
The following problems appeared in the assignments in the Udacity course Deep Learning (by Google). The descriptions of the problems are taken from the assignments (continued from the last post).
Classifying the letters with notMNIST dataset with Deep Network
Here is how some sample images from the dataset look like:

Let’s try to get the best performance using a multi-layer model! (The best reported test accuracy using a deep network is 97.1%).
- One avenue you can explore is to add multiple layers.
- Another one is to use learning rate decay.
Learning L2-Regularized Deep Neural Network with SGD
The following figure recapitulates the neural network with a 3 hidden layers, the first one with 2048 nodes, the second one with 512 nodes and the third one with with 128nodes, each one with Relu intermediate outputs. The L2 regularizations applied on the lossfunction for the weights learnt at the input and the hidden layers are λ1, λ2, λ3 and λ4, respectively.
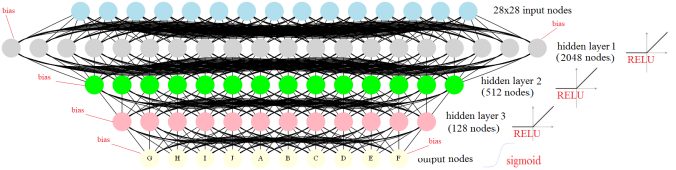
The next 3 animations visualize the weights learnt for 400 randomly selected nodes from hidden layer 1 (out of 2096 nodes), then another 400 randomly selected nodes from hidden layer 2 (out of 512 nodes) and finally at all 128 nodes from hidden layer 3, at different steps using SGD and L2 regularized loss function (with λ1 = λ2 = λ3 = λ4
=0.01). As can be seen below, the weights learnt are gradually capturing (as the SGD steps increase) the different features of the letters at the corresponding output neurons.



Results with SGD
Initialized
Validation accuracy: 27.6%
Minibatch loss at step 0: 4.638808
Minibatch accuracy: 7.8%
Validation accuracy: 27.6%
Validation accuracy: 86.3%
Minibatch loss at step 500: 1.906724
Minibatch accuracy: 86.7%
Validation accuracy: 86.3%
Validation accuracy: 86.9%
Minibatch loss at step 1000: 1.333355
Minibatch accuracy: 87.5%
Validation accuracy: 86.9%
Validation accuracy: 87.3%
Minibatch loss at step 1500: 1.056811
Minibatch accuracy: 84.4%
Validation accuracy: 87.3%
Validation accuracy: 87.5%
Minibatch loss at step 2000: 0.633034
Minibatch accuracy: 93.8%
Validation accuracy: 87.5%
Validation accuracy: 87.5%
Minibatch loss at step 2500: 0.696114
Minibatch accuracy: 85.2%
Validation accuracy: 87.5%
Validation accuracy: 88.3%
Minibatch loss at step 3000: 0.737464
Minibatch accuracy: 86.7%
Validation accuracy: 88.3%
Test accuracy: 93.6%
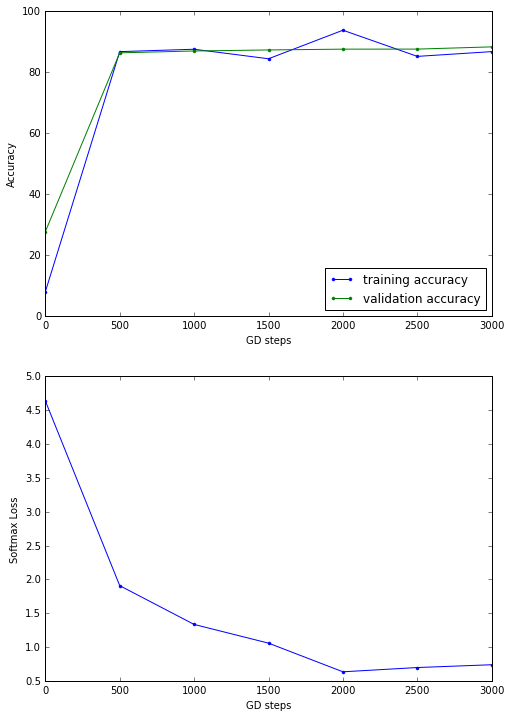
Batch size = 128 and Drop-out rate = 0.8 for training dataset are used for the above set of experiments, with learning decay. We can play with the hyper-parameters to get better test accuracy.
Convolution Neural Network
Previously we trained fully connected networks to classify notMNIST characters. The goal of this assignment is to make the neural network convolutional.
Let’s build a small network with two convolutional layers, followed by one fully connected layer. Convolutional networks are more expensive computationally, so we’ll limit its depth and number of fully connected nodes. The below figure shows the simplified architecture of the convolution neural net.
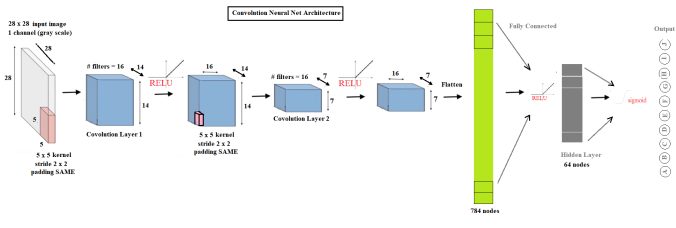
As shown above, the ConvNet uses:
- 5×5 kernels
- 16 filters
- 2×2 strides
- SAME padding
- 64 hidden nodes
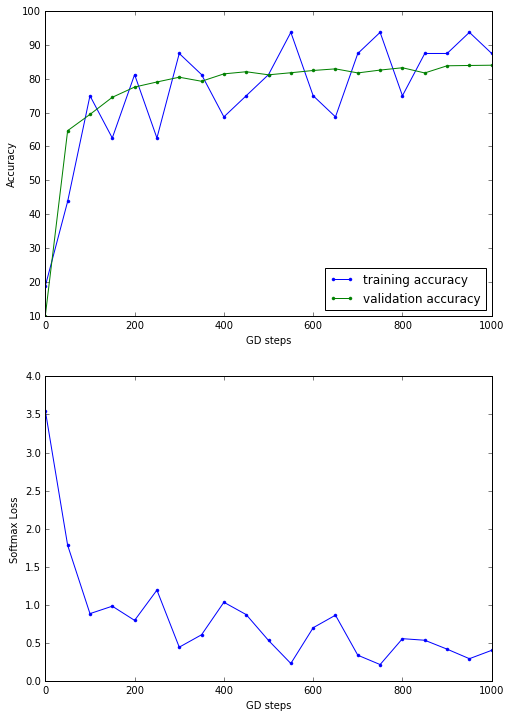
Results
Initialized
Minibatch loss at step 0: 3.548937
Minibatch accuracy: 18.8%
Validation accuracy: 10.0%
Minibatch loss at step 50: 1.781176
Minibatch accuracy: 43.8%
Validation accuracy: 64.7%
Minibatch loss at step 100: 0.882739
Minibatch accuracy: 75.0%
Validation accuracy: 69.5%
Minibatch loss at step 150: 0.980598
Minibatch accuracy: 62.5%
Validation accuracy: 74.5%
Minibatch loss at step 200: 0.794144
Minibatch accuracy: 81.2%
Validation accuracy: 77.6%
Minibatch loss at step 250: 1.191971
Minibatch accuracy: 62.5%
Validation accuracy: 79.1%
Minibatch loss at step 300: 0.441911
Minibatch accuracy: 87.5%
Validation accuracy: 80.5%
… … …
Minibatch loss at step 900: 0.415935
Minibatch accuracy: 87.5%
Validation accuracy: 83.9%
Minibatch loss at step 950: 0.290436
Minibatch accuracy: 93.8%
Validation accuracy: 84.0%
Minibatch loss at step 1000: 0.400648
Minibatch accuracy: 87.5%
Validation accuracy: 84.0%
Test accuracy: 90.3%
The following figures visualize the feature representations at different layers for the first 16 images during training:




Convolution Neural Network with Max Pooling
The convolutional model above uses convolutions with stride 2 to reduce the dimensionality. Replace the strides by a max pooling operation of stride 2 and kernel size 2. The below figure shows the simplified architecture of the convolution neural net with MAX Pooling layers.
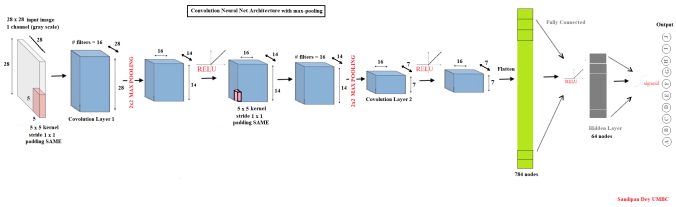
As shown above, the ConvNet uses:
- 5×5 kernels
- 16 filters
- 1×1 strides
- 2×2 Max-pooling
- SAME padding
- 64 hidden nodes
Results
Initialized
Minibatch loss at step 0: 4.934033
Minibatch accuracy: 6.2%
Validation accuracy: 8.9%
Minibatch loss at step 50: 2.305100
Minibatch accuracy: 6.2%
Validation accuracy: 11.7%
Minibatch loss at step 100: 2.319777
Minibatch accuracy: 0.0%
Validation accuracy: 14.8%
Minibatch loss at step 150: 2.285996
Minibatch accuracy: 18.8%
Validation accuracy: 11.5%
Minibatch loss at step 200: 1.988467
Minibatch accuracy: 25.0%
Validation accuracy: 22.9%
Minibatch loss at step 250: 2.196230
Minibatch accuracy: 12.5%
Validation accuracy: 27.8%
Minibatch loss at step 300: 0.902828
Minibatch accuracy: 68.8%
Validation accuracy: 55.4%
Minibatch loss at step 350: 1.078835
Minibatch accuracy: 62.5%
Validation accuracy: 70.1%
Minibatch loss at step 400: 1.749521
Minibatch accuracy: 62.5%
Validation accuracy: 70.3%
Minibatch loss at step 450: 0.896893
Minibatch accuracy: 75.0%
Validation accuracy: 79.5%
Minibatch loss at step 500: 0.610678
Minibatch accuracy: 81.2%
Validation accuracy: 79.5%
Minibatch loss at step 550: 0.212040
Minibatch accuracy: 93.8%
Validation accuracy: 81.0%
Minibatch loss at step 600: 0.785649
Minibatch accuracy: 75.0%
Validation accuracy: 81.8%
Minibatch loss at step 650: 0.775520
Minibatch accuracy: 68.8%
Validation accuracy: 82.2%
Minibatch loss at step 700: 0.322183
Minibatch accuracy: 93.8%
Validation accuracy: 81.8%
Minibatch loss at step 750: 0.213779
Minibatch accuracy: 100.0%
Validation accuracy: 82.9%
Minibatch loss at step 800: 0.795744
Minibatch accuracy: 62.5%
Validation accuracy: 83.7%
Minibatch loss at step 850: 0.767435
Minibatch accuracy: 87.5%
Validation accuracy: 81.7%
Minibatch loss at step 900: 0.354712
Minibatch accuracy: 87.5%
Validation accuracy: 83.8%
Minibatch loss at step 950: 0.293992
Minibatch accuracy: 93.8%
Validation accuracy: 84.3%
Minibatch loss at step 1000: 0.384624
Minibatch accuracy: 87.5%
Validation accuracy: 84.2%
Test accuracy: 90.5%
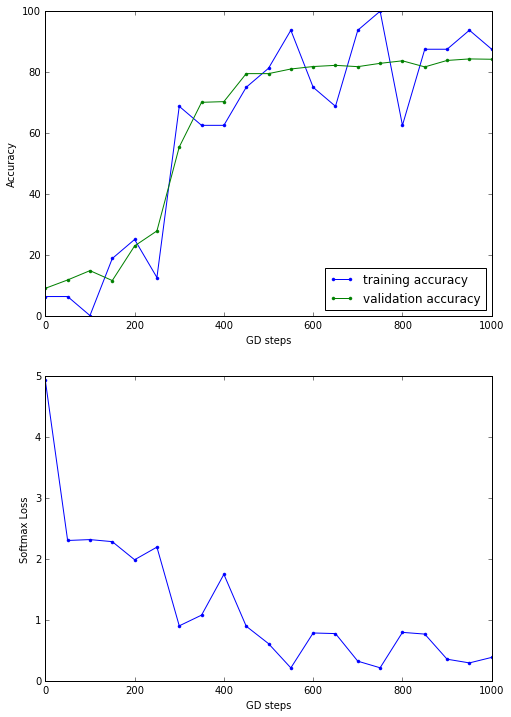
As can be seen from the above results, with MAX POOLING, the test accuracy increased slightly.
The following figures visualize the feature representations at different layers for the first 16 images during training with Max Pooling:




Till now the convnets we have tried are small enough and we did not obtain high enough accuracy on the test dataset. Next we shall make our convnet deep to increase the test accuracy.
To be continued…
{kind=link}