
By Soroush Nasiriany, Garrett Thomas, William Wang, Alex Yang. Department of Electrical Engineering and Computer Sciences, University of California, Berkeley. Dated June 24, 2019. This is not the same book as The Math of Machine Learning, also published by the same department at Berkeley, in 2018, and also authored by Garret Thomas.
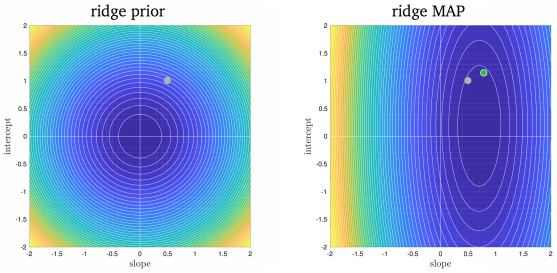
Source: this book, page 21
Content
1 Regression I 5
- Ordinary Least Squares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
- Ridge Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
- Feature Engineering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
- Hyperparameters and Validation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 Regression II 17
- MLE and MAP for Regression (Part I) . . . . . . . . . . . . . . . . . . . . . . . . . . 17
- Bias-Variance Tradeoff . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
- Multivariate Gaussians . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
- MLE and MAP for Regression (Part II) . . . . . . . . . . . . . . . . . . . . . . . . . 37
- Kernels and Ridge Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
- Sparse Least Squares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
- Total Least Squares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3 Dimensionality Reduction 63
- Principal Component Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
- Canonical Correlation Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4 Beyond Least Squares: Optimization and Neural Networks 79
- Nonlinear Least Squares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
- Optimization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
- Gradient Descent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
- Line Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
- Convex Optimization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
- Newton’s Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
- Gauss-Newton Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
- Neural Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
- Training Neural Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
5 Classification 107
- Generative vs. Discriminative Classification . . . . . . . . . . . . . . . . . . . . . . . 107
- Least Squares Support Vector Machine . . . . . . . . . . . . . . . . . . . . . . . . . . 109
- Logistic Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
- Gaussian Discriminant Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
- Support Vector Machines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
- Duality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
- Nearest Neighbor Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
6 Clustering 151
- K-means Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
- Mixture of Gaussians . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
- Expectation Maximization (EM) Algorithm . . . . . . . . . . . . . . . . . . . . . . . 156
7 Decision Tree Learning 163
- Decision Trees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
- Random Forests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
- Boosting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
8 Deep Learning 175
- Convolutional Neural Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
- CNN Architectures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
- Visualizing and Understanding CNNs . . . . . . . . . . . . . . . . . . . . . . . . . . 185
I hope they will add sections on Ensemble Methods (combining multiple techniques), cross-validation, and feature selection, and then it will cover pretty much everything that the beginner should know. You can download this material (PDF document) here.
Related Books
Other popular free books, all written by top experts in their fields, include Foundations of Data Science published by Microsoft’s ML Research Lab in 2018, and Statistics: New Foundations, Toolbox, and Machine Learning Recipes published by Data Science Central in 2019. Other free DSC books (more to come very soon) include:
){kind=link}