
Much like we have Chemical Engineering and Electrical Engineering and Mechanical Engineering, it is time to formalize of field of Data Engineering. This is a special two-part series on trends and requirements leading to the formalization of the Field of Data Engineering.
“Data is the new oil…in much the same way that oil fueled economic growth in the 20th century, data will fuel economic growth in the 21st century.”
To further raise the credibility of data as the economic fuel for the next century, “The Economist” Special Report on the Data Economy asks “Are data more like oil or sunlight?”
As stated in the report:
- Originally, data were likened to oil, suggesting that data is the fuel of the future. More recently, the comparison has been with sunlight because soon, like solar rays, they will be everywhere and underlie everything.
- Like oil, data must be refined to be useful. In most cases [data] needs to be “cleansed” and “tagged”, meaning stripped of inaccuracies and marked to identify what can be seen, say, on a video.
- Before data can power AI services, it needs to be fed through algorithms, to teach them to recognize faces, steer self-driving cars and predict when jet engines need a check-up. And different data sets often need to be combined for statistical patterns to emerge. In the case of jet engines, for instance, mixing usage and weather data helps forecast wear and tear.
- Yet data has failed to become “a new asset class”, as the World Economic Forum, a conference-organizer and think-tank, predicted in 2011. Most data never changes hands and attempts to make them more tradable have not taken off.
Still, it is hard to put a definitive value on data. If data is to be the fuel for economic growth in the 21st century, don’t we need to find a way to accurately determine what data is worth? We tackled this issue in our University of San Francisco research paper “Applying Economic Concepts to Determine the Financial Value of Your Data”. The research paper highlighted the following challenge:
“There are severe limitations in valuing data in the traditional balance sheet framework. It is important that firms identify a way to account for their data. Organization’s also need a framework to address the “Rubik’s Cube” intellectual capital [citation 2] challenge regarding how to identify, align and prioritize the organization’s data and analytic investments.
To address this challenge, this research paper will put forth the following:
- A framework to facilitate the capture, refinement and sharing of the organization’s data and analytic assets, and
- A process to help organizations prioritize where to invest their precious data and analytic resources.
It is our hope that this research paper will foster new ways for organizations to re-think how they value their data and analytics from an economic and financial perspective. The concepts covered in this research paper will provide a common vocabulary and approach that enables business leadership to collaborate with the IT and Data Science organizations on identifying and prioritizing the organization’s investments.”
Formalizing the Field of Data Engineering
A recent MIT “Artificial Intelligence” podcast (thanks Matt for the pointer), Michael I. Jordan (not NBA superstar Michael J. Jordan), who is one of the most influential people in machine learning and artificial intelligence, makes a strong case for the need for a “Field of Data Engineering”, similar to the Fields of Chemical Engineering, Electrical Engineering and Civil Engineering, that integrates hard engineering concepts and principles with theoretical and practical aspects.
For example, while Electrical Engineering is more than just about the technology of electricity, the discipline also includes laws (Michael Faraday’s Law of Induction), standards, systems design, architectures, training, certification, electrical and electronic theory, mathematics and materials. This allows engineers to design electrical systems that perform specific functions and meet safety, reliability and energy efficiency requirements, and predict how these systems will behave before the system is actually built.
Whereas civil engineering and chemical engineering are built upon physics and chemistry, this new [Field of Data Engineering] will build on ideas that the preceding century gave substance to, such as information, algorithm, data, uncertainty, computing, inference, and optimization. Moreover, since much of the focus of the new discipline will be on data from and about humans, its development will require perspectives from the social sciences and humanities[1].
Today, most folks think of data engineering (including me) as the capabilities associated with traditional data preparation and data integration including data cleansing, data normalization and standardization, data quality, data enrichment, metadata management and data governance. But that definition of data engineering is insufficient to derive and drive new sources of society, business and operational value.
As Michael I. Jordan highlights:
“Will there be breakthroughs [in AI]? Yes Google, Amazon and Uber are examples of AI breakthroughs in their ability to bring value to human beings at scale in brand new ways based on data flows. But lots of these [AI] things are slightly broken because there is not an engineering field that takes the economic value in context of data at planetary scale and worries about all the externalities like privacy.
We don’t have that field, so we don’t think these things through very well. But I see that as emerging. Looking back from a hundred years that will be considered a breakthrough in its era just like electrical engineering and chemical engineering were breakthroughs.”
Wow! I am excited to hear an industry luminary like Michael I. Jordan articulate how determining the economic value in context of data is necessary to drive data and analytic breakthroughs because this is an area upon which I have been focused for several years.
Consequently, I’m going to propose the scientific “Field of Data Engineering”.
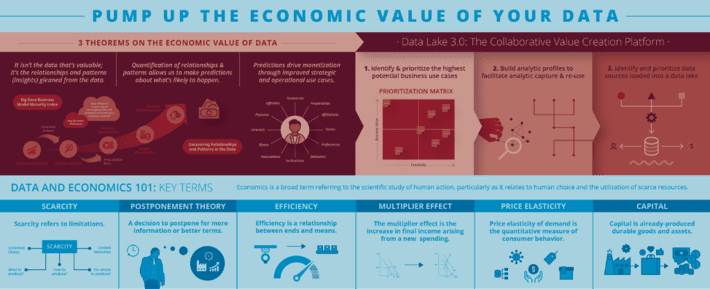
The Field of Data Engineering brings together data management (data cleansing, quality, integration, enrichment, governance) and data science (machine learning, deep learning, AI) functions and includes laws (“3 Theorems on Economic Value of Data”), standards, systems design, architectures, training, and certification, coupled with the disciplines of software engineering, mathematics, statistics, economics, ethics, security and privacy, in order to design data systems that perform specific functions and meet reliability, accuracy and ethical requirements with an understanding on how organizations can determine, propagate and manage the economic value of data and analytics.
Heck, maybe I can be considered the “Father of Data Engineering” (though I still like the “Dean of Big Data” moniker).
There are two critical economic-based principles that will underpin the field of Data Engineering:
- Principle #1: Curated data never depletes, never wears out and can be used an unlimited number of use cases at a near zero marginal cost.
- Principle #2: Digital assets appreciate, not depreciate, in value the more that they are used; that is, the more these digital assets are used, the more accurate, more reliable, more efficient and safer they become.
Principle #1: Curated Data Can Be Re-used at Zero Marginal Cost
The first principle of Data Engineering embraces the unique economic aspects of data as an asset. The analogy that data is the new oil is a great starting point, but we need to take that analogy further. Raw crude oil goes through a refinement, blending and engineering process where crude oil is transformed into more valuable asset such as gasoline, heating oil or diesel fuel. This critical process needs to be performed before downstream constituents (like you and me) can actually get value out of the oil (as gasoline, heating oil or diesel fuel). Oil in of itself, is of little consumer or industrial value. It’s only through the refinement process that we get an asset of value.
Data experiences the same economic transformation as oil. Raw data needs to go through a refinement process (cleanse, standardize, normalize, align, transform, engineer, enrich, etc.) in order to create “curated” data that dramatically increases the economic value and applicability of the data (see Figure 1).

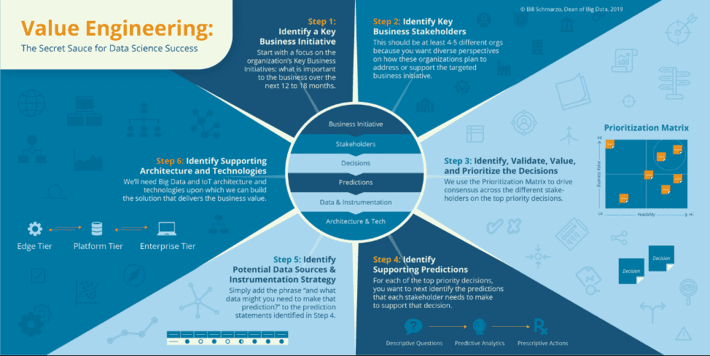
Once we have curated data, then we need a methodology for determining or attributing the economic value of data which:
- Starts with a key business initiative so that you can establish the financial basis for “prudent value” that one can use as the basis for ascertaining the economic value of the supporting data sources.
- Embraces a methodology for identifying the decisions necessary to support the targeted business initiative, and to associate a rough order magnitude of value to improving the effectiveness or outcomes from those decisions.
- Collaborates with the business users to rank the perceived value of each data source vis-à-vis the decision that they are trying to optimize.
The resulting valuation formula puts you in a position to attribute financial value to the data sources, and this financial value attribution can help organizations prioritize their data investment strategy.
Principle #2: Build Assets that Appreciate, not Depreciate, In Value
The second principle underpinning the Field of Data Engineering is that we can exploit Machine Learning, Deep Learning, Reinforcement Learning and AI to create continuously-learning, autonomous analytic assets that get more reliable, more efficient, safer, more intelligent and consequently more valuable through usage…with minimal human intervention!
It is through the accumulated usage of these analytic assets (every mile driven by vehicle, every turn of a turbine blade, every stroke by a compressor, every stop and start by a train) that drives the asset’s appreciation in value.
The ability to share the learnings from one autonomous asset with other similar autonomous assets compounds the improvements in reliability, efficiency and safety that quickly build into a substantial overall improvement. And for folks who don’t appreciate the power of compounding 1% improvements over time, a 1% improve compounded 365 times (1.01 ^365) equals a 38x overall improvement (see Figure 2).
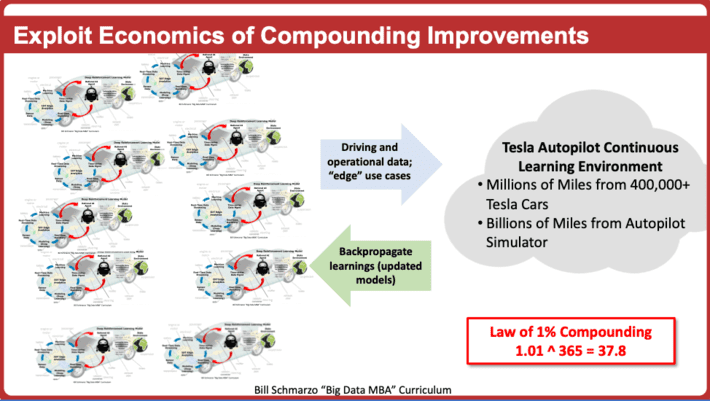
And through advancements in AI capabilities such as Transfer Learning and Federated learning, the ability to leverage the learnings from one class of analytic asset to another class of analytic asset will only accelerate and become even more prevalent and pervasive.
The Economics of Data Engineering
There are important economic principles that support this new Field of Data Engineering and driving the determination of the value of digital assets like data and analytics. For example, the Economic Value Curve is a measure of the impact independent variables have on the outcomes of the dependent variable. The challenge with the Economic Value Curve is the Law of Diminishing Returns. The Law of Diminishing Returns is a measure of the decrease in the marginal (incremental) output of a production process as the amount of a single factor of production is incrementally increased, while the amounts of all other factors of production stay constant (see Figure 3).
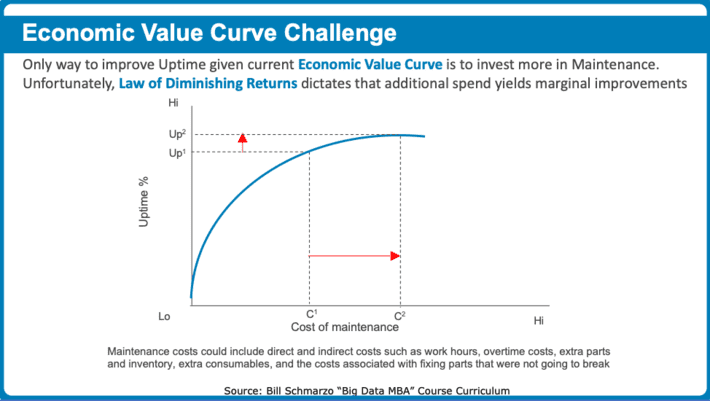
Organizations can transform their Economic Value Curve by applying predictive analytics to “Do More with Less”; that is, spend less on the inputs while getting more output. The result is a transformation of the organization’s Economic Value Curve and the ability to leverage analytics to optimally focus and prioritize one’s resources (see Figure 4).
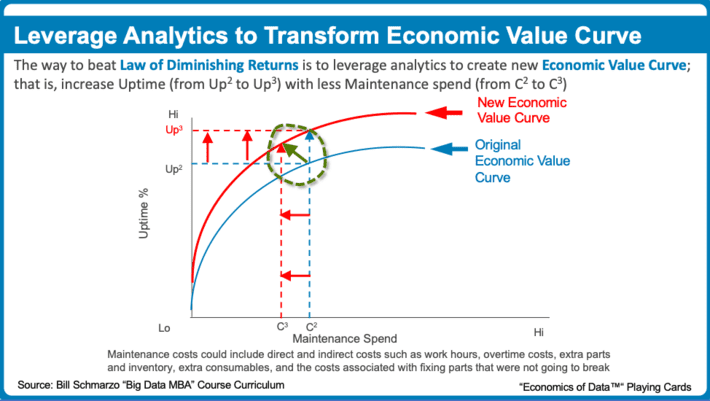
The key to “Doing More with Less” is to perform predictive analytics at the level of the individual entity (consumer, patient, operator, turbine, compressor). It is at that granular level of actionable insights can be uncovered and codified.
Finally, as I proposed in the “Schmarzo Economic Digital Asset Valuation Theorem”, the more the data and analytics get used, the more accurate, more complete, more robust, more predictive and consequently more valuable they become (see Figure 5).
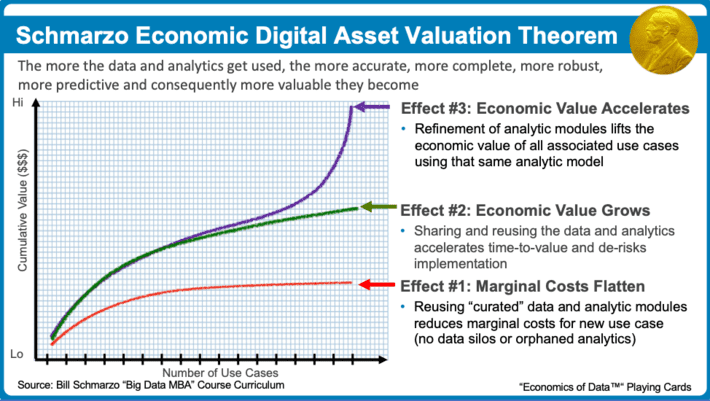
The Schmarzo Economic Digital Asset Valuation Theorem yields three effects:
- Effect #1: Marginal Costs Flatten. Reusing “curated” data and analytic modules reduces marginal costs for new use case.
- Effect #2: Economic Value Grows. Sharing and reusing the data and analytics accelerates time-to-value and de-risks implementation
- Effect #3: Economic Value Accelerates. Refinement of analytic modules lifts the economic value of all associated use cases using that same analytic model
Summary: Formalizing the Field of Data Engineering
I hope that these two blogs helped to frame the conversation and debate around this emerging field of Data Engineering. There are two critical economic-based principles that will underpin the field of Data Engineering:
- Principle #1: Curated data never depletes, never wears out and can be used an unlimited number of use cases at a near zero marginal cost.
- Principle #2: Digital assets appreciate, not depreciate, in value the more that they are used; that is, the more these digital assets are used, the more accurate, more reliable, more efficient and safer they become.
It’ll take time, debate, and new learnings for all of us to fully flesh out this new field of Data Engineering. So, strap yourself in and prepare for one “wild and crazy” adventure!
[1] “Artificial Intelligence—The Revolution Hasn’t Happened Yet” by Michael I. Jordan
{kind=link}