

Web scraping deals with HTML almost exclusively. In nearly all cases, what is required is a small sample from a very large file (e.g. pricing information from an ecommerce page). Therefore, an essential part of scraping is searching through an HTML document and finding the correct information.
How that should be done is the matter of some debate, preferences, experience, and types of data. While all scraping and parsing methods are “correct”, some of them have benefits that may be vital when more optimization is required. Some methods may be easier for specific types of data. However, outside of a lone scientific study, succinct information on the differences and practicality of CSS Selectors, XPath, and RegEx is scarce.
Note: While most of the article is intended to be programming-language-agnostic, my foundation is in Python. Some assumptions or syntax might be lifted from it.
HTML through the eyes of scraping
Since in web scraping we’re mostly dealing with HTMLs documents that are made by someone else, we don’t need to go through the absolute basics to understand the following chapters. We can get away with just understanding HTML as an object.
When a web page is loaded in a browser, a Document Object Model (or DOM) is created. It is a tree-like object structure that contains all objects in the HTML. The Domain Object Model is a great way to visualize the website structure without worrying too much about any particular content.
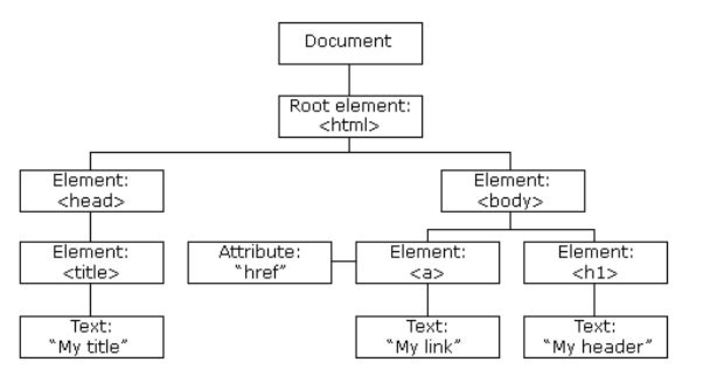
Sample DOM. Source.
Since we’re using web scraping to wrestle out data (or content) from the website, we need to “tell” the application where the content is supposed to be. All three methods are, grossly simplified, different search functions used to cut through the structure.
CSS Selectors
Nearly every HTML will be served with CSS. It’s used for many ways of styling (e.g. text or image alignment, fonts, etc.) the content of an HTML file. CSS selectors are the way elements are, well, selected.
In web scraping, CSS Selectors is essentially a way to move from the root document to any particular element. However, the movement can only happen in that direction. Other methods, such as XPath, allow users to move bidirectionally.
Element selection happens based on CSS reference. For example, searching for “.text” would output all elements that contain “class=text” if any exist. Such a way to search HTML DOM is immensely useful for web scraping.
From our experience, CSS selectors are one of the fastest web parsing methods out of the three. At Oxylabs, we’ve used them quite a bit previously, however, with hardware and software capabilities quickly increasing, the speed benefits are getting smaller over time.
Additionally, CSS selectors are easy to maintain and manage. They are also supported by nearly every Python web scraping library, making it easier to transfer code and overall understanding if needed.
However, CSS selectors only allow one-directional flow, which greatly limits its capabilities. It cannot, for example, select a parent of an element. Every search has to be built from the top down to the particular element.
XPath
At Oxylabs, we primarily now use XPath. While it is theoretically slower, the differences between XPath and CSS are so minute that it won’t really have much of an impact. However, XPath provides much greater flexibility, especially for complex data structures.
XPath functions in a rather similar manner while being a bit bulkier in execution. For example, to find all elements that have “class=nice” instead of using “.nice”, XPath would use “//*[contains(@class, “nice”)]”. While XPath syntax is nearly always a bit more complex, it provides quite a few more features.
One of these beneficial features has been shown in the command “contains()”. It allows users to find partial matches within the HTML DOM. CSS selectors used to have “contains:”, however, that is no longer in use.
Additionally, XPath has “..” which allows the function to move towards ancestors. Thus, XPath avoids the limitation of CSS selectors, allowing users to move through the HTML DOM object with greater ease and freedom.
As mentioned previously, the primary and often cited drawback is the slower scraping speed. Yet, the differences usually are in several tens of milliseconds. It’s hard to think of a practical business case where such speed would make a difference.
RegEx
RegEx, or regular expression, is the final method. However, it’s not as practical for HTML as the other two as it’s used to search through strings. Yet, it’s still a great method for specific cases.
These cases are usually whenever the HTML files or elements are content heavy. Regular expressions work by being provided a pattern. Content is then matched to the pattern and an output is provided.
An example of a RegEx pattern in Python would be re.compile(r’^([A-Z]{1}.+?)(?:,)’) which would match all strings that start with one uppercase letter and are followed by any amount of characters until it runs into a comma. Essentially, it would find all items that are formulated into a list where elements start with an uppercase letter and end with a comma:
- John,
- Marty,
- Ellen,
The expression above should have hinted at the first weakness of RegEx. Whoever made the syntax for matching regular expressions seemed not to care about clarity. My example is actually one of the simpler searches as there are no special characters. Once ‘/’ and other special characters come into play, the syntax gets even messier. In turn, that makes it difficult to debug, especially in larger scripts.
Additionally, since in web scraping we’re extracting things from HTML files, it itself is one big string. RegEx doesn’t do as well once the language becomes structural and data from particular elements is required. Using CSS selectors or XPath is significantly easier in those cases.
At Oxylabs, we always use RegEx to find string matches as it’s universal. For that purpose, the method is excellent. However, we cover nearly everything else with XPath.
Conclusion
If you’re planning to embark on a web scraping journey or to optimize your current solution, I’d highly recommend learning XPath and RegEx as you would be able to gather data from nearly any source. CSS Selectors, on the other hand, are easy to use but limited in applicability.
Editorial Note: The debate between using CSS selectors vs. using XPath is one that has been going on for a long time. I made the argument, unsuccessfully, to incorporate XPath selectors into SVG behavior bindings specification all the way back in 2004. Unfortunately, like so much in the HTML world, the decision to turn away from XPath ended up putting a far weaker tool for node selection (CSS Selectors) in its place. I’m glad to see an intelligent use of XPath being recommended here, and gives me hope that XML isn’t quite as dead as some would like it to be – Kurt Cagle.
{kind=link}