
Ontologies and Semantic Annotation. Part 1: What Is an Ontology

In the abundance of information, both machines and human researchers need tools to navigate and process it. Structuring and formalization of data into hierarchies, such as trees, may establish the relations between the data required for efficient machine processing and may make the information more readable for data analysts.
Yet, in more complex domains, such as in natural language processing, relations between concepts go beyond simple hierarchies and form thesaurus-like networks. For such cases, researchers use ontologies as common vocabularies for specialists who need to share information in a domain.
Applications of Ontologies
Ontologies were first defined as “explicit formal specifications of the terms in the domain and relations among them” (Gruber 1993) and, more specifically, “a formal, explicit specification of a shared conceptualization” (Studer et al. 1998) and are used in a number of applications, including the following, as specified by Noy and McGuinness (Noy and McGuinness 2001):
• To analyze domain knowledge.
Ontologies are the tools to provide comprehensive description of the domain of interest with respect to the users’ needs
• To share common understanding of the structure of information among people or software agents.
It is something that we see when, for example, medical information is published on, several different websites. If these websites share the same underlying ontology of the terms they all use, then computer agents can extract and aggregate information from these different sites and use it to answer user queries or as input data to other applications.
• To reuse domain knowledge.
If we want to build a large ontology, we can integrate several existing ontologies describing portions of the large domain. And on the contrary, we can reuse a general ontology to describe our domain of interest.
• To make domain assumptions explicit makes it possible to change these assumptions easily if the knowledge about the domain changes.
Hard-coding assumptions about the world in a code makes these assumptions not only hard to find and understand but also hard to change, in particular for someone without programming expertise. Besides, explicit specifications of domain knowledge may help learner to get oriented in the domain.
• To separate domain knowledge from operational knowledge.
We can describe a task of configuring a product from its components according to a required specification and implement a program that does this configuration independent of the products and components themselves.
Ontology Structure
For appropriate usage, ontologies need to facilitate the communication between the human and the machine — referring to terminology specified in the ontology — or even intermachine and inter-human communication (Guarino 2009).
This function of ontology underpins its structure, as an ontology as a formal description of a domain of discourse rests on classes, sometimes also called concepts.
For example, a class of books represents all books. Specific books are instances of this class. The book on Machine Learning that lies on your desk waiting for your attention is an instance of the class of programming manuals.
Besides, a class can have subclasses that represent concepts that are more specific than the superclass. For example, we can divide the class of all books into fiction and non-fiction. Alternatively, we can divide a class of all books into books for adults and children.
Properties of each class-concept describing various features and attributes of the concept are called slots (sometimes roles or properties)).
Slots describe properties of classes and instances: Pride and Prejudice is a historical romance; it is written by the author Jane Austin. We have two slots describing the book in this example: the slot genre with the value romance and the slot author with the value Jane Austin. At the class level, we can say that instances of the class Book will have slots describing their genre, literature trend, author and so on.
Restrictions on slots are called facets, or role restrictions (Noy &
McGuinness 2001).
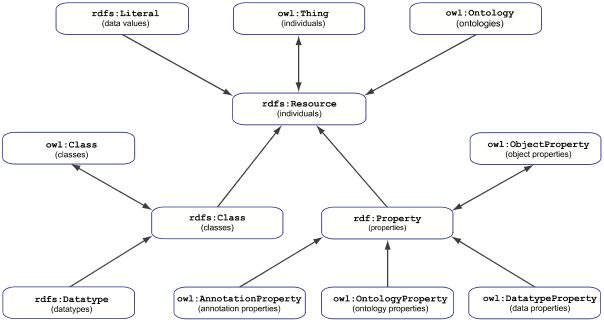
Figure 1. Ontology structure (picture taken from OWL 2 Web Ontology Language RDF-Based Semantics (Second Edition)
An ontology together with a set of individual instances of classes constitutes a knowledge base. In reality, there is a fine line where the ontology ends and the knowledge base begins.
Ontology Properties
When building and using ontologies, it is crucial to remember that ontologies are graphs, not trees, and relations between their components may be multidirectional:
• Slots may have multiple aspects to describe the type of the variable, the number of values and other properties;
• Relations between classes may be of various types, such as “is — a”, “part — of”, “located — in”, etc.
• A class may have multiple parents;
• Instances can have more than one class
In the following parts we will go into more practical questions and share some practical tips of building our own ontology from the scratch.
References
Gruber, T.R. (1993). A Translation Approach to Portable Ontology Specification. Knowledge Acquisition 5: 199–220.
Guarino, N., Oberle, D., and Staab, S. 2009. What is an Ontology? In S. Staab and R. Studer (eds.),. Handbook on Ontologies, Second Edition. International handbooks on information systems. Springer Verlag: 1–17.
Noy, N. F. and McGuinness, D. L. (2001). Ontology development 101: A guide to creating your first ontology. Technical report, KSL-01–05, Stanford Knowledge Systems Laboratory. Available from http://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html.
Studer, R. , Benjamins, R. and Fensel, D. (1998). Knowledge engineering: Principles and methods. Data & Knowledge Engineering, 25(1–2):161–198.
{kind=link}