
This article was written by Adrian Rosebrock. Adrian is an entrepreneur and Ph.D who has launched two successful image search engines, ID My Pill and Chic Engine.
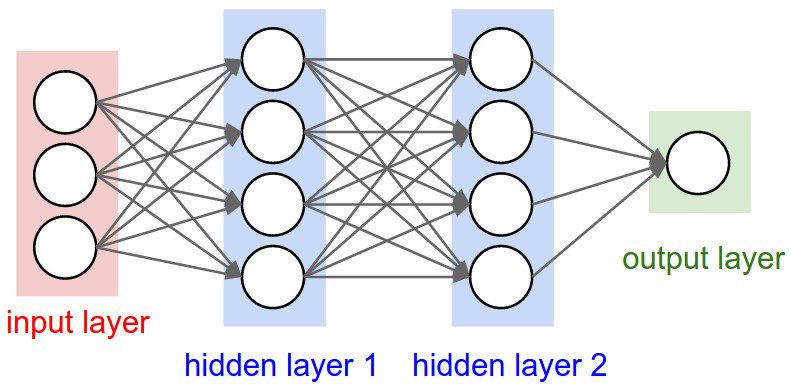
If you’ve been following along with this series of blog posts, then you already know what a hugefan I am of Keras. Keras is a super powerful, easy to use Python library for building neural networks and deep learning networks. In the remainder of this blog post, I’ll demonstrate how to build a simple neural network using Python and Keras, and then apply it to the task of image classification.
A simple neural network with Python and Keras
To start this post, we’ll quickly review the most common neural network architecture — feedforward networks. We’ll then write some Python code to define our feedforward neural network and specifically apply it to the Kaggle Dogs vs. Cats classification challenge. The goal of this challenge is to correctly classify whether a given image contains a dog or a cat. Finally, we’ll review the results of our simple neural network architecture and discuss methods to improve it.
Feedforward neural networks
While there are many, many different neural network architectures, the most common architecture is the feedforward network:
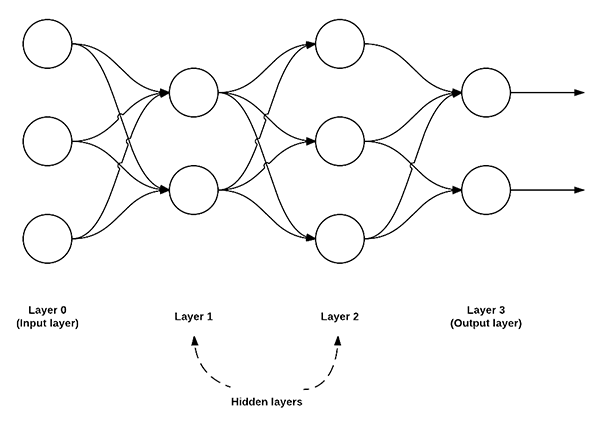
Figure 1: An example of a feedforward neural network with 3 input nodes, a hidden layer with 2 nodes, a second hidden layer with 3 nodes, and a final output layer with 2 nodes.
In this type of architecture, a connection between two nodes is only permitted from nodes in layer i to nodes in layer i + 1 (hence the term feedforward; there are no backwards or inter-layer connections allowed). Furthermore, the nodes in layer i are fully connected to the nodes in layer i + 1. This implies that every node in layer i connects to every node in layer i + 1. For example, in the figure above, there are a total of 2 x 3 = 6 connections between layer 0 and layer 1 — this is where the term “fully connected” or “FC” for short, comes from. We normally use a sequence of integers to quickly and concisely describe the number of nodes in each layer. For example, the network above is a 3-2-3-2 feedforward neural network:
- Layer 0 contains 3 inputs, our
 values. These could be raw pixel intensities or entries from a feature vector.
values. These could be raw pixel intensities or entries from a feature vector. - Layers 1 and 2 are hidden layers, containing 2 and 3 nodes, respectively.
- Layer 3 is the output layer or the visible layer — this is where we obtain the overall output classification from our network. The output layer normally has as many nodes as class labels; one node for each potential output. In our Kaggle Dogs vs. Cats example, we have two output nodes — one for “dog” and another for “cat”.
 values. These could be raw pixel intensities or entries from a feature vector.
values. These could be raw pixel intensities or entries from a feature vector.To read more, click here. For other articles about python and keras, click here.
Top DSC Resources
- Article: What is Data Science? 24 Fundamental Articles Answering This Question
- Article: Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Tutorial: Data Science Cheat Sheet
- Tutorial: How to Become a Data Scientist – On Your Own
- Categories: Data Science – Machine Learning – AI – IoT – Deep Learning
- Tools: Hadoop – DataViZ – Python – R – SQL – Excel
- Techniques: Clustering – Regression – SVM – Neural Nets – Ensembles – Decision Trees
- Links: Cheat Sheets – Books – Events – Webinars – Tutorials – Training – News – Jobs
- Links: Announcements – Salary Surveys – Data Sets – Certification – RSS Feeds – About Us
- Newsletter: Sign-up – Past Editions – Members-Only Section – Content Search – For Bloggers
- DSC on: Ning – Twitter – LinkedIn – Facebook – GooglePlus
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
{kind=link}