
Lecture notes for the Statistical Machine Learning course taught at the Department of Information Technology, University of Uppsala (Sweden.) Updated in March 2019. Authors: Andreas Lindholm, Niklas Wahlström, Fredrik Lindsten, and Thomas B. Schön.
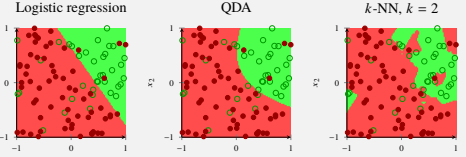
Source: page 61 in these lecture notes
Available as a PDF, here (original) or here (mirror).
Content
1 Introduction 7
1.1 What is machine learning all about?
1.2 Regression and classification
1.3 Overview of these lecture notes
1.4 Further reading
2 The regression problem and linear regression 11
2.1 The regression problem
2.2 The linear regression model
- Describe relationships — classical statistics
- Predicting future outputs — machine learning
2.3 Learning the model from training data
- Maximum likelihood
- Least squares and the normal equations
2.4 Nonlinear transformations of the inputs – creating more features
2.5 Qualitative input variables
2.6 Regularization
- Ridge regression
- LASSO
- General cost function regularization
2.7 Further reading
2.A Derivation of the normal equations
- A calculus approach
- A linear algebra approach
3 The classification problem and three parametric classifiers 25
3.1 The classification problem
3.2 Logistic regression
- Learning the logistic regression model from training data
- Decision boundaries for logistic regression
- Logistic regression for more than two classes
3.3 Linear and quadratic discriminant analysis (LDA & QDA)
- Using Gaussian approximations in Bayes’ theorem
- Using LDA and QDA in practice
3.4 Bayes’ classifier — a theoretical justification for turning p(y | x) into yb
- Bayes’ classifier
- Optimality of Bayes’ classifier
- Bayes’ classifier in practice: useless, but a source of inspiration
- Is it always good to predict according to Bayes’ classifier?
3.5 More on classification and classifiers
- Regularization
- Evaluating binary classifiers
4 Non-parametric methods for regression and classification: k-NN and trees 43
4.1 k-NN
- Decision boundaries for k-NN
- Choosing k
- Normalization
4.2 Trees
- Basics
- Training a classification tree
- Other splitting criteria
- Regression trees
5 How well does a method perform? 53
5.1 Expected new data error Enew: performance in production
5.2 Estimating Enew
- Etrain 6≈ Enew: We cannot estimate Enew from training data
- Etest ≈ Enew: We can estimate Enew from test data
- Cross-validation: Eval ≈ Enew without setting aside test data
5.3 Understanding Enew
- Enew = Etrain+ generalization error
- Enew = bias2 + variance + irreducible error
6 Ensemble methods 67
6.1 Bagging
- Variance reduction by averaging
- The bootstrap
6.2 Random forests
6.3 Boosting
- The conceptual idea
- Binary classification, margins, and exponential loss
- AdaBoost
- Boosting vs. bagging: base models and ensemble size
- Robust loss functions and gradient boosting
6.A Classification loss functions
7 Neural networks and deep learning 83
7.1 Neural networks for regression
- Generalized linear regression
- Two-layer neural network
- Matrix notation
- Deep neural network
- Learning the network from data
7.2 Neural networks for classification
- Learning classification networks from data
7.3 Convolutional neural networks
- Data representation of an image
- The convolutional layer
- Condensing information with strides
- Multiple channels
- Full CNN architecture
7.4 Training a neural network
- Initialization
- Stochastic gradient descent
- Learning rate
- Dropout
7.5 Perspective and further reading
A Probability theory 101
A.1 Random variables
- Marginalization
- Conditioning
A.2 Approximating an integral with a sum
B Unconstrained numerical optimization 105
B.1 A general iterative solution
B.2 Commonly used search directions
- Steepest descent direction
- Newton direction
- Quasi-Newton
B.3 Further reading
Bibliography
{kind=link}