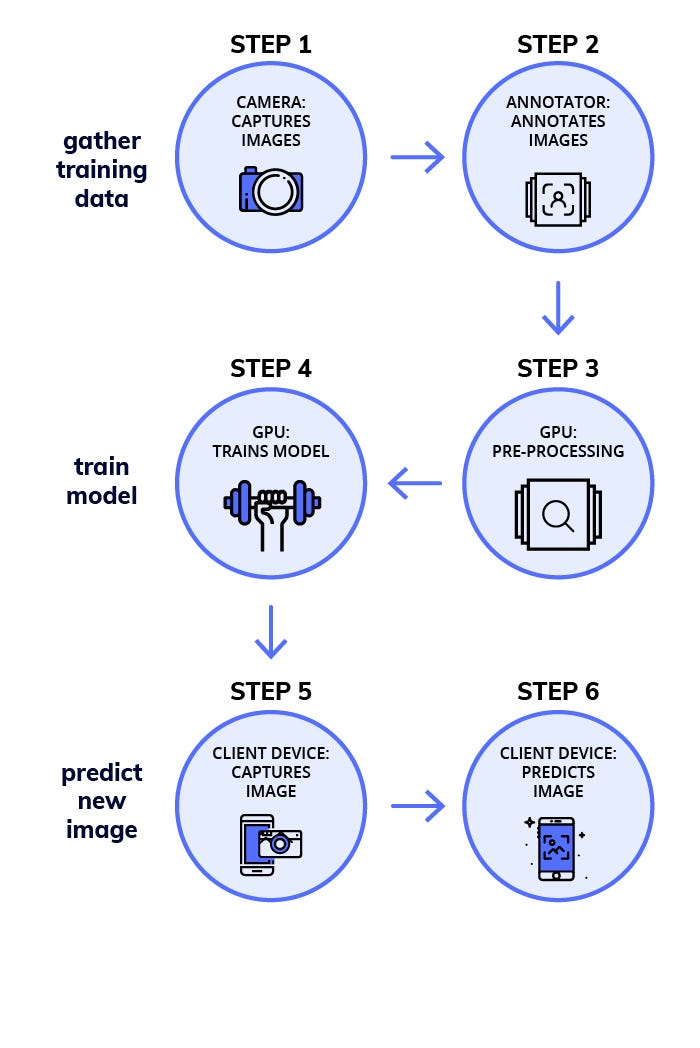
The real world poses challenges like having limited data and having tiny hardware like Mobile Phones and Raspberry Pis which can’t run complex Deep Learning models. This post demonstrates how you can do object detection using a Raspberry Pi. Like cars on a road, oranges in a fridge, signatures in a document and teslas in space.
Why Object Detection?, Why Raspberry Pi?
The raspberry pi is a neat piece of hardware that has captured the hearts of a generation with ~15M devices sold, with hackers building even cooler projects on it. Given the popularity of Deep Learning and the Raspberry Pi Camera we thought it would be nice if we could detect any object using Deep Learning on the Pi.
Now you will be able to detect a photobomber in your selfie, someone entering Harambe’s cage, where someone kept the Sriracha or an Amazon delivery guy entering your house.
What is Object Detection?
20M years of evolution have made human vision fairly evolved. The human brain has 30% of it’s Neurons work on processing vision (as compared with 8 percent for touch and just 3 percent for hearing). Humans have two major advantages when compared with machines. One is stereoscopic vision, the second is an almost infinite supply of training data (an infant of 5 years has had approximately 2.7B Images sampled at 30fps).
To mimic human level performance scientists broke down the visual perception task into four different categories.
- Classification, assigns a label to an entire image
- Localization, assigns a bounding box to a particular label
- Object Detection, draws multiple bounding boxes in an image
- Image segmentation, creates precise segments of where objects lie in an image
Object detection has been good enough for a variety of applications (even though image segmentation is a much more precise result, it suffers from the complexity of creating training data. It typically takes a human annotator 12x more time to segment an image than draw bounding boxes; this is more anecdotal and lacks a source). Also, after detecting objects, it is separately possible to segment the object from the bounding box.
How do I use Object Detection to solve my own problem?
Object Detection can be used to answer a variety of questions. These are the broad categories:
- Is an object present in my Image or not? eg is there an intruder in my house
- Where is an object in the image? eg when a car is trying to navigate it’s way through the world, its important to know where an object is.
- How many objects are there in an image? Object detection is one of the most efficient ways of counting objects. eg How many boxes in a rack inside a warehouse
- What are the different types of objects in the Image? eg Which animal is there in which part of the Zoo?
- What is the size of an object? Especially with a static camera, it is easy to figure out the size of an object. eg What is the size of the Mango
- How are different objects interacting with each other? eg How does the formation on a football field effect the result?
- Where is an object with respect to time (Tracking an Object). eg Tracking a moving object like a train and calculating it’s speed etc.
To read the rest of this article, click here.
{kind=link}