
A “quick” introduction to PyMC3 and Bayesian models, Part I
In this post, I give a “brief”, practical introduction using a specific and hopefully relate-able example drawn from real data.
For this series of posts, I will assume a basic knowledge of probability (particularly, Bayes theorem), as well as some familiarity with python. . For a more in-depth probability course, I recommend this book. For a course in Bayesian statistics, get this book.
Waiting for a taxi
We’ve all been there, maybe 15 minutes before a meeting, at 4 AM after a party, or simply when we feel too lazy to walk. And even though apps like Uber have made it relatively painless, there are still times when it is necessary or practical to just wait for a taxi. So we wait, impatiently, probably while wondering how much we will have to wait.
Modeling
To answer this question in the frame of Bayesian statistics, we first must choose two things:
- A generative model for our possible observations
- A prior distribution for the parameters of that model
As the name implies, a generative model is a probability model which is able to generate data that looks a lot like the data we might gather from the phenomenon we’re trying to model. In our case, we need a model that generates data that looks like waiting times.
Fortunately, the exponential distribution, a very well-known continuous distribution, can be used to model waiting times for unscheduled arrivals due to the property of memorylessness, which means that, after waiting any amount of time, the distribution is the same than at the start.
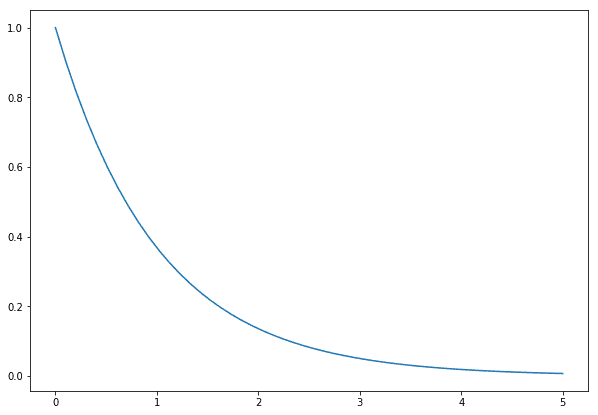
An example of the exponential distribution. Most of the density is concentrated near zero.
This distribution has a single parameter λ, which indicates the expected rate at which the event occurs. We need to describe the prior information or belief about this parameter. For example, we know it’s positive (our taxi can’t arrive before we’re waiting for it!), it has no natural upper bound and depending on what we know (or believe) about it, we can choose any number of distributions to encode such knowledge. For simplicity, I choose again the exponential, in such a way that the expected rate of arrival is 1 taxi every 5 minutes.
Here’s how to do it in PyMC3.

With these, we’re now able to generate some data that looks like waiting times and even answer questions about probability. However, there’s no guarantee about the accuracy of the answers. We need data for that.
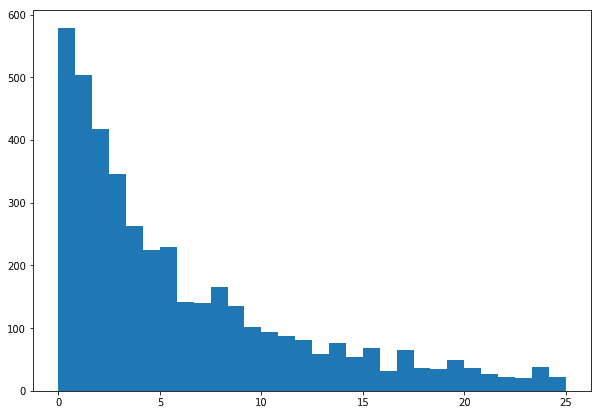
An example histogram of the waiting times we might generate from our model.
Adding data
(The data used in this post was gathered from the NYC Taxi & Limousine Commission, and filtered to a specific month and corner, specifically, the first month of 2016, and the corner of 7th avenue with 33rd St)
Suppose that, miraculously, we have access to a month’s worth of data about taxi pickups, specifically, pickups near the corner where we’re waiting. We could look at the time between consecutive pickups and call it the waiting time for the next taxi arrival.
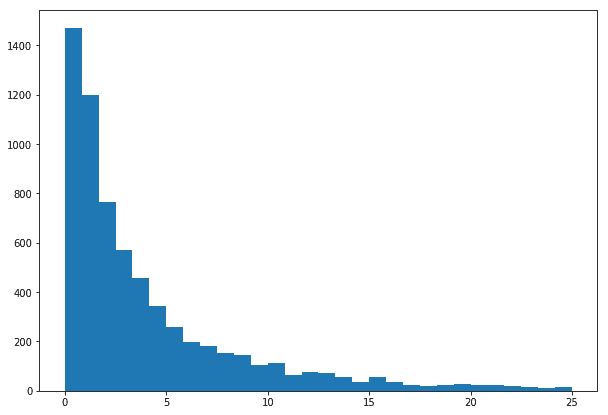
The histogram of our data. Note the shape of the distribution is similar to our generative model.
There’s an obvious problem with using these data to model waiting times for a person: that person is not necessarily waiting as soon as the previous taxi leaves, but rather arrives at some point between two pickups. Furthermore, many empty taxis may pass through the corner without picking anyone up. We’ll see how to deal with these problems in later posts. For now, though, let’s call it an approximate model and carry on.
Adding the data to our model in PyMC3 is as simple as adding a parameter:

Adding data. Note the extra parameter “observed” in the wait_times definition.
That’s it, we’re now ready to “train” our model and look at some results.
Inference and answering questions
Thanks to the Bayes theorem and our generative model, we can now draw samples from the posterior distribution, this is also straightforward in PyMC3

We can choose many different methods to draw from this distribution. In this case, I’m using the classic Metropolis algorithm, but PyMC3 also has other MCMC methods such as the Gibbs sampler and NUTS, as well as a great initializer in ADVI.
Let’s look at our posterior distribution:
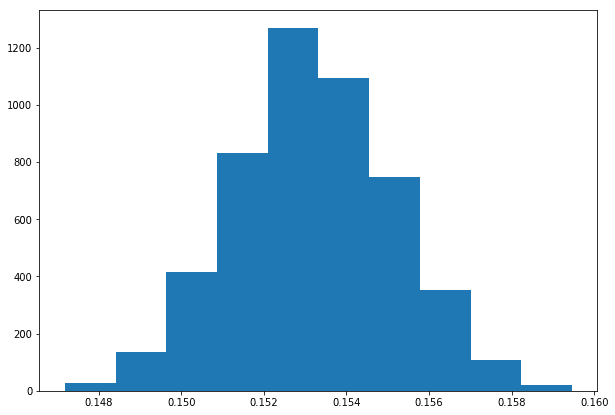
The posterior distribution for the rate parameter. It encodes the uncertainty about it after observing the data.
With our posterior distribution, we can now answer questions about the rate parameter. For example, its expected value is around 0.152, which works out to about 1 taxi every 6.5 minutes, which is also the expected value of the expected waiting time. We can also look at probability intervals (there’s a 0.95 probability that the rate parameter is between 0.15 and 0.158) or at thresholds (0.99 probability that it is below 0.159).

How to compute probabilities using the posterior samples. We count the number of cases and divide by the total samples drawn.
It is tempting to try and draw direct conclusions about the waiting times from this distribution, but it would be a mistake. The posterior distribution is the representation of our knowledge of the parameters of the model, not about the phenomenon we’re modeling itself. In other words, it tells us how certain we are about our model. A flat posterior means we have not been able to find one good model, but rather that there are many possible models with similar “fit”.
To be able to answer questions about the phenomenon itself, we need the predictive distribution. This distribution adds the uncertainty about the parameters to the uncertainty present in the model itself, providing us with a proper way to measure the uncertainty of our predictions. We can draw samples from it with one line:

We can now ask questions such as:
- The expected waiting time: 6.57
- The probability we wait more than 10 minutes: 0.21
- The probability we wait less than a minute: 0.13
Let’s also look at our posterior distribution. Note how it has a heavier tail than our data. This represents our uncertainty about our predictions.
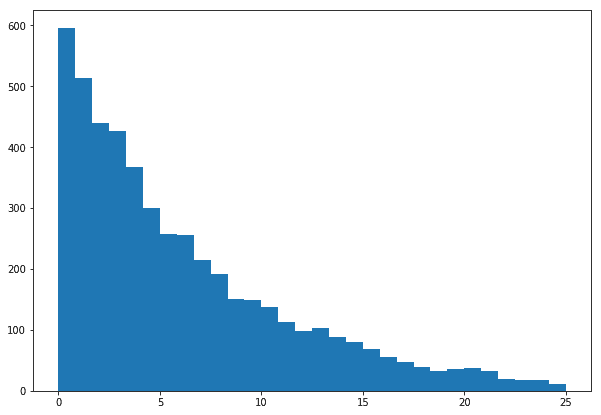
Our posterior distribution. The slightly heavier tail implies we can’t rule out the probability of observing large waiting times, despite our data not showing a lot of them.
What’s next?
While this model can give us a lot of information, it is not very good at making predictions. This is to be expected because we’re not adding any feature or covariate that can help us predict our target better.
In the next post, we’ll see how to add features or covariates to a model. We’ll briefly talk about functional forms and will end with a note about prior selection.
(This blog post originally appeared in Datank.ai’s blog here)
{kind=link}