
Summary: The data science press is so dominated by articles on AI and Deep Learning that it has led some folks to wonder whether Deep Learning has made traditional machine learning irrelevant. Here we explore both sides of that argument.
 On Quora the other day I saw a question from an aspiring data scientist that asked – since all the competitions on Kaggle these days are being won by Deep Learning algorithms, does it even make sense to bother studying traditional machine learning methods? Has Deep Learning made traditional machine learning irrelevant?
On Quora the other day I saw a question from an aspiring data scientist that asked – since all the competitions on Kaggle these days are being won by Deep Learning algorithms, does it even make sense to bother studying traditional machine learning methods? Has Deep Learning made traditional machine learning irrelevant?
I can understand on a couple of levels why he asked the question. First if you look at the recently completed Kaggle problems it’s easy to draw the conclusion that deep learning is the only way to win. Second, if you follow the data science literature we are being bombarded by information about advancements in deep learning, especially as it’s implemented in AI, with very little new coming out about all the other algorithms that make up our tool kit.
I think there are some deep misunderstandings about data science here and it struck me as an instructable moment.
Redefining the Question
It’s important to understand that although a lot of effort is being put into deep learning these days that it remains just one part of our tool kit. It’s equally important to understand the deep learning is not separate from machine learning (ML) but in fact is a subset of ML.
A few months ago we wrote about the distinctions among AI, Deep Learning, and Machine Learning. You might find that a good place to start if your interest is high. For this conversation though we’re going to start with a little dive into Machine Learning. Despite some recent attempts to narrow the definition, the great majority of us use ML to mean the application of any computer-enabled algorithm that can be applied against a data set to find a pattern in the data. This encompasses basically all types of data science algorithms, supervised, unsupervised, segmentation, classification, or regression.
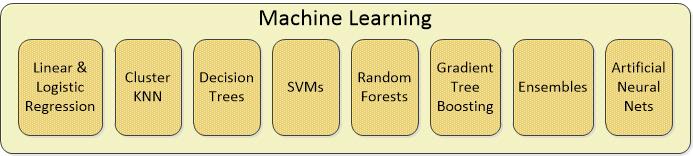
There are undoubtedly some I’ve left out that are important especially in AI like information retrieval algorithms (IR) that are the heart of new advances like Watson, but basically this is the tool kit. And yes there are so many variants on each of these that a full listing would fill pages.
The important thing to understand is that what we call Deep Learning (DL) is actually a number of variations on Artificial Neural Nets (ANNs). There are at least 28 unique architectures for ANNs and those that have multiple hidden layers (and almost all of the 28 do) we refer to as ‘deep’, hence Deep Learning. So for purposes of this conversation our diagram should look like this:
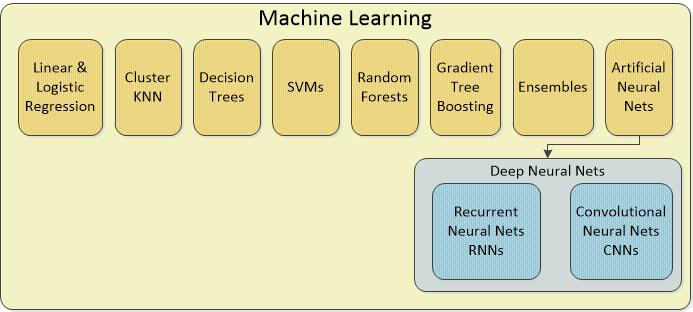
I’ve particularly called our Recurrent Neural Nets (RNNs) and Convolutional Neural Nets (CNNs) from among the deep category of ANNs because this is where the action is. RNNs have enabled most of the advances in Natural Language Processing (NLP) like the chatbots Siri, Alexa, and Cortana plus automated translation and the analysis of voice and text files. CNNs have enabled most of the advances in image processing with some overlap into NLP.
If you wanted to be a deep specialist in image and language processing you could probably build a career around these two Deep Learning ANNs but this by no means invalidates the continued utility or value of the rest.
About Competitions Like Kaggle
Kaggle and similar sites are a tremendous resource to data science as they give advanced and beginner data scientists a chance to stretch their wings on a variety of problems. Just participating is acknowledged to be one of the best  learning opportunities in DS. But you need to see these competitions like Formula One racing. They strive for the absolute maximum accuracy in their result, but like Formula One, that doesn’t have much in common with your day-to-day commute.
learning opportunities in DS. But you need to see these competitions like Formula One racing. They strive for the absolute maximum accuracy in their result, but like Formula One, that doesn’t have much in common with your day-to-day commute.
Consider this. If you look at the leader boards with the top 10 or 20 solution submissions the variation in results is frequently at only the third or fourth decimal point. That accuracy is equivalent to the edge in racing that makes a winner but it’s not likely to be relevant in most data science problems you encounter in your business. In fact it’s positively unlikely that devoting that much effort to squeezing out the last little bit of accuracy would make good business economics.
It is true that many of the competitions you see on Kaggle these days contain unstructured data that lends itself to Deep Learning algorithms like CNNs and RNNs. Anthony Goldbloom, the founder and CEO of Kaggle observed that winning techniques have been divided by whether the data was structured or unstructured.
Regarding structured data competitions, Anthony says “It used to be random forest that was the big winner, but over the last six months a new algorithm called XGboost has cropped up, and it’s winning practically every competition in the structured data category.” More recently however, Anthony says the structured category has come to be dominated by what he describes as ‘hand crafted’ solutions heavy on domain knowledge and stochastic hypothesis testing.
When the data is unstructured, it’s definitely CNNs and RNNs that are carrying the day. Since a very high percentage of Kaggle problems these days are based on unstructured data it’s easy to see why our original observer might question why use anything else.
The Business Drawbacks of Deep Learning Artificial Neural Nets
We mentioned earlier that there are at least 28 unique architectures for ANNs, many of which are quite specialized like the many-hidden layers necessary in CNNs and RNNs. If your business has image or NLP unstructured data that needs to be analyzed then using CNNs and RNNs is the way to go.
But keep in mind:
- CNNs and RNNs are very difficult to train and sometimes fail to train at all.
- If you are building a CNN or RNN from scratch you are talking weeks or even months of development time.
- CNNs and RNNs require extremely large amounts of labeled data on which to train which many companies find difficult or too costly to acquire.
In fact the barriers to de novo CNN and RNN creation are so steep that the market is rapidly evolving toward prebuilt models available via API from companies like Amazon, Microsoft, IBM, Google, and others.
When you’re implementing Deep Learning solutions in an in-house system like automated customer service, this API approach may work fine. If you need a portable application, for example in an IoT environment, be aware that this frequently means not deploying a software solution but a CNN or RNN algorithm hard-coded in a special purpose chip like GPUs and FPGAs.
The Real Data Science Market
We’ve written before about the two distinct data science markets that have evolved. The ‘Big Web User’ data science world is focused on companies in the major hubs like San Francisco, LA, Boston, and New York developing applications where the code is the product. This market wants and needs the most advanced data science techniques to bond with their users and to differentiate themselves from competitors. Think Google, Amazon, eHarmony, and the MOOGs. If you want to specialize in Deep Learning and the application of unstructured NLP and image data this is the place.
But upwards of 80% of the application of data science today is still in the prediction of consumer behavior. Why they come, why they stay, why they go, what will they buy next or the most of. This is the high value world of relatively straight forward scoring systems that are embedded in all of our customer facing systems to recommend purchases, solutions to problems, and next best offers for CSR conversations.
Add to this a percentage of what are now common place supply chain forecasters working on time series data, equipment monitoring solutions used in predictive maintenance, and some geospatial algorithms primarily for site and market planning. The point is that essentially all of these applications are best addressed by the balance of the traditional ML tool kit that has definitely not gone out of fashion.
Even though Deep Learning ANNs could be directed toward these same class of problems based on largely structured data with some unstructured now being introduced, they are not suitable from an efficiency standpoint. You can build a perfectly serviceable predictive model in as little as seven minutes (OK typically maybe a few hours). The accuracy will be appropriate for the investment in time versus the business value to be achieved. The business will not wait weeks or months for a CNN or RNN solution.
So decidedly no, Deep Learning has not and will not make traditional Machine Learning techniques obsolete. And yes, to become a data scientist, you need to master the full traditional ML tool kit.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}