
Having my newsfeed cluttered with articles about Google creating an AI that beats hospitals by predicting death with 95% accuracy (or some other erroneous claim), I dug up the original research paper to fact check this wondrous new advancement. Many of said articles used this quote from the abstract (academia’s equivalent of a paperback blurb):
These models outperformed traditional, clinically used predictive models in all cases. We believe that this approach can be used to create accurate and scaleable predictions for a variety of clinical scenarios.
but what the researchers actually said in the paper was:
To the best of our knowledge, our models outperform existing EHR (Electronic Health Record) models in the medical literature.
After reviewing the paper, it was clear the erroneous claims were not from the researchers but from journalists / laypersons misinterpretation. Henceforth, I will be referring to it as Google’s NN (Neural Networks) because this over-hyped AI over-labelling must stop.
AUROC is not Accuracy
Journalists latched onto Google’s NN 0.95 score vs. the comparison 0.86 (see EWS Strawman below), as the accuracy of determining mortality. However the actual metric the researchers used is AUROC (Area Under Receiver Operating Characteristic Curve) and not a measure of predictive accuracy that indexes the difference between the predicted vs. actual like RMSE (Root Mean Squared Error) or MAPE (Mean Absolute Percentage Error). Some articles even erroneously try to explain the 0.95 as the odds ratio.
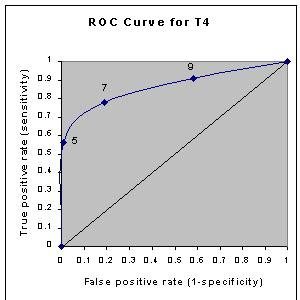
Just as the concept of significance has different meanings to statisticians and laypersons, AUROC as a measure of model accuracy does not mean the probability of Google’s NN predicting mortality accurately as journalists/laypersons have taken it to mean. The ROC (see sample above) is a plot of a model’s False Positive Rate (i.e. predicting mortality where there is none) vs. the True Positive Rate (i.e. correctly predicting mortality). A larger area under the curve (AUROC) means the model produces less False Positives, not the certainty of mortality as journalists erroneously suggest.
The researchers themselves made no claim to soothsayer abilities, what they said in the paper was:
… (their) deep learning model would fire half the number of alerts of a traditional predictive model, resulting in many fewer false positives.
Hindsight is 20/20
The articles made it appear as if Google’s NN was actively predicting mortality but that is not the case. Researchers used 80% of patient records from 2 hospitals to train the model plus additional 10% for validation. Their model accuracy was based on running the resulting model on the remaining 10% of the data. In other words, Google’s NN was trained on data where the outcomes were already known, and could be optimized to maximize those outcomes. The reliability of the model is suspect for conditions and comorbidities not sufficiently represented in those records.
As the researchers themselves put it:
Our study also has important limitations. First, it is a retro-spective study, with all of the usual limitations. Second, although it is widely believed that accurate predictions can be used to improve care, this is not a foregone conclusion … Future research is needed to determine how models trained at one site can be best applied to another site.
EWS Strawman Comparison
Hospitals do not assign survival odds (unless there is some morbid patient pool amongst healthcare professionals I am not aware of), so the researchers used EWS (Early Warning Score) as a baseline for comparison. The idea behind EWS is clinical deterioration can be seen through changes in multiple physiological measurements (e.g. blood pressure, pulse, oxygen etc.). EWS is NOT used as a predictor of mortality in practice, but an at-risk indicator understood in conjunction with patient diagnosis / assessment.
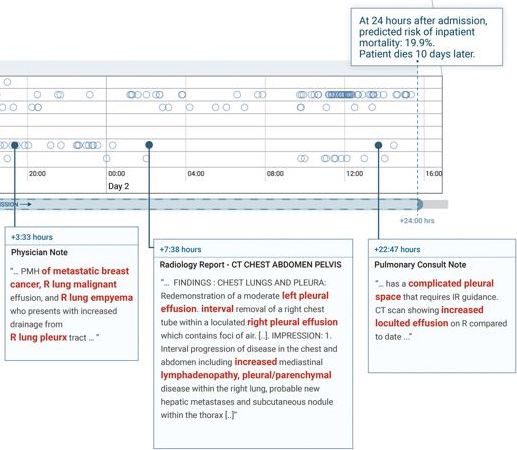
The reason why Google’s NN performs better than EWS alone (divorced from context of condition, which is not hospital practice) is likely due to it picking up key terms (e.g. “severe trauma”) in patient charts that are highly correlated to mortality. This hypothesis is partly validated by the case study where Google’s NN assigned higher mortality (19.9% vs 9.3% EWS) because it picked up terms like “malignant”, “metastatic”, and “cancer” (see diagram below) which us common folk know to be correlated with mortality.
It is doubtful if Google’s NN will be remarkably more “accurate” when pitted with expert assessments in practice vs. decontextualized diagnostic score at a 24 hour interval. I also call BS on claims that assigning mortality odds will improve healthcare – the whole point of the medical profession is helping patients beat those odds, not accepting an algorithmic fate.
People still get hit by lightning despite the odds.
And some even get hit by lightning more than once! Some articles cited the case study in the paper where after 24 hours of admission, Google’s NN gave a patient with breast cancer patient 19.9% chance of dying vs. EWS’s 9.3%. They make a big deal about the patient dying 10 days later as an indicator of the accuracy of Google’s NN merely because the odds given were 10% higher. If you were to accept these odds as literal predictive power (as the journalists have erroneously done), technically Google’s NN did no better because it gave the patient 80% survival rate which means she should have survived.
Whether 19.9% or 9.3% chance is moot, it is no different than being assigned odds of winning the lottery. Probabilities are not predictions – they are merely a rational framework to understand the chaotic world. There is no math nor model that can ascertain whether you would be the lucky / unlucky one.
Glorifying Curve-fitting
Despite the hype, deploying AI/Big Data/whatever is not a panacea for all ills. Most people do not realize Accuracy and Over-fitting are both sides of the same coin – both result in a high AUROC model. Methinks instead of the 19.9% odds Google’s NN gave the breast cancer patient, the journalists will do better to write about more meaningful contributions such as mathematical model for forecasting metastatic breast cancer survival, which was accomplished without requiring a crapload of servers and private medical data.
{kind=link}