
GraphQL & gRPC (Part 1)

GraphQL(Graph Query Language) is a powerful query language that has allowed huge organizations, like Facebook and Github, to expose massive amounts of data; gRPC is an open source remote procedure call (RPC) system initially developed at Google. Although these technologies live in extremely different spaces, they can work together and complement each other perfectly.
Through the years, the workhorse for exposing data to client applications has been Roy Fielding’s REST (Representational State Transfer) APIs. As any older developer would know, if you stuck by those API design practices you would be miles ahead of ad-hoc APIs protocols and the verbose SOAP and CORBA. The key improvements were: uniform interfaces, stateless interactions, clear boundaries between client and server, and a straightforward way to be cached.
However, this type of APIs, at the time of writing this article, are 17 years old and are showing their age; especially since they’re cumbersome to customize, version and maintain.
State of Affairs

These days, when exposing data for a client application, we follow a set of well-defined steps. For creating data and exposing simple relationships between objects, we can even automate the process using the CRUD philosophy.
CRUD (which stands for create, read, update and delete), is a way to atomically interact with databases, and when combined with REST it takes advantage of the HTTP verbs; POST for creating, GET for reading, PATCH for updating and DELETE for deleting.
When your application basically puts a spreadsheet on the web (a very high demand type of application, that will in no way die in the foreseeable future), CRUD is the way to go. You can move at an incredible speed, mainly through the use of automated tools and ‘tried and true’ development techniques.
Despite its strengths, there are some decisive weaknesses that can make or break any application made with this paradigm. Those weaknesses become more pronounced when dealing with data that can be best represented as a graph. Examples of that are social networks, purchase recommendations and IT operations data.
A specific weakness relates to resource-constrained environments, such as applications running on slow mobile networks. In this case, there are some options, the first one is to use the traditional approach, according to which you keep the requests atomic and make one request for every single recursive definition. If you don’t have too many recursive definitions, that is not a big problem, but if you don’t keep it in check, the requests can rack up quickly.

Model of recursive resources (in orange) and requests (in green), note the unnecessary requests
The second option is to develop one custom endpoint for every feature in your application, implementing the level of recursion needed for each one, and trimming the unnecessary data along the way.
A third option would be to migrate to a more appropriate representation of this type of data, namely, graph databases. This effort, even if possible, may not be feasible due to service availability issues or the development team’s skill set.
These approaches may waste resources; either development time or end-user resources.
Another element of the status quo is the prevalent use of HTTP/1.1 and text as a transport channel among the resources of microservice-based systems.
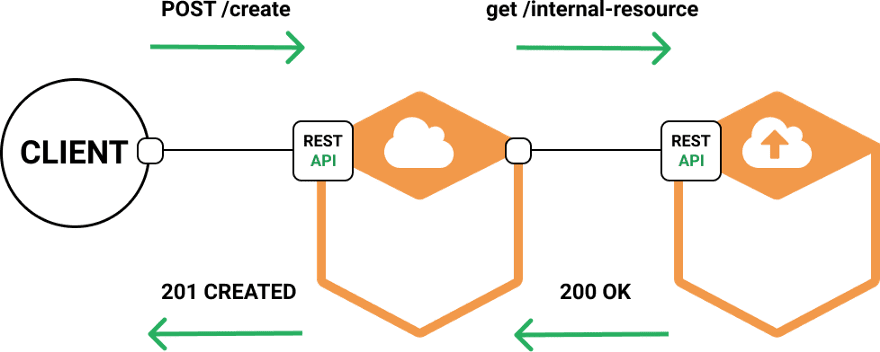
model of rest microservice, using HTTP for internal communication
Using both is quick and easy; however, on large, microservice-based systems, the number of requests increases, at best, linearly with the number of services. When you have full control of the system using a somewhat wasteful protocol, this is less than ideal.
You can mitigate that wastefulness by using compression, and then you are trading CPU time of both actors of the REST transaction for network traffic.
Enter GraphQL

GraphQL is Facebook’s answer to the recursive resource problem, without the need to migrate all your data layer to graph databases. You could either map your queries directly to a graph database or through high-level abstractions that emulate this functionality with traditional SQL databases.
All implementations of GraphQL are engineered in such a way that you may give it direct access to your databases, nevertheless, it can also access your data through existing endpoints.
In the JavaScript implementation, we have a concept called resolvers; these help the programmer define how the data is retrieved. It is possible to pre-process data, select parts to send or send it as-is.
Enter gRPC

gRPC is Google’s attempt to end the reign of HTTP/1.1 and replace with a more performant standard. By the merit of binary encoding messages with the Protocol Buffers standard and using HTTP/2.
To get started implementing gRPC on your chosen language and for more depth on this matter be sure to consult the awesome documentation.
GraphQL and gRPC seem to be a match made in heaven, as both try to mitigate the problem of transmitting huge messages across networks, and since GraphQL uses a high level approach and gRPC a low level one, they can be used together seamlessly.
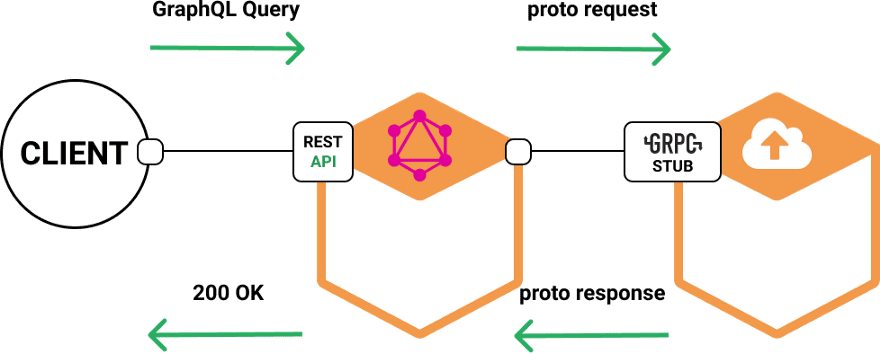
Using GraphQL as smart endpoint which communicates with internal services using gRPC
By using GraphQL to expose the data, the client can specify exactly the data it needs, and by using gRPC for internal communication you are decreasing, even more, the resource and request footprint of your application.
To read original, click here
){kind=link}