
Machine Learning today tends to be “open-loop” – collect tons of data offline, process them in batches and generate insights for eventual action. There is an emerging category of ML business use cases that are called “In-Stream Analytics (ISA)”. Here, the data is processed as soon as it arrives and insights are generated quickly. However, action may be taken offline and the effects of the actions are not immediately incorporated back into the learning process. If we did, it is an example of a “closed-loop” system – we will call this approach “Adaptive Machine Learning” or AML. ISA is a precursor to AML.
Here is a small list of business use cases summarized from a recent blog, Stream Processing, where “time” is important . . . real-time applications, if you will.
1. Fraud Detection:
- Rules and scoring based on historic customer transaction information, profiles and even technical information to detect and stop a fraudulent payment transaction.
2. Financial Markets Trading:
- Automated high-frequency trading systems.
3. IoT and Capital Equipment Intensive Industries:
- Optimization of heavy manufacturing equipment maintenance, power grids and traffic control systems.
4. Health and Life Sciences:
- Predictive models monitoring vital signs to send an alert to the right set of doctors and nurses to take an action.
5. Marketing Effectiveness:
- Detect mobile phone usage patterns to trigger individualized offers.
6. Retail Optimization
- In-Store shopping pattern and cross sell; In-Store price checking; Creating new sales from product returns.
One factor that necessitates real-time interaction is the closed-loop nature of these use cases. In every case, as an external event happens, Analytics module determines a recommended action and creates a response that will impact the external event in a timely manner.
What “real-time” means is case dependent. The rate at which data collection, analysis and action happen could be milliseconds, hours, days, . . . The industry name for this is Event Stream Processing or In-Stream Analytics (ISA). There are specific implementations of computer systems, databases and data flow available to address the stringent requirements of ISA systems.
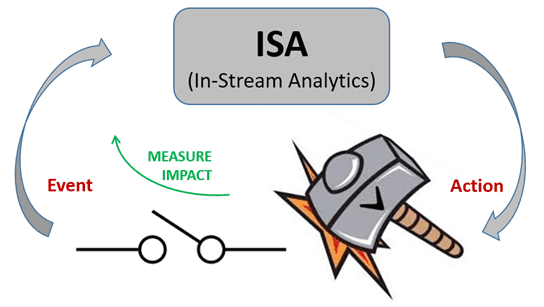
It appears to me that when “Analytics module determines a recommended action and creates a response that will impact the external event”, one should also measure the IMPACT of the action so that:
(1) we know if our action was good,
(2) we can use any shortcomings to improve ISA so that the next ISA event will have a better outcome and
(3) we can attribute the right portion of the result to ISA’s action.
If Learning is the process of “generalization from experience”, we can be more explicit and say Learning is generalization from past experience AND results of new action – this is the true definition of Learning! This is how humans learn from their environment.
With this broader view of “Learning”, it appears that ALL Analytics applications conform to the definition of Learning above . . . other than purely Descriptive Analytics. The learning system may be kept “behind the curtain” but any ML application that has business impact will have to close the loop since off-line ML system (behind the curtain) will still require a “trickle” of continuous learning or “tracking” lest the learned system becomes “aged” and not responsive to new changes. Even a language translation ML system belongs in the closed-loop category for proper continuous operation (new words and expressions enter the lexicon all the time!).
Machine Learning has not paid much attention to such “tracking” solutions. Why is that? Business use cases which demand closed-loop solutions may be assumed to be non-varying – in time or space or other dimensions – as a simplification. But in reality, every model evolves slowly or quickly. As I have noted elsewhere, I have not seen a business problem that is fully solved with a “one and done” solution! Any serious solution is like flu-shots – adjust the mix and apply on a regular basis. This is because entities involved vary (over time, in this case) and “tracking” will improve the results and may even be necessary on an on-going basis if changes are significant.
From the steady-state, ML algorithm learns what represents “normal” (think of an IoT example where a piece of machinery is operating fine); when deviations occur, Adaptive ML (AML) will quickly learn the new model. There are two ways to flag this change:
a) Monitor AML model parameters for change.
b) Monitor the output (such as prediction error) of a non-tracking algorithm; the change in the underlying system will cause a larger than normal deviation in the monitored output.
As you can see, BOTH methods will flag an event but AML is more informative – it characterizes the change in terms of new model parameters which is valuable to know; not only that a change happened but what was the nature of the change (is it a “new normal” perhaps?). This knowledge will improve future actions.
Accumulated information about the new “normals” add to the knowledge base which will allow for more advanced versions of the ML solution in the future. This learning at a higher plane (accumulation of knowledge) enhances the power of ML solutions as time goes on – continuous learning leading to smarter ML solution automatically!
Piece-meal implementation can be a practical approach to AML.
Offline Training à Operation à Periodic Closed-loop feedback à Update Classifier.
It turns out that such an intermittent approach is commonplace today in your mobile phones for adaptive channel equalization! If there was continuous closed-loop feedback, online update can be done continuously with proper care taken with outliers and deviations resulting in classifiers that get better all the time.
For closed-loop cases, In-Stream Analytics and AML will require “recursive” online processing so that each data input is processed as it arrives. The nature of recursive algorithms can be confusing and is often misunderstood in the context of Machine Learning .
A basic example is Recursive Least Squares (RLS). RLS is exact in the sense that “batch” Least Squares solution using all the data at one time and the solution obtained by RLS once the same amount of data is accumulated are identical. Solving at every step is the same as learning “as much as can be learned” from each new piece of information as it arrives – this is what RLS does.
RLS is one of a plethora of Exact Recursive Algorithms (ERAs). ERAs solve the estimation problem as each new data arrive – ERAs have the ability to track the changes since exact solution is calculated at each step. In practice, the nature of variation (speed of change, complexity, etc.) will limit the ability of ERAs be fully change-adaptive.
In my forthcoming book, “SYSTEMS Analytics”, Part II deals with ERAs culminating in the state-space formulation and Bayesian estimation using nonlinear Kalman Filter.
Clearly, there are offline applications of ML where insights are generated and the resulting report is submitted to the business executive. Here the loop is not closed online; but you can be sure that as ML use by the business matures, the executive will want the insights to be applied to the business problem and know if the action produced good results and if so, what portion of the good result can be attributed to AML. The need to close the loop will become unavoidable in many sustaining ML business applications.
In summary, Adaptive ML methods are necessary for closed-loop solutions. Off-line or batch methods are suitable for investigations and explorations but the solution to any business problem will require it to be closed-loop with the time available between event and action varying from milliseconds to hours, days and months. The adaptive nature of AML, where the solution tracks the changing environment, renders the solution fully automatic removing the need for human intervention in the best case.
About the Author:
Dr. PG Madhavan is the Founder of Syzen Analytics, Inc. He developed his expertise in Analytics as an EECS Professor, Computational Neuroscience researcher, Bell Labs MTS, Microsoft Architect and startup CEO. PG has been involved in four startups with two as Founder.
More at www.linkedin.com/in/pgmad
{kind=link}