
As I write this blog, we are still in the early stages of the coronavirus crisis. It is a scary situation which has caused hoarding, panic, fake news, lies, stock market turmoil and irrational behaviors. All indications suggest we will survive this crisis, but it is truly not one of mankind’s best moments.
But learnings abound in all situations, so let me share what data science lessons we can take away from this crisis so that we may better manage the next one.
Lesson #1: Importance of Data Quality and Transparency
One cannot make sound business or policy decisions without high quality, trusted data. And to get obtain such, we must have confidence and transparency into the sources of the data. For example, to understand the coronavirus fatality rate requires good data on the numerator (“Number of Fatalities”) and the denominator (“Number of Infected”). The numerator, “Number of Fatalities”, seems to be a fairly reliable number (though one must always be prepared to challenge the data sources because there may be reasons to withhold accurate numbers). However, the denominator, “Number of Infected”, is totally a guess at this point because most countries (including the USA) have not started to do testing at scale.
Consequently, to insinuate a fatality rate (I’ve heard numbers as high as 4.5%) is dangerous until one has more accurate and trusted numbers.
Lesson #2: How You Present the Data Matters
Careful consideration needs to be given to how one can present the data in the most unbiased way possible. For example, in Figure #1 the aggregated view of coronavirus cases (on the left) seems to indicate that the number of cases is escalating in South Korea. However, the chart on the right side of Figure #1 (new cases only) would seem to indicate that we might have actually reached a peak in the new cases in South Korea.
Note: I selected South Korea because they seem to be one country that is testing for the coronavirus at scale.
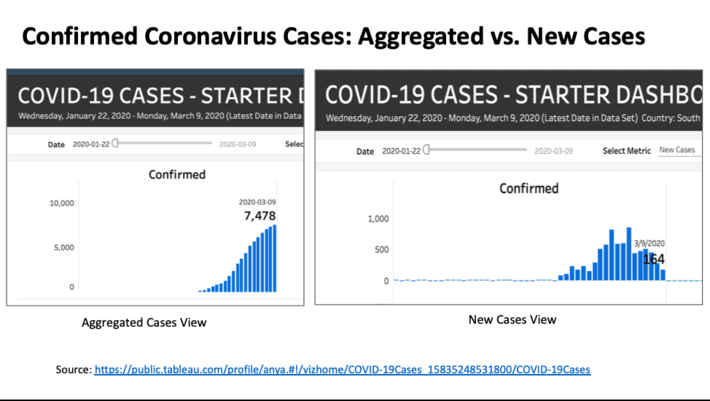
Again, to ensure that the data is presented from an unbiased perspective, be prepared to present the data in multiple ways to help the decision makers make informed decisions.
Lesson #3: Create Analytic Scores to Make Informed Decisions
One thing that we are learning is that the coronavirus impacts different people in different ways; that some folks are more susceptible to the virus than others. For example, the elderly with respiratory problems seem to be the most vulnerable to it.
Consequently, seeking out and drilling into the granular dimensions of the data is required to make informed decisions pertaining to who specifically should be quarantined, and the prioritization as to whom should receive the first vaccines when its available. One could easily create a Coronavirus Fatality Score to help make those containment, allocation and prioritization decisions.
Lesson #4: Understanding the Costs of False Positives and False Negatives
When one has incomplete data and is trying to buy some time in order to get more complete, accurate and trusted numbers, then the best thing that one can do is to make decisions based upon the costs of False Positives and False Negatives.
In the case of the coronavirus, that means:
- False Positive is incorrectly classifying a healthy person as being infected.
- False Negative is incorrectly classifying an infected person as being healthy.
So, let’s think about this.
The cost of a False Positive is that a healthy person will be quarantined and will be one of the first to receive the vaccine when it is available. The cost of being wrong in this case are the costs associated with being quarantined such as lost wages and the inconvenience associated with being quarantined. That’s not a very high cost.
One the other hand, the cost of a False Negative is that an infected person is classified as healthy and they continue to mingle in public infecting others and even potentially leading to their death and potentially the death of others. The cost of the False Negative is very high.
Consequently, it is smart of our leaders to limit large crowds and enforce some level of light quarantines until we get more complete, accurate and trusted numbers.
Summary
Everyone should take this coronavirus seriously. Not only for yourself, but for the sake of your family, friends and larger community. Until we get more complete, accurate and trusted numbers, folks are smart to be overly cautious because the costs associated with False Negatives could be catastrophic.
There are lessons to be learned from these situations as I highlighted above. And maybe the biggest lesson is that everyone needs to strive to get the facts as quickly as possible so that we can make informed decisions. Now is not the time for opinions as facts, half-truths, fake news and lies. The result is panic, and one only needs to look at the stock market to see the results of the lack of confidence in the numbers…
{kind=link}