
Summary: A major pain point is standing in the way of many companies’ ability to maximize the value of their ML/AI initiatives. The competing goals of data flexibility versus single version of the truth can only be solved with an effective data governance strategy.
 There are many reasons why companies continue to struggle with maximizing the value of their ML/AI initiatives. Among them is the mindset they’ve developed over the many years it took to become a successful mid-size or larger company. Is data something to be controlled and regulated, for example by IT in an EDW, or should it be set free to be used by as many as possible and made as flexible as possible?
There are many reasons why companies continue to struggle with maximizing the value of their ML/AI initiatives. Among them is the mindset they’ve developed over the many years it took to become a successful mid-size or larger company. Is data something to be controlled and regulated, for example by IT in an EDW, or should it be set free to be used by as many as possible and made as flexible as possible?
If you’re a data scientist, LOB manager, or analyst who reads these columns chances are you’re in the ‘set it free’ school. If IT throttles access to data then the business units may be unable to execute their ML/AI models to increase revenue or reduce cost.
On the other hand, if as a manager you’ve ever been the recipient of multiple reports where fundamental issues like sales in a particular period or the unit sales of a product disagreed then you are challenged to make an appropriate decision. On which version of the data should you rely?
We want our LOB managers to be aggressive in unleashing the value in all our data and perhaps your CEO has even written or spoken encouraging this. The unintended consequence is silos of data that may rapidly diverge from the Single Source of the Truth (SSOT). Even worse, these silos may contain valuable information that’s unavailable to others and never recaptured in the central repository.
There’s No Getting Around Data Governance
As creative and revenue creating applications of ML/AI become common we’re thrown back on an issue that no one likes to address, data governance.
Master Data Management (MDM) has been around for a long time and frankly has never gained traction. Not only is this a cumbersome layer of administration added to the already complex task of data acquisition and utilization, but candidly the tools in that kit don’t really address the problems of flexibility versus certainty. However data governance is increasingly important. The question is how to achieve it with least pain and most gain.
Defensive and Offensive Data Strategies
 Almost two years ago, a lifetime in data science, Tom Davenport introduced us to offensive and defensive data strategies. Revisiting this structure is a good starting point for understanding the type and degree of governance that’s best. It also reminds us that it is different for different companies.
Almost two years ago, a lifetime in data science, Tom Davenport introduced us to offensive and defensive data strategies. Revisiting this structure is a good starting point for understanding the type and degree of governance that’s best. It also reminds us that it is different for different companies.
In his definition, Davenport says data defense strategies are about minimizing downside risk. This encompasses regulatory compliance, data privacy, the integrity of financial reporting, and preventing fraud and theft among others. If you are in heavily regulated industries like healthcare or financial services your dominant concerns and data strategies are defensive.
If however your business is driven by constantly increasing success with sales, marketing, user experience, increased marginal profits, or creating new product and service offerings from your existing data, then your data strategy should emphasize offense.
Just from the definitions it should be evident that a defensive data strategy demands many types of control, and most importantly the inviolable SSOT.
Multiple Versions of the Truth are Allowed but Controlled
An offensive strategy emphasizes flexibility, and recognizes that different business units may need to aggregate or disaggregate that SSOT according to the needs of the particular ML model or dashboard it’s meant to drive.
Davenport calls these flexible interpretations ‘Multiple Versions of the Truth’ (MVOT). A simple example might be how we categorize suppliers. One unit might want to characterize Caterpillar Corp. as a source of major equipment; another might interface with Caterpillar as a source of parts, while a third might categorize Caterpillar as a source of services or even consulting.
The rule that Davenport proposes is that MVOTs are allowed so long as they are always based on the original and inviolable SSOT and can be reconciled against it.
Money Saved Can Completely Fund this Effort
On the one hand, if a large company can successfully accomplish this and eliminate multiple data sources, and in a large enough company these can be quite a considerable expense, then the savings may be more than enough to pay for the entire effort.
On the other hand, such an effort at centralization is a major project requiring not only effort during the reconciliation itself, but also a governance structure to ensure that MVOTs remain firmly linked to SSOTs ever after.
An important starting point for this perspective on data governance is to determine at the outset what the balance is to be between defense and offense. For most companies simply starting off at 50/50 will not be the right answer.
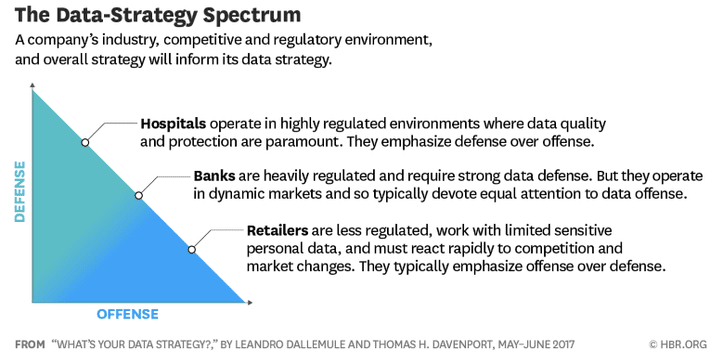
If you’re already in a highly regulated industry you know that defense that protects regulatory compliance, data integrity, and privacy issues will be dominant. If you’re in a highly competitive customer focused industry the opposite is likely to be true. The question is what is to be the balance between the two?
The good news is that in the few intervening years since Davenport first expressed this, technology has largely solved the ‘where to store it’ problem. A few years back the lead alternative would have been an EDW structured as a relational database. That would be clearly in conflict with performance needs, cost, and the ability to store and analyze semi-structured and unstructured data.
Today, modern database offerings, until recently known as NoSQL, now incorporate all the variants of structured RDBMS and compatible key value and columnar stores. The data lake has come of age and the modern SSOT can be housed there. Traditional relational EDWs might be retained where they’re more efficient in certain types of financial or payroll reporting but they become a subsidiary store fed by the master SSOT data lake.
The data lake structure also allows local analysts and data scientists to carve out local versions that may contain MVOT interpretations of data unique their operating needs. Here’s the big proviso: MVOTs need governance so they can always be reconciled back to the SSOT.
It’s logical that as AI/ML became more mainstream capabilities that they would require more order and some additional administration. It remains an open question whether that should be centralized under an enterprise CDO, or decentralized under unit CDOs reporting locally but with a matrix relationship to the corporate CDO.
Getting from your current state of disorder to this logical data strategy is never going to be an easy or automated task. If multiple sources of the truth already exist, and many probably already do, then there are inevitably going to be inconsistencies in how the data is represented. This can be even down to including the name of a customer or supplier (e.g. Acme Inc., ACME, Acme Corp.), the same sort of problems that data scientists and analysts already deal with in data prep.
The good news is that many AI assisted data prep and reconciliation tools now exist that will allow most of this reconciliation to be at least partially automated. Some of these come from the data science world of data prep like Trifacta or Paxata. Some come from the data management world like Waterline, for the automated discovery and creation of data catalogues from multiple sources.
This task may not seem welcome. It will require time, effort, and the ongoing attention of a new data management structure. But like the proverbial band aid, it’s best if pulled off quickly, before the pain becomes even greater.
Other articles on AI Strategy
Comparing AI Strategies – Systems of Intelligence
Comparing AI Strategies – Vertical versus Horizontal.
What Makes a Successful AI Company
AI Strategies – Incremental and Fundamental Improvements
Comparing the Four Major AI Strategies
Other articles by Bill Vorhies
About the author: Bill is Editorial Director for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}