

I’m overjoyed to announce the release of my latest book “The Economics of Data, Analytics, and Digital Transformation.” The book takes many of the concepts discussed in this blog to the next level of pragmatic, actionable detail. Thanks for your support!
I recently read where one very profitable on-line company proudly announced that they had “30,000 trained ML models in operations”. Clearly, this company feels that possessing a large number of ML models is an important indicator of its analytics prowess and maturity. However, this perpetuates a false narrative; that possession of ML models is valuable in of itself. This perspective totally glosses over the real problem which is the uncontrolled proliferation of ML models across the organization (30,000 in this case), the vast majority of which become orphaned analytics.
Orphaned Analytics are one-off Machine Learning (ML) models written to address a specific business or operational problem, but never engineered for sharing, re-use and continuous-learning and adapting.
Not only do orphaned analytics give the false impression that they represent something of value, but in reality, orphaned analytics represent a significant liability. Why? These orphaned analytics represents a significant operational and regulatory risk if the model starts to drift and starts to deliver inaccurate or biased results (see Fair Credit and Reporting Act violation ramifications). And the person who wrote the ML model may no longer be with the company, so there is no one with whom to talk to understand its operational intricacies.
All-in-all, not only do orphaned analytics pose a significant financial, operational and regulatory risk, but orphaned analytics are the great destroyer of the economic value of data and analytics.
Background on Orphaned Analytics
I first observed orphaned analytics when I was doing my research project with Professor Mouwafac Sidaoui titled “Applying Economic Concepts to Big Data to Determine Financial Value…” (note: this research paper can be found on my DeanofBigData.com website where there are some other cool materials that you might find useful). From the paper:
“Even organizations advanced with substantial advanced analytic capabilities suffer from orphaned analytics, analytics that address a one-time business need but are not operationalized or re-used across multiple use cases.”
Surprisingly at the time, we observed the orphaned analytics situation at those organizations that were the most mature from a data and analytics perspective (see Figure 1).
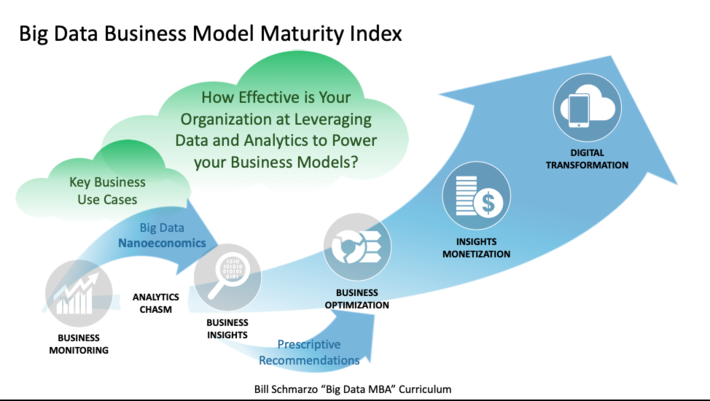
Figure 1: Big Data Business Model Maturity Index
I believe that the orphaned analytics problem occurred in these very analytic mature organizations because they have a wealth of skilled data engineers and data scientists for which it was easier just to “bang out” a new ML model from scratch then to try to reconstruct the one that “Bob” had originally built.
In the blog “How to Avoid Orphaned Analytics”, I talked about the role of Analytic Profiles and propensity scores to help address the orphaned analytics problem (see Figure 2).
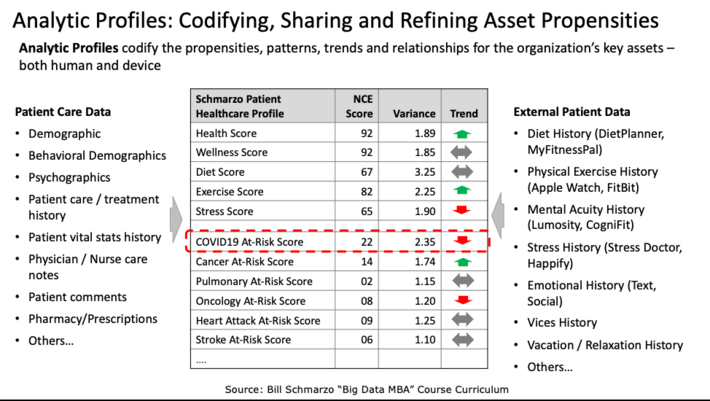
Figure 2: Role of Analytic Profiles with respect to Orphaned Analytics
But still, organizations don’t understand the problem, and in particular, don’t understand what the orphaned analytics problem was costing them. Organizations don’t understand that these orphaned ML models don’t exploit the economics of creating assets that appreciate in value the more that they are used. So, let’s try this again.
Quantifying ML Model Reuse Opportunities
I first ran into Deloitte’s Shareholder Value Map in Figure 1 in 2004. I always thought of it as a “Periodic Table” for how shareholder value is created. That description continues to fuel an interesting thought: can one look across the different use cases detailed on this map and find analytic commonalities across them? That is, can we identify situations where the organization can create a high-level ML model – such as matching optimization, forecasting trends, predicting change impact, anomaly detection, performance degradation, yield optimization or purchase propensities – that could then be repurposed across multiple use cases, thereby accelerating the learning associated with that analytic modules (sorry that you’ll need a magnifying glass to read Figure 3)?
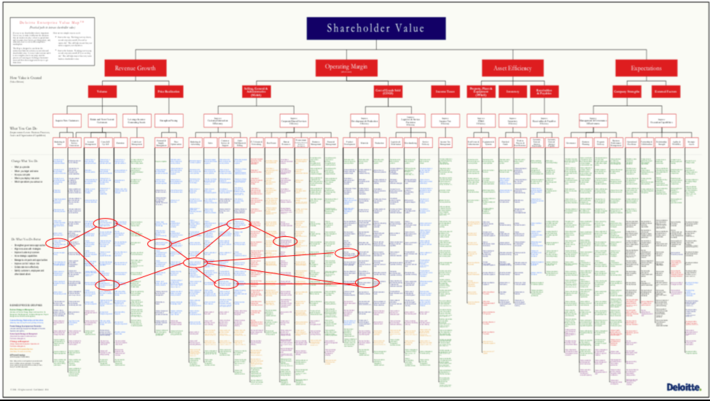
Figure 3: Deloitte Shareholder Value Map
The Deloitte Shareholder Value Map provides a goldmine of opportunities to reuse the organization’s ML models. But to build reusable ML models, organizations need to engineer the ML models to include data pipelining, data transformation, data enrichment, model serving, drift management, hyperparameter optimization, documentation, test data, QA, implementation instructions, version control, maintenance log, and etc. that enables the sharing, reuse and refinement of these ML models.
But if an organization hasn’t established the discipline or governance to facilitate (mandate?) the engineering, sharing and re-use of the ML models, then Figure 3 just becomes another source for orphaned analytics.
Role of Hypothesis Development Canvas to Prevent Orphaned Analytics
One tool that can help mitigate the orphaned analytics problem is the Hypothesis Development Canvas. The Hypothesis Development Canvas drives alignment between the business and data science team to thoroughly understand the problem they are trying to solve, the business value of that problem, the metrics against which we are going to measure progress and success, and even the costs associated with False Positives and False Negatives (see Figure 4).
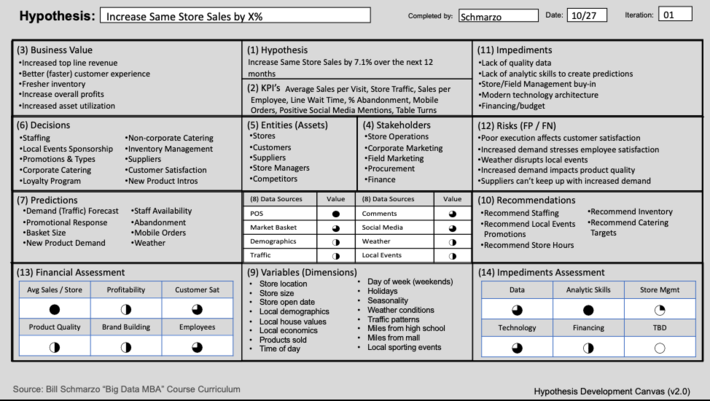
Figure 4: Hypothesis Development Canvas
In order to avoid orphaned analytics, we require the data science team to collaborate with the business stakeholders prior to ever putting “science to the data.” Not only does this ensure that we are intimately aligned around the problem with are trying to solve with data and analytics, and how the analytic insights will be deployed with the business stakeholders’ environment, but now we have a searchable, sharable document around which we can now align all of our data engineering and data science deliverables.
Yes, the Hypothesis Development Canvas is the first thing you see when you go to JupyterHub to search, find and reuse the organization’s valuable reusable ML models.
Summary
I want to extend a very special thank you to Alex Campo who created the graphic in Figure 5 to highlight the causes and effects of Orphaned Analytics.
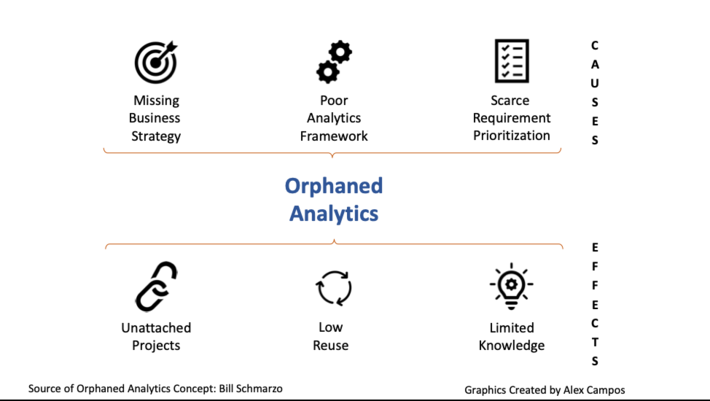
Figure 5: Causes and Effects of Orphaned Analytics
In Alex’s LinkedIn post, he nicely summarized the key tips to avoid Orphaned Analytics:
- Implement a meaningful prioritization process
- Package analytics assets for reuse
- Improve data and knowledge sharing across all teams
- Governance and analytics should evolve together
What excited me most about Alex’s contribution was:
- Alex took an idea that is laid forth in my new book (“The Economics of Data, Analytics, and Digital Transformation”), and he made that idea more understandable, relevant and actionable with his graphic.
- This is an example of how social media is supposed to work – we propose ideas and then we collaborate to perfect those ideas.
- Finally, I sincerely appreciate the opportunity to build community around the book; that we can expand upon the concepts and techniques in the book.
Thanks again Alex!
{kind=link}