
 As artificial intelligence apes the human speech, vision, and mind patterns, the domain of NLP is buzzing with some key developments in place.
As artificial intelligence apes the human speech, vision, and mind patterns, the domain of NLP is buzzing with some key developments in place.
NLP is one of the most crucial components for structuring a language-focused AI program, for example, the chatbots which readily assist visitors on the websites and AI-based voice assistants or VAs. NLP as the subset of AI enables machines to understand the language text and interpret the intent behind it by various means. A hoard of other tasks is being added via NLP like sentiment analysis, text classification, text extraction, text summarization, speech recognition, and auto-correction, etc.
However, NLP is being explored for many more tasks. There have been many advancements lately in the field of NLP and also NLU (natural language understanding) which are being applied on many analytics and modern BI platforms. Advanced applications are using ML algorithms with NLP to perform complex tasks by analyzing and interpreting a variety of content.
About NLP and NLP tasks
Apart from leveraging the data produced on social media in the form of text, image, video, and user profiles, NLP is working as a key enabler with the AI programs. It is heightening the application of Artificial Intelligence programs for innovative usages like speech recognition, chatbots, machine translation, and OCR or optical character recognition. Often the capabilities of NLP are turning the unstructured content into useful insights to predict the trends and empower the next level of customer-focused product solutions or platforms.
Among many, NLP is being utilized for programs that require to apply techniques like:
- Machine translation: Using different methods for processing like statistical, or rule-based, with this technique, one natural language is converted into another without impacting its fluency and meaning to produce text as result.
- Parts of speech tagging: NLP technique of NER or named entity recognition is key to establish the relation between words. But before that, the NLP model needs to tag parts of speech or POS for evaluating the context. There are multiple methods of POS tagging like probabilistic or lexical.
- Information grouping: An NLP model which requires to classify documents on the basis of language, subject, type of document, time or author would require labeled data for text classification.
- Named entity recognition: NER is primarily used for identifying and categorizing text on the basis of name, time, location, company, and more for content classification in programs for academic research, lab reports analysis, or for customer support practices. This often involves text summarization, classification, and extraction.
- Virtual assistance: Specifically for Chatbots and virtual assistants, NLG or natural language generation is a crucial technique that enables the program to respond to queries using appropriate words and sentence structures.
All about the BERT framework
An open-source machine learning framework, BERT, or bidirectional encoder representation from a transformer is used for training the baseline model of NLP for streamlining the NLP tasks further. This framework is used for language modeling tasks and is pre-trained on unlabelled data. BERT is particularly useful for neural network-based NLP models, which make use of left and right layers to form relations to move to the next step.
BERT is based on Transformer, a path-breaking model developed and adopted in 2017 to identify important words to predict the next word in a sentence of a language. Toppling the earlier NLP frameworks which were limited to smaller data sets, the Transformer could establish larger contexts and handle issues related to the ambiguity of the text. Following this, the BERT framework performs exceptionally on deep learning-based NLP tasks. BERT enables the NLP model to understand the semantic meaning of a sentence The market valuation of XX firm stands at XX%, by reading bi-directionally (right to left and left to right) and helps in predicting the next sentence.
In tasks like sentence pair, single sentence classification, single sentence tagging, and question answering, the BERT framework is highly usable and works with impressive accuracy. BERT involves two-stage applications unsupervised pre-training and supervised fine-tuning. It is pre-trained on MLM (masked language model) and NSP (next sentence prediction). While the MLM task helps the framework to learn using the context in right and left layers through unmasking the masked tokens; the NSP task helps in capturing the relation between two sentences. In terms of the technical specifications required for the framework, the pre-trained models are available as Base (12 layers, 786 hidden layers, 12 self attention head, and 110 m parameters) and Large (24 layers, 1024 hidden layer, 16 self attention head, and 340 m parameters).
BERT creates multiple embeddings around a word to find and relate with the context. The input embeddings of BERT include token, segment, and position components.
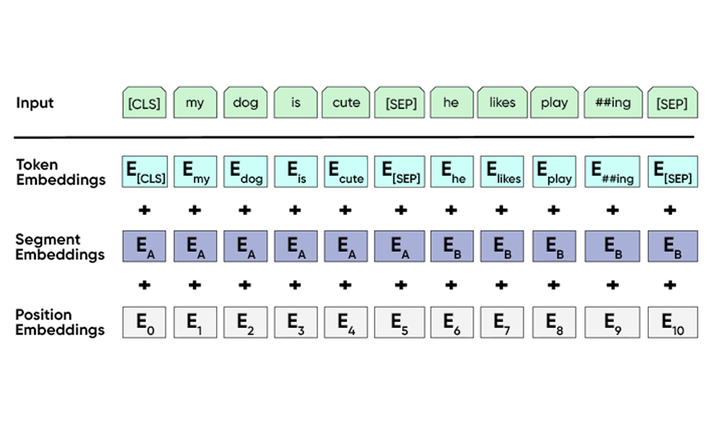
Since 2018, reportedly the BERT framework is in extensive usage for various NLP models and in deep language learning algorithms. As Bert is open source, there are several variants that have also been in usage, often delivering better results than the base framework such as ALBERT, HUBERT, XLNet, VisualBERT, RoBERTA, MT-DNN, etc.
What makes BERT so useful for NLP?
When Google introduced and open-sourced the BERT framework, it produced highly accurate results in 11 languages simplifying tasks such as sentiment analysis, words with multiple meanings, and sentence classification. Again in 2019, Google utilized the framework for understanding the intent of search queries on its search engine. Following this, it is being widely applied for tasks like answering questions on SquAD (Stanford question answering dataset), GLUE (Generational language understanding evaluation), and NQ datasets, for product recommendation based on product review, deeper sentiment analysis based on user intent.
By the end of 2019, the framework was adopted for almost 70 languages used across different AI programs. BERT helped solve various complexities of NLP models built with a focus on natural languages spoken by humans. Where previous NLP techniques were required to train on repositories of large unlabeled data, BERT is pre-trained and works bi-directionally to establish contexts and predict. This mechanism increases the capability of NLP models further which are able to execute data without requiring it to be sequenced and organized in order. In addition to this, the BERT framework performs exceptionally for NLP tasks surrounding sequence-to-sequence language development and natural language understanding (NLU) tasks.
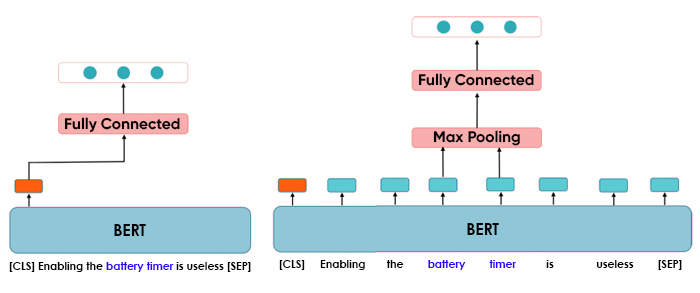
Endnote:
BERT has helped in saving a lot of time, cost, energy, and infrastructural resources by emerging as the sole enabler in place of building a distinguished language processing model from scratch. By being open-source, it has proved to be far more efficient and scalable than previous language models Word2Vec and Glove. BERT has outperformed human accuracy levels by 2% and has scored 80% on GLUE score and almost 93.2% accuracy on SquAD 1.1. BERT can be fine-tuned as per user specification while it is adaptable for any volume of content.
The framework has been a valuable addition to NLP tasks by introducing pre-trained language models while proving as a reliable source to execute NLU and NLG tasks through the availability of its multiple variants. The BERT framework definitely provides the opportunity to watch out for some exciting New Development in NLP in the near future. Originally published Click
{kind=link}