
Data science is a promising and exciting field, developing rapidly. The area of data science use cases and influence is continuously expanding, and the toolkit to implement these applications is growing fast. Therefore data scientists should be aware of what are the best solutions for the particular tasks.
So while many languages can be useful for a data scientist, these three remain the most popular and are developed to implement data science and machine learning solutions.
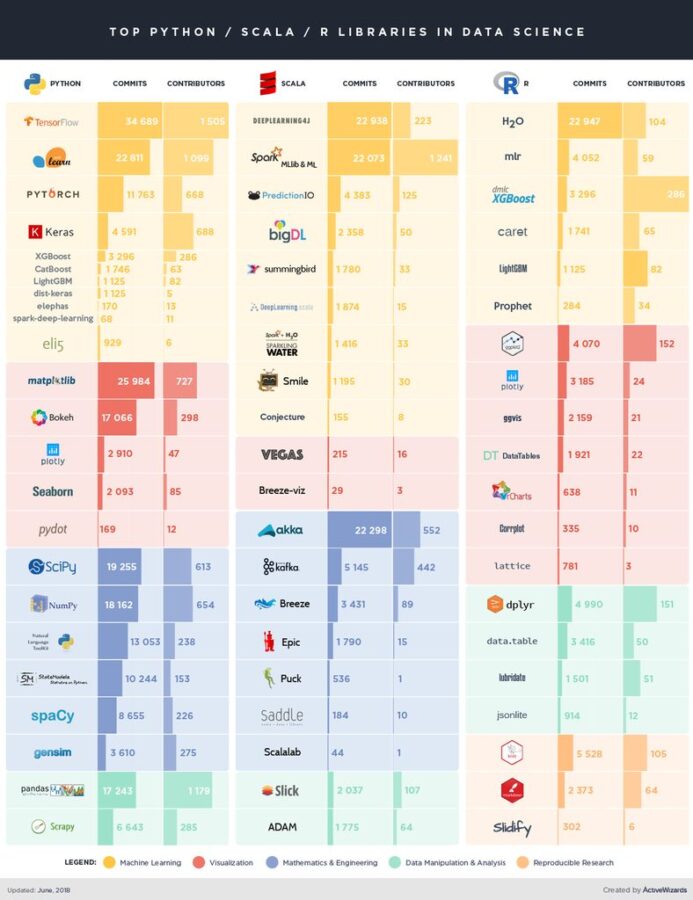
In this post, we have prepared an infographic which shows top 20 libraries in each programming language which are beneficial to data scientists and data engineers work. This selection shows how languages relate to each other as well as which libraries have similar application area. Although there are many specific fields of application of different data science packages, we want to focus on those that are perfectly suited for machine learning, visualization, mathematics and engineering, data manipulation and analysis, and reproducible research.
You can see the fields of implementation in different colors on the infographic below.
- Machine learning packages take care of the building and implementing the top machine learning algorithms, creating workflows, and in general helping to solve machine learning problems. They provide the primary toolkit for different classification, regression, and other problems.
- As an integral part of data science, data manipulation and analysis field represent libraries that carry out data scraping, ingestion, cleaning, pre-processing and other operations that allow you to “play with the data” and as a result to perform the analysis itself.
- With the help of visualization packages, you can display the data visually which is necessary for better understanding and interpreting the data. These packages contain numerous visualization charts as well as different options for representation.
- Libraries for mathematics and engineering provide the abilities to store numerical data in a convenient form and perform complicated and advanced mathematical operations and scientific computations. Also, these packages are used to process more complexly interpreted data such as text and content.
- Finally, packages for reproducible research implement the idea of creating documents which combine code, data, and content. Basically, with their help, you can produce a new work out of your project that can immediately be published.
INFOGRAPHIC (click on picture to zoom in)
Each of these languages is suitable for a specific type of tasks, besides each developer chooses the most convenient tool for himself. Often, the choice of one programming language is subjective, but below we will try to greet the strengths of each of the three described languages.
R
Primarily designed for statistical computing, R offers an excellent set of high-quality packages for statistical data collection and visualization. Another strong point for R is its well-developed tools for reproducible research. However, R can be somehow specific and is not so good when it comes to engineering and some of the more general purpose programming cases.
Python
Python is more of a general-purpose language with a rich set of libraries for a wide range of purposes. It’s as good for mathematics, engineering, and deep learning problems as for data manipulation and visualizations. This language is an excellent choice for both beginners and advanced specialists which makes it extremely popular among data scientists.
Scala
Scala is an ideal solution for working with big data. Scala and Spark combination gives you the opportunity to take the most of cluster computing. Therefore, the language has many great libraries for machine learning and engineering; however, it lacks data analysis and visualization possibilities comparing to previous languages. So, if you’re not working with big data, Python and R can show better performance than Scala.
Conclusion
These are the languages and libraries that have proved to be extremely useful in various data science use cases. Keep in mind, that the choice of programming language and the libraries that you will use, depends on specific tasks, so it’s beneficial to know what are the strong and weak sides of each of them.
Indeed, this list is not complete, many other valuable tools can and have to be examined, but it will definitely be a good starting point for your journey into data science industry.
Please, share your thoughts and ideas in the comment section and surely inform us about your favorite languages and libraries that are worth to be mentioned.
Thank you for your attention!
{kind=link}