
Below are some extracts from an interesting Quora discussion on this topic.
Quotes:
- The gradient descent way: You look around your feet and no farther than a few meters from your feet. You find the direction that slopes down the most and then walk a few meters in that direction. Then you stop and repeat the process until you can repeat no more. This will eventually lead you to the valley!
- The Newton way: You look far away. Specifically you look around in a way such that your line of sight is tangential to the mountain surface where you are. You find the point in your line of sight that is the lowest and using your awesome spiderman powers …you jump to that point! Then you repeat the process until you can repeat no more!”
Another contributor wrote:
The Newton method is obtained by replacing the Direction matrix in the steepest decent update equation by inverse of the Hessian. The steepest decent algorithm,
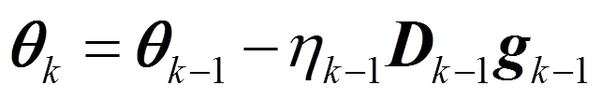
where theta is the vector of independent parameters, D is the direction matrix and g represents the gradient of the cost functional I(theta) not shown in the equation.
The gradient decent is very slow. For convex cost functionals a faster method is the Newtons method given below:
Above equation for Newtons method Becomes,
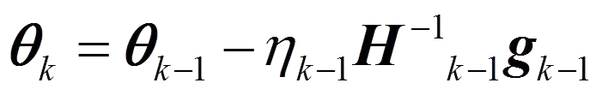
where H is the hessian
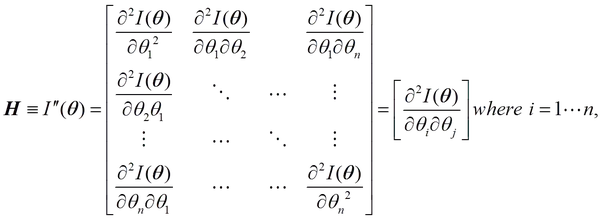
If the first and second derivatives of a function exist then strict convexity implies that the Hessian matrix is positive definite and vice versa.
Drawback of Newton method:
- As pointed out earlier the Hessian is guaranteed to be positive definite only for convex loss functions. If the loss function is not convex the Hessian as a direction matrix may make the equation above not point in the steepest decent direction.
- Computation of Hessian and its inverses are time consuming processes. Far from the optimum the Hessian may become ill conditioned.
To prevent these problems several modifications that approximate the hessian and its inverse have been developed
Read the full discussion here.
{kind=link}