
“If” by Rudyard Kipling
If you can keep your head when all about you
Are losing theirs and blaming it on you,
If you can trust yourself when all men doubt you,
But make allowance for their doubting too;
If you can wait and not be tired by waiting,
Or being lied about, don’t deal in lies,
Or being hated, don’t give way to hating,
And yet don’t look too good, nor talk too wise:
I’m sure that most data scientists have experienced that moment when they realize that the folks around them have no idea what they do. That moment when someone walks up to them and says “I’ve got some data. Can you do some data science on it?”
Many organizations started their data science journey by hiring a “data scientist” and asking him or her to perform magic on the data. And while there are countless problems with that approach, companies quickly learned that 1) not everyone who calls themselves a data scientist is a data scientist (I can call myself young and dashing, but that doesn’t make it so) and 2) there is no magic when it comes to data science. Sorry, but as Chris Rock famously said:
There is no sex in the champagne room…
Data Science is very hard work, requiring experience and expertise in gathering (scraping in some cases) data from a wide variety of poorly documented and hard-to-access data sources; dealing with the incompleteness, inaccuracies, vagueness and poor documentation about the data; massaging, twisting and torturing that data into some useful form; and trying a seemingly endless number of analytic transformations, enrichments, and algorithms in an attempt to find those combinations of variables and metrics that might yield a better predictor of performance (see Figure 1).
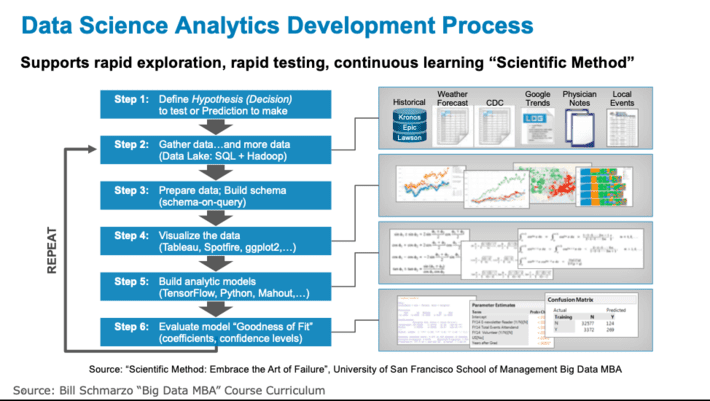
Figure 1: Data Science Analytics Development Process
The key to the successful execution of the data science analytics development process – where success is defined as delivering predictive and prescriptive results that materially impact the operations and success of the business – is the pre-work. This means not an hour or so of “showing up and throwing up’, but an orchestrated business stakeholder and subject matter expert engagement process that ensures that the data science team thoroughly and intimately understands the business opportunity under consideration, understand the metrics and KPIs against which progress and success will be measured, has identified, validated, valued and prioritized the decisions that need to be optimized in support of the business opportunity and understands the costs of the analytics being wrong (the cost of False Positives and False Negatives). So how do we ensure data science success? We cheat.
We cheat; we do tons of pre-work before we ever “put science to the data”
Cheating: The Pre-work before “Putting Science to the Data”
As I discussed in the blog “Why Is Data Science Different than Software Development?”, the methodologies and processes that support successful software development do not work for data science projects according to one simple observation: software development knows, with 100% assurance, the expected outcomes, while data science – through data exploration and hypothesis testing, failing and learning – discovers those outcomes (see Figure 2).

Figure 2: Key Differences Between Software Development and Data Science
Software development defines the criteria for success; Data Science discovers them
Consequently, the development folks and management sometimes do not understand and appreciate the significant amount of work that needs to be done “before ever putting science to the data” to give the data science development process the highest probability of success. And for data scientists, that data science development process is about getting all the key business stakeholders, business executives, and subject matter experts to “think like a data scientist”.
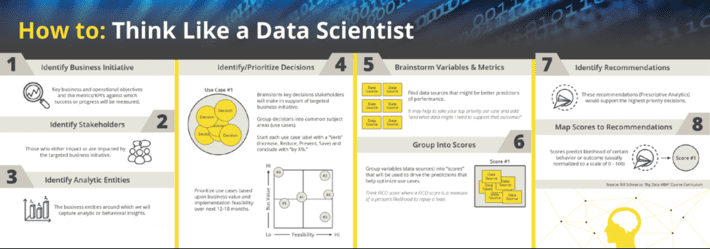
Figure 3: Thinking Like a Data Scientist
It is critical to the success of the data science initiative not only to have subject matter expertise involved at the beginning of the engagement (because they have valuable insights into variables and metrics that might be better predictors of performance gathered over years of hands-on experience), but it is critical to understand their work environment and decision-making processes to help drive the subsequent adoption of the analytics.
Check out the following sources for more details on the “Thinking Like A Data Scientist” process:
- “Big Data MBA: Driving Business Strategies with Data Science” which is the textbook that I use for teaching at the University of San Francisco and the National University of Ireland – Galway.
- “Refined Thinking like a Data Scientist Series” blog.
Data Science Development Pre-requisites to Success
There are several data science pre-engagement prerequisites that we require before we ever “put science to the data” (see Figure 4). They include:
- Creating a persona for each stakeholder or constituent that captures roles, responsibilities, pain points, and key operational decisions.
- Document the use cases that comprise the targeted business initiative or opportunity; document financial, operational, and customer benefits and potential implementation risks for each use case.
- Identifying, brainstorming, and ranking internal and external data sources against the top priority use cases; assessing data implementation risks associated with accessibility, completeness, granularity, accuracy, latency, documentation, etc.
- Leveraging the Prioritization Matrixto conduct an envisioning exercise with key stakeholders and constituents to prioritize use cases (business value vs. implementation feasibility) and create a Use Case Roadmap that identifies use case interdependencies and prerequisites.
- Developing a Hypothesis Development Canvas to ensure cross-organizational alignment by fleshing out priority use case business and data science requirements including KPIs against which to measure success and progress; financial, customer, and operational benefits and costs associated with False Positives and False Negatives.
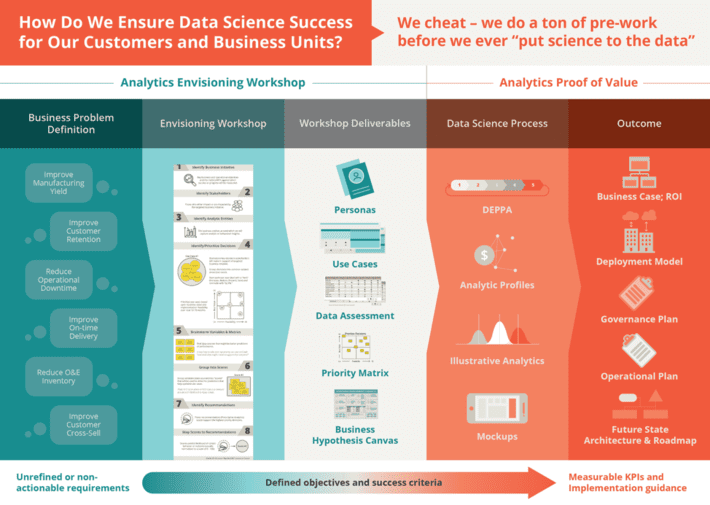
Figure 4: Guide for Ensuring Data Science Success
How We Do It at Hitachi Vantara
Now, I’m not saying that this is the only approach for doing the data science development pre-work, but this is what we’ve found works for us (and is the heart of the Big Data MBA methodology that I teach at the University of San Francisco School of Management). This process leverages several design thinking concepts and techniques to first identify the prerequisites for success (we call it an Envisioning Workshop and typically takes 2 to 3 days to complete). We then follow up the Envisioning Workshop with a Proof of Value (not a Proof of Concept) to prove out the business and operational value for the top use cases coming out of the Envisioning Workshop (see Figure 5).
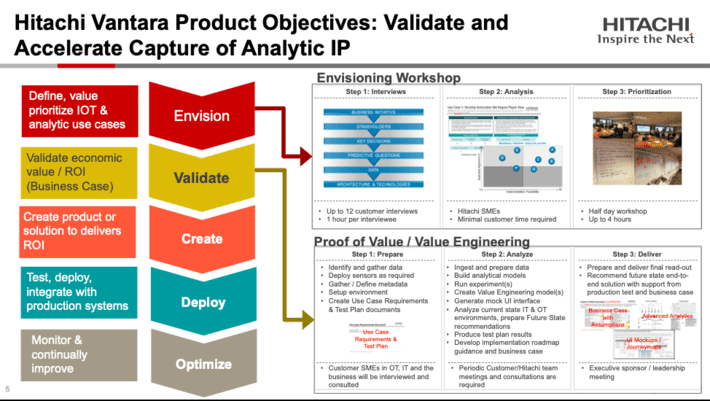
Figure 5: Leveraging Design Thinking and Envisioning to Drive Data Science Success
So there, I’ve given away all of our secrets. No reason why anyone should ever just grab some data and expect the data science team to do magic. Because remember, there is no sex in the champagne room.
%20Wars? %20You%20Cheat%20By%20Doing%20The%20Necessary%20Pre-work!){kind=link}