
Summary: In the literal blink of an eye, image-based AI has gone from high cost, high risk projects to quick and reasonably reliable. C-level execs looking for AI techniques to exploit need to revisit their assumptions and move these up the list. Here’s what’s changed.
For data scientists these are miraculous times. We tend to think of miracles as something that occurs instantaneously but in our world that’s not quite so. Still the rate of change in deep learning, particularly in image recognition is mind boggling and way up there on the miraculous scale.
Buried deep in the fascinating charts and graphs of the 2018 AI Index Annual Report is this chart.
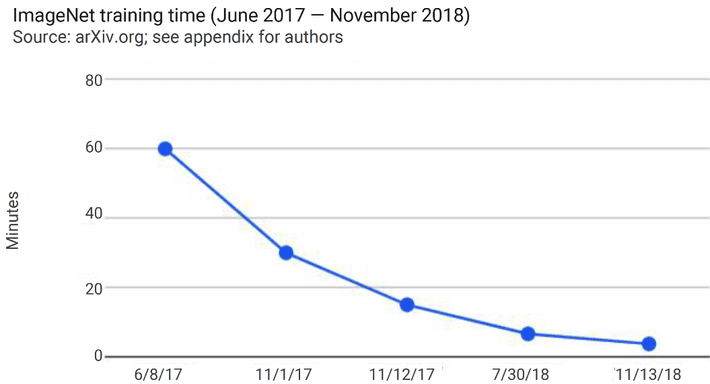
In a year and a half, the time required to train a CNN network in the ImageNet competition has fallen from about one hour to less than 4 minutes. That’s a 16X improvement in 18 months. (Keep in mind that the ImageNet dataset is comprised of 14 million labeled images in 20,000 categories.)
That’s remarkable in itself, but compare this to our experience with training CNNs in December 2015, 36 months back when automated image detection in the ImageNet competition first exceeded human performance. Roughly another 18 months before this chart begins Microsoft researchers used an extraordinary 152 layer CNN which was five times the size of any previous system to beat the human benchmark for the first time (97% for the CNN, 95% for humans).
That effort took Microsoft many months of trial and error as they pioneered the techniques that led to better-than-human accuracy in image recognition. And while we can’t fairly compare all that experimental time to today’s benchmark of less than 4 minutes, it’s accurate to say that in 2016 training a CNN was a task acknowledged to take weeks if not months, and consume compute resources valued in the tens-of-thousands of dollars for a single model, if it managed to train at all.
So 16X doesn’t begin to express how far we’ve come. For the sake of picking a starting point let’s try about 40 hours of compute time then, now reduced to 4 minutes or about a 600X improvement.
It’s worth looking at what factors brought us here. There are three.
Tuning the CNN
Two years ago, setting up a CNN was still largely trial and error. Enough simply wasn’t known about picking a starting point of layers, loss functions, node interconnections, and starting weights. Much less how varying any one of these factors would impact the others once launched.
 Thanks to literally thousands of data scientists piling into deep learning at both the research and application level a much better understanding of best hyperparameter tuning has been put into practice.
Thanks to literally thousands of data scientists piling into deep learning at both the research and application level a much better understanding of best hyperparameter tuning has been put into practice.
Our understanding has advanced so far that Microsoft, Google, and several startups offer fully automated deep learning platforms that are all but fool proof.
In much the same way that automated selection and hyperparameter tuning of machine learning algorithms has deemphasized the importance of deep technical knowledge of the algorithms themselves, the same has happened for deep learning. For some time now (OK, that means at least a year) we’ve been more concerned about adequate labeled training data than about the mechanics of the CNNs themselves.
Chips Are Increasingly Where It’s At
Our readers are most likely aware of the many software advancements that have made the techniques around implementing CNNs easier and faster. Fewer may be aware that an equal or greater share of the credit for this acceleration belongs to the chipmakers. Increasingly all types of AI mean customized silicon optimized for the many different needs of deep learning.
In fact, the dedicated chip track has been evolving as long as CNNs have been the algorithm of choice for image recognition given the much longer development time and much greater capital required for such an effort.
While the first great leap in speed and efficiency came from utilizing GPUs and FPGAs, by 2016 Google had announced its own customized chip, the TPU (Tensor Processing Unit) optimized for its TensorFlow platform. TensorFlow has captured by far the largest share of AI developers and the proprietary TPU chip and platform have given Google ownership of the largest share of AI cloud revenue.
Essentially all the other majors, both existing chipmakers and AI platform developers are following suit including Intel, NVidia, Microsoft, Amazon, IBM, Qualcomm, and a large cohort of startups.
This would seem to be too many competitors for this specialized area but image recognition, and more broadly deep learning-based AI applications have many ways in which to specialize.
- For specific applications like facial recognition.
- For the tradeoff between high computation performance versus inference.
- Embedded applications needing low power consumption versus enterprise applications needing high power.
- Ultra-low power for IoT devices and mid-range power for automotive applications.
Where GPUs and FPGAs are programmable, the push is specifically to AI-embedded silicon with dedicated niche applications. All these have contributed to the increase in speed and reliability of results in CNN image recognition applications.
Transfer Learning
The final contributor is Transfer Learning, though in this specific case it was not used in the ImageNet competition.
The central concept is to use a more complex but successful pre-trained CNN model to ‘transfer’ its learning to your more simplified (or equally but not more complex) problem.
The existing successful pre-trained model has two important attributes:
- Its tuning parameters have already been tested and found to be successful, eliminating the experimentation around setting the
- The earlier or shallower layers of a CNN are essentially learning the features of the image set such as edges, shapes, textures and the like. Only the last one or two layers of a CNN are performing the most complex tasks of summarizing the vectorized image data into the classification data for the 10, 100, or 1,000 different images they are supposed to identify. These earlier shallow layers of the CNN can be thought of as featurizers, discovering the previously undefined features on which the later classification is based.
In simplified TL the pre-trained transfer model is simply chopped off at the last one or two layers. Once again, the early, shallow layers are those that have identified and vectorized the features and typically only the last one or two layers need to be replaced.
The output of the truncated ‘featurizer’ front end is then fed to a standard classifier like an SVM or logistic regression to train against your specific images.
The resulting transfer CNN can be trained with as few as 100 labeled images per class, but as always, more is better. This addresses the problem of the availability and cost of creating sufficient labeled training data and also greatly reduces the compute time and accelerates the overall project.
Large libraries of pretrained CNNs that can be used to ‘donate’ their front ends are available as open source from the major cloud providers hoping to capture the cloud compute revenue, and also from academic sources.
A Note about the 2018 AI Index Annual Report
This annual report is the work of Stanford’s Human-Centered AI Institute who for the last few years has been publishing the encyclopedic ‘AI Index’. To see how the key chart above was developed and the sources that were used see the report and its equally informative appendices.
Your Strategic Business Assumptions May Need to Change
If you’re a C-level executive looking at reasonable applications of AI to leverage in your newly digital enterprise you need to be careful who you talk to. Not every data scientist will be aware how rapidly image-based AI is becoming better, faster, and cheaper.
24 months ago I was still advising that image-based AI was a bleeding edge technique and a project with high costs and a high risk of failure. In the blink of an eye that’s changed.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}