
As I learn about data privacy, I’m starting to realize how large the ecosystem is. I focused here on a category that spans across the data privacy landscape, Privacy Enhancing Technologies (PETs). In the post, I cover:
- the (difficult) categorization of these technologies;
- some examples of PETs and their applications;
- the framework of Privacy by Design in which PETs exist;
- the opportunities these technologies hold, besides compliance.
Privacy Enhancing Technologies
Under this category, we find a collection of tools and methods. The underlying technologies are quite diverse. But they all have one core purpose: to mitigate privacy risk and protect personal data.
The term appeared for the first time in 1995, in the report “Privacy-enhancing technologies: The path to anonymity”. Since then, PETs gained popularity, especially as data protection regulations developed.
The European Data Protection Supervisor mentioned PETs on several occasions. The UE authority presented them as a way of complying with data protection laws. Since 2014, specific agencies, like the ENISA (European Union Agency for Cybersecurity), also advocates for the adoption of PETs.
PETs are an asset for businesses dealing with sensitive data. With proper implementation, they allow organizations to drive innovation while remaining compliant. While it sounds promising, there are no guidelines on how and what organizations need to put in place.
One of the reasons is that PETs are quite a diverse bunch (and so are the needs of companies). The landscape and collection of tools evolve as research progresses. The ENISA wrote on that matter:
“[…] few data sources exist that give guidance on utilization of a given PET or that help to select the right PET for a given purpose nor does a publicly available and reasonably well-maintained repository of PETs exist.”
One way to understand PETs is to look at the scope of applications. And see how they contribute to data protection.
PETs categories & the privacy risk taxonomy
It’s hard to be exhaustive when listing PETs. They regroup a diverse group of tools and approaches. The same way we don’t have a unique definition for them, there is no commonly accepted taxonomy.
Some suggested classifications on whether the tool supported privacy management or privacy protection. Others proposed to distinguish “opacity” technologies from “transparency” technologies.
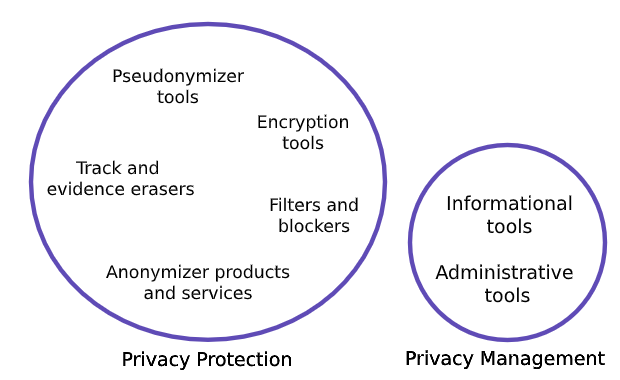
Taxonomy for PETs suggested in a study for the Danish Government (Meta Group 2005)
Another approach is to look at their capabilities through the lens of “privacy risks”. We’re talking of multiple “risks”, as there isn’t one single privacy risk. It’s rather a group of risks living alongside the data lifecycle.
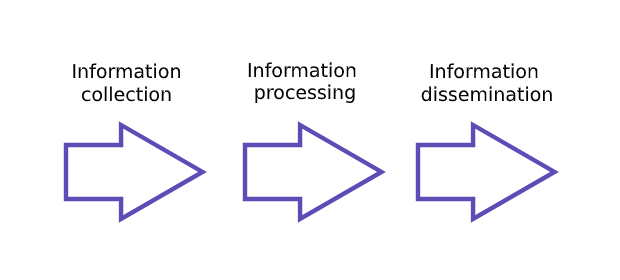 A simple representation of the data lifecycle
A simple representation of the data lifecycle
Each stage presents specific risks for the individual’s data. In 2006, a researcher attempted to classify these risks. Daniel Solove proposed a taxonomy of Privacy threats.
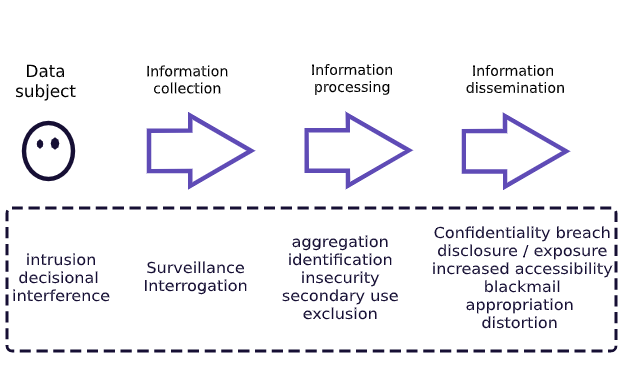 Various risks from Solove’s taxonomy of privacy threats.
Various risks from Solove’s taxonomy of privacy threats.
The PETs operate along the same continuum. Different PETs tackle different risks, at different stages. Some of them focus on mitigating risks in the processing phase. Others protect data sharing. Under these categories, several technologies gained popularity in recent years.
Examples of PETs
1) Trusted Execution Environments (TEE)
TEE hardware technology focusing on securing the processing of sensitive data. They are secure areas for the data inside a processor. They keep the data safe and inaccessible during its processing.
In 2019, Visa introduced LucidiTEE, a blockchain-based TEE system. They developed it to share financial data with third-parties. According to Visa, this approach offers a “fair and compliant” data sharing solution.
2) Zero-Knowledge Proofs (ZPK)
ZKP technology is a set of methods to process a statement without revealing sensitive data. ZKP involves two parties: the prover and the receiver. One convinces the other that it posses a piece of information without having to expose it.
In July 2019, the DARPA announced the launch of the SIEVE project. The initiative aims at adapting ZKP to military use-case. For instance, it could help prove a cyberattack origin without compromising sensitive information.
3) Secure multi-party computation (MPC)
MPC is a collection of protocols to process data from many sources. The particularity is that it doesn’t reveal the sources to each other. You combine sensitive data for analysis and get access to the results. But you never see the other data inputs. It a subtype of ZKP.
In 2015, a team from Boston University conducted a gender wage gap study. They relied on MPC to collect, analyze, and publish the results. They managed to do it without exposing personal data.
4) Differential privacy
Differential Privacy is an approach that preserves data privacy when processing data. You do so by adding noise to the results of the queries on a dataset. It removes the possibility of identifying someone in the data. But it also keeps the statistical correctness of the data.
In 2018, the US Census Bureau announced they would adopt differential privacy. The goal was to better guarantee people’s anonymity in the country’s yearly Census. They want to introduce it in the 2020 Census.
5) Homomorphic Encryption (HE)
HE is a set of methods to process the data without ever exposing it. It allows running operations on an encrypted form of the sensitive data. You get access to the results but you’re never exposed to the data itself.
Earlier this year, a Brazilian bank trained machine learning algorithms on encrypted data. Their model performed predictions on encrypted customer data, preserving its privacy.
6) Synthetic data
Data synthesization is also an approach designed to help protect data privacy. Instead of working directly with sensitive data, you generate synthetic data that holds the same overall statistical properties as your original data. Synthetic data points are less likely to trace back to the original training examples, thus helping to protect their privacy.
This year, a Swiss insurance company used synthetic data to train churn models. Instead of training machine learning algorithms with sensitive customer data, they generated and used synthetic data. This is a case my company worked on.
Note that PETs aren’t mutually exclusive. It’s possible to combine them to reinforce privacy and security. For instance, one can produce differentially private synthetic data. Besides, it’s important to add that not all PETs are mature technology. They have drawbacks and limitations, for example being compute-intensive.
But as we improve them, they hold greater opportunities for organizations. An important element for that is the fact that they build on the principle of Privacy by Design.
PETs and the concept of Privacy by Design
Many regulatory frameworks mention the concept of Privacy by Design. The same discussion that introduced PETs as means of protecting privacy 25 years ago, also introduced the concept of Privacy by Design.
Behind this discussion, were the Information Commissioner of Ontario and the Netherlands Data Protection Organisation. Their message was the following:
“what is first required is a change in thinking within organizations and businesses that develop, implement, and use networked systems and ICTs. […]
[…] privacy works in conjunction with technology and enhances its functionality insofar as it increases end-user satisfaction, consumer confidence, trust, and use. Technology is not hindered by privacy, but rather, made far better by it.”
They insist on the importance of re-thinking the development and use of technological systems. Putting privacy at the core of the data approach was not only a requirement but would also become valuable for organizations.
In 2009, they translated this into a framework of 7 principles:
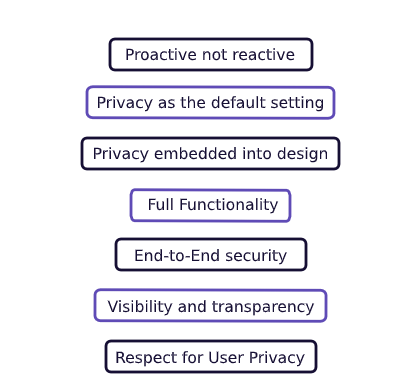
The 7 Foundational Principles of the Privacy by Design framework — For the complete description, see the report.
In 2010, the Global Privacy Assembly (GPA) recognized Privacy by Design as “an essential component of fundamental privacy protection”. This later became a fundamental element in the European GDPR.
From ‘Privacy’ to ‘Data Protection’ by Design
2016 was a big year for PETs. With article 25, GDPR introduced “Data Protection by Design” into the regulatory landscape.
“The controller shall implement appropriate technical and organisational measures for ensuring that, by default, only personal data which are necessary for each specific purpose of the processing are processed.”
With this move, the regulator turned Privacy by Design into a legal requirement. Organizations now must integrate data protection safeguards within their systems. This marked an important turn, both for organizations and PETs.
Few regulators besides the EU made Privacy by Design a legal rule at this point. For instance, it isn’t an obligation in the California Consumer Privacy Act (CCPA). Other regulators made mention of it, without obligations. It’s the case of the Australian Office of the National Data Commissioner (ONDC). The organizations embed Privacy by Design in its 2019 data sharing recommendation framework.
But we could see Privacy by Design becoming a legal component of other data privacy frameworks in the future. For instance, India is preparing its Personal Data Protection Bill (PDPB). And he country is looking to introduce Privacy by Design in the legislation.
As regulations are rolling out, PETs become key elements in company compliance efforts. As mentioned by the ENISA:
“privacy-enhancing technologies play a major role in implementing such Privacy by Design approach into real-world systems, thereby making them essential tools of the information systems of tomorrow”.
But PETs can also address the data challenges raised by privacy limitations.
The interest of PETs for businesses
Besides compliance with data protection laws, PETs present several advantages:
They enable applications that would otherwise be impossible without compromising customer privacy. With the appropriate approach, you can enable data collaboration on sensitive data. Organizations fighting fraud could extract critical insights from joint data processing for example. In general, data is a valuable resource to derive value from.
PETs reinforce user control over their data and contribute to building trust. New data breaches and leaks are being announced almost every week. Not only companies but also users must have control over their sensitive data. This could be a step forward for organizations willing to regain public trust.
PETs allow organizations to save money. Some systems have high deployment costs. But in the long run, PETs reduce costly data manipulations. For example, the Census Bureau is saving time and money. The system automates the data collection process, ultimately reducing costs.
And PETs contribute to limiting indirect costs, like the ones a data breach would create. But of course, companies should assess the financial benefits on a case-by-case basis.
Privacy by Design is becoming the default setting. And PETs and privacy technology become key for organizations. Already, we’re seeing the potential of PETs in many industries. From banking to healthcare, insurance, or the public sector, applications have shown results. With a proactive approach, organizations will be able to identify the right tool for them. The tools that will help them guarantee real privacy for personal data.
Sources & additional resources:
- Privacy-enhancing technologies by the ENISA
- An Introduction to Privacy Enhancing Technologies Related reading by IAPP
- Implementing Differential Privacy: Seven Lessons From the 2020 Unit… by MIT Press
- What Are Zero-Knowledge Proofs? by WIRED
- The Next Generation of Data-Sharing in Financial Services by Deloitte
- Study on the economic benefits of privacy-enhancing technologies (P… by London Economics
- Privacy Enhancing Technologies: Evolution and State of the Art by the ENISA
- Is 2020 finally the year of the PETs (Privacy Enhancing Technologies)? by Deloitte
{kind=link}