
Background
When I was teaching a session on AI at an MBA program at the London School of Economics, I thought of explaining AI from the perspective of the life-cycle of Data. This explanation is useful because more people are used to data (than to code). I welcome comments on this approach. Essentially, we consider how data is used and transformed for AI and what are its implications.
This could be an extensive discussion – hence the blog below presents a starting point
The lifecycle of Data for AI
The basic stages in the Data Science lifecycle are as below
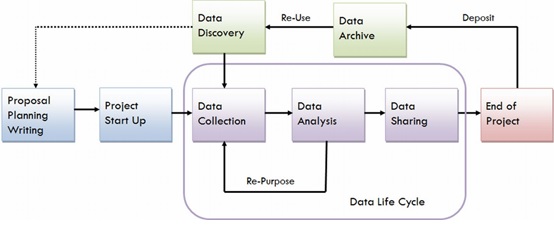
Source https://data.library.virginia.edu/data-management/lifecycle/
The CRISP-DM methodology is most commonly used in Data Science
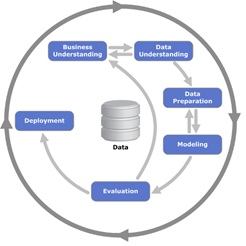
Source https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_d…
CRISP-DM in turn is based on the wider idea of Mathematical / Statistical modelling
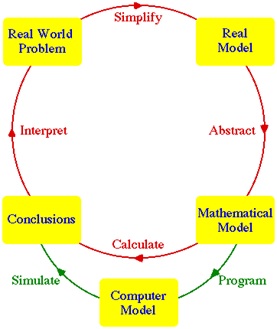
Source http://www.indiana.edu/~hmathmod/modelmodel.html
Today, we see other evolution of the Data cycle life-cycle – for example The Team Data Science Process lifecycle which can be seen to have evolved from CRISP-DM
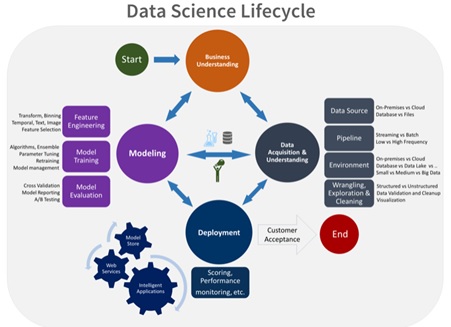
How is Data used in Machine Learning and Deep Learning
A machine learning algorithm is an algorithm that is able to learn from data. In this context, the definition of learning is provided by Mitchell (1997) which says that “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P , if its performance at tasks in T , as measured by P , improves with experience E.”
Machine learning can be seen as a form of applied statistics with increased use of computing and data to statistically estimate complicated functions. Machine learning allows us to tackle tasks that are too difficult to solve with fixed programs which are written manually. Instead, machine learning programs depend on learning from patterns of data to make new predictions. Deep learning is a specific kind of machine learning – which is characterised by automatic feature detection. Deep learning can be seen as a way to overcome the limitations of machine learning in their ability to generalise. These challenges include managing high dimensionality, Local Constancy and Manifold Learning. Refer Deep Learning Book – Goodfellow, Bengio et al
The Lifecycle of Data – How AI works with stored data
We can understand AI from the standpoint of how AI works with stored data.
Edge:
Increasingly, with IoT a large amount of data will live and die at the edge i.e. .it will not make it to the cloud except in an aggregated form. This implies a more complex mode of deployment where the model will be trained in the cloud and deployed to the edge using a container strategy like Docker
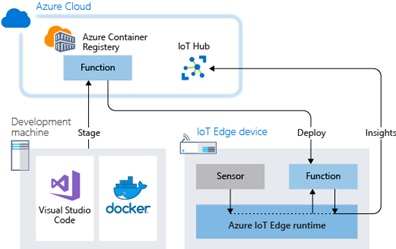
Source: https://docs.microsoft.com/en-us/azure/iot-edge/tutorial-deploy-fun…
Stream mode:
Data could also be consumed and processed in a stream mode – for example with kafka as below.
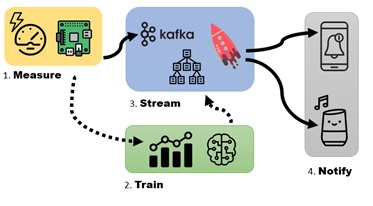
Source: https://medium.com/@simon.aubury/machine-learning-kafka-ksql-stream…
NoSQL:
Data can be stored in NoSQL databases like MongoDB or it can be stored in SQL format even when it is Time series
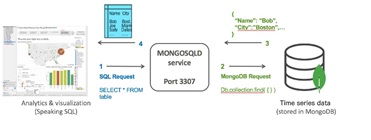
Image source: https://www.mongodb.com/blog/post/time-series-data-and-mongodb-part…
Data lake:
Ultimately, for an Enterprise, the Data will reside in a Data lake. A data lake is a centralised repository that allows storage of all structured and unstructured data at any scale. Unlike a Data Warehouse, Data Lakes store data in a raw format. For this reason, it is potentially easier to run analytics on the Data lake
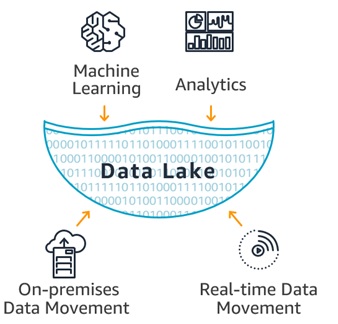
Image source: https://aws.amazon.com/big-data/datalakes-and-analytics/what-is-a-d…
we are seeing newer forms of storage such as Storage Class memory
Devops: The idea of Devops is tied in increasingly with AI models blurring the boundaries between data and function
https://azure.microsoft.com/en-gb/blog/introducing-azure-devops/
Automl – Automated machine learning is also increasingly common with the idea of rapidly building and prototyping AI models
What analogies can we think of?
The above discussion shows the complexity of how AI engages with data.
I was trying to simplify this model by suggesting non-technical analogies.
- Data nurseries — where new data is created in big amounts – think about the analogy with star nurseries in space. This idea could apply to IoT, Video cameras etc.
- Data graveyard – Similar to much of Big Data, the data lake idea has face criticism. The data lake reminds me of the mythical Elephant graveyard (best depicted in the movie lion king)
What other non-technical analogies can you think of? I will try to expand on this idea of explaining AI from a life-cycle of data more in future posts.
We could create life-cycle diagrams for each use case where data is created and stored after processing for example for fraud detection, explainability etc
Comments welcome
{kind=link}