
Data is almost everywhere. The amount of digital data that currently exists is now growing at a rapid pace. The number is doubling every two years and it is completely transforming our basic mode of existence. According to a paper from IBM, about 2.5 billion gigabytes of data had been generated on a daily basis in the year 2012. Another article from Forbes informs us that data is growing at a pace which is faster than ever. The same article suggests that by the year 2020, about 1.7 billion of new information will be developed per second for all the human inhabitants on this planet. As data is growing at a faster pace, new terms associated with processing and handling data are coming up. These include data science, data mining and machine learning. In the following section- we will give you a detailed insight on these terms.
What is data science?
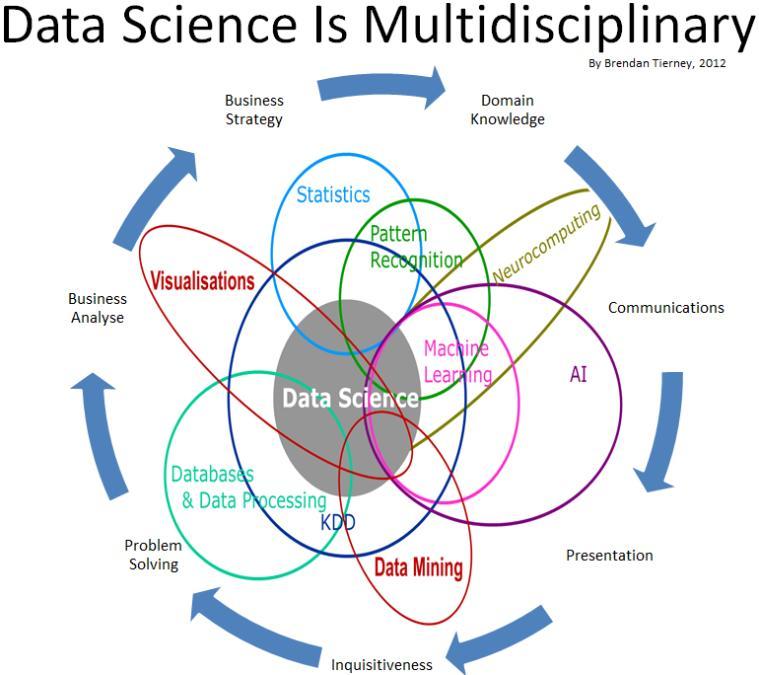
Data Science deals with both structured and unstructured data. It is a field that includes everything that is associated with the cleansing, preparation and final analysis of data. Data science combines the programming, logical reasoning, mathematics and statistics. It captures data in the most ingenious ways and encourages the ability of looking at things with a different perspective. Likewise, it also cleanses, prepares and aligns the data. To put it more simply, data science is an umbrella of several techniques that are used for extracting the information and the insights of data. Data scientists are responsible for creating the data products and several other data based applications that deal with data in such a way that conventional systems are unable to do.
What is data mining?
Data mining is simply the process of garnering information from huge databases that was previously incomprehensible and unknown and then using that information to make relevant business decisions. To put it more simply, data mining is a set of various methods that are used in the process of knowledge discovery for distinguishing the relationships and patterns that were previously unknown. We can therefore term data mining as a confluence of various other fields like artificial intelligence, data room virtual base management, pattern recognition, visualization of data, machine learning, statistical studies and so on. The primary goal of the process of data mining is to extract information from various sets of data in an attempt to transform it in proper and understandable structures for eventual use. Data mining is thus a process which is used by data scientists and machine learning enthusiasts to convert large sets of data into something more usable.
What is machine learning?
Machine learning is kind of artificial intelligence that is responsible for providing computers the ability to learn about newer data sets without being programmed via an explicit source. It focuses primarily on the development of several computer programs that can transform if and when exposed to newer sets of data. Machine learning and data mining follow the relatively same process. But of them might not be the same. Machine learning follows the method of data analysis which is responsible for automating the model building in an analytical way. It uses algorithms that iteratively gain knowledge from data and in this process; it lets computers find the apparently hidden insights without any help from an external program. In order to gain the best results from data mining, complex algorithms are paired with the right processes and tools.
What is the difference between these three terms?
As we mentioned earlier, data scientists are responsible for coming up with data centric products and applications that handle data in a way which conventional systems cannot. The process of data science is much more focused on the technical abilities of handling any type of data. Unlike data mining and data machine learning it is responsible for assessing the impact of data in a specific product or organization.
While data science focuses on the science of data, data mining is concerned with the process. It deals with the process of discovering newer patterns in big data sets. It might be apparently similar to machine learning, because it categorizes algorithms. However, unlike machine learning, algorithms are only a part of data mining. In machine learning algorithms are used for gaining knowledge from data sets. However, in data mining algorithms are only combined that too as the part of a process. Unlike machine learning it does not completely focus on algorithms.
Source: Firmex.com
{kind=link}