

MLOps, AIOps, DataOps, ModelOps, and even DLOps. Are these buzzwords hitting your newsfeed? Yes or no, it is high time to get tuned for the latest updates in AI-powered business practices. Machine Learning Model Operationalization Management (MLOps) is a way to eliminate pain in the neck during the development process and delivering ML-powered software easier, not to mention the relieving of every team member’s life.
Let’s check if we are still on the same page while using principal terms. Disclaimer: DLOps is not about IT Operations for deep learning; while people continue googling this abbreviation, it has nothing to do with MLOps at all. Next, AIOps, the term coined by Gartner in 2017, refers to the applying cognitive computing of AI & ML for optimizing IT Operations. Finally, DataOps and ModelOps stand for managing datasets and models and are part of the overall MLOps triple infinity chain Data-Model-Code.
While MLOps seems to be the ML plus DevOps principle at first glance, it still has its peculiarities to digest. We prepared this blog to provide you with a detailed overview of the MLOps practices and developed a list of the actionable steps to implement them into any team.

MLOps: Perks and Perils
Per Forbes, the MLOps solutions market is about to reach $4 billion by 2025. Not surprisingly that data-driven insights are changing the landscape of every market’s verticals. Farming and agriculture stand as an illustration with AI’s value of 2,629 million in the US agricultural market projected for 2025, which is almost three times bigger than it was in 2020.
To illustrate the point, here are two critical rationales of ML’s success it is the power to solve the perceptive and multi-parameters problems. ML models can practically provide a plethora of functionality, namely recommendation, classification, prediction, content generation, question answering, automation, fraud and anomaly detection, information extraction, and annotation.
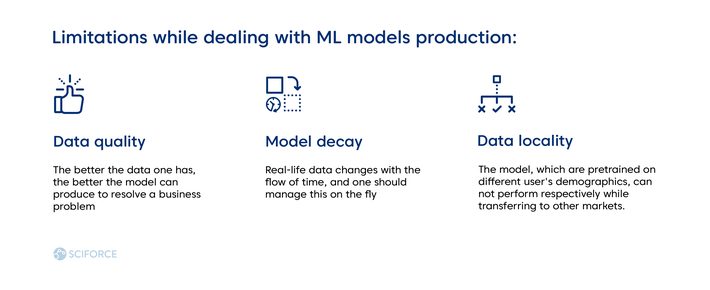
MLOps is about managing all of these tasks. However, it also has its limitations, which we recommend to bear in mind while dealing with ML models production:
-
Data quality. The better the data one has, the better the model can produce to resolve a business problem.
-
Model decay. Real-life data changes with the flow of time, and one should manage this on the fly.
-
Data locality. The model, which are pretrained on different user’s demographics, can not perform respectively while transferring to other markets.
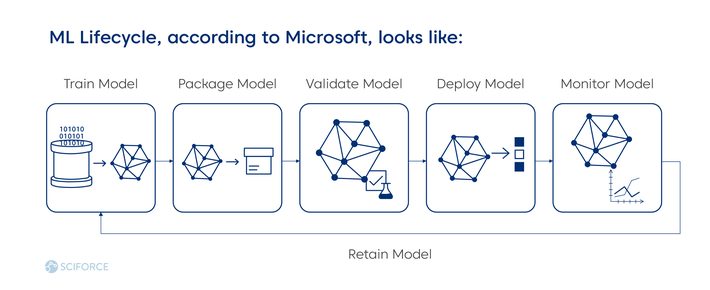
Meanwhile, MLOps is particularly useful when experimenting with the models undergoing an iterative approach. MLOps is ready to go through as many iterations as necessary as ML is experimental. It helps to find the right set of parameters and achieve replicable models. Any change in data versions, hyper-parameters, and code versions leads to the new deployable model versions that ensure experimentation.
ML Workflow Lifecycle
Every ML project aims to build a statistical model out of the data, applying a machine learning algorithm. Hence, Data and ML Model come out as two different artifacts to the software development of the Code Engineering part. In general, ML Lifecycle consists of three elements:
-
Data Engineering: supplying and learning datasets for ML algorithms. It includes data ingestion, exploration and validation, cleaning, labeling, and splitting (into the training, validation, and test dataset).
-
Model Engineering: preparing a final model. It includes model training, evaluation, testing, and packaging.
-
Model Deployment: integrating the trained model into the business application. Includes model serving, performance monitoring, and performance logging.
MLOps, Explained: When Data & Model Meet Code
As ML introduces two extra elements into the software development lifecycle, everything becomes more complicated than the use of DevOps for any software development. While MLOps still seeks for source control, unit and integration testing, and continuous delivery of the package, it brings some new differences, compared to DevOps:
- Continuous integration (CI) applies to the testing and validating data, schemas, and models, not only refers to the code and components.
- Continuous deployment (CD) refers to the whole system, which is to deploy another ML-provided service, but not to the single software or service.
- Continuous training (CT) is unique to the ML models and stands for model service and retraining.
 Source: Google Cloud
Source: Google Cloud
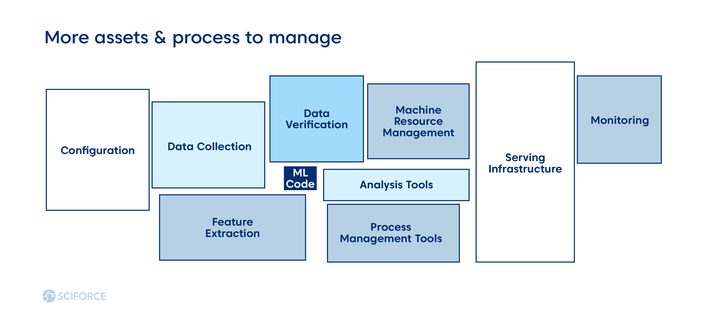
The level of each step of data engineering automation, model engineering, and deployment define the overall maturity of MLOps. Ideally, CI and CD pipeline should be automated to define the mature MLOps system. Hence, there are three levels of MLOps, categorized and based on the level of processes automation:
- MLOps level 0: a process of building and deploying of ML model is entirely manual. It is sufficient for the models that are rarely changed or trained.
- MLOps level 1: continuous training of the model by automating the ML pipeline, good fit for models based on the new data, but not for new ML ideas.
- MLOps level 2: CI/CD automation lets work with new ideas of feature engineering, model architecture, and hyperparameters.
In contrast to DevOps, model reuse is a different story as it needs manipulations with data and scenarios, unlike software reuse. As the model decays over time, there is a need for model retraining. In general, data and model versioning is code versioning in MLOps, which seeks more effort compared to DevOps.
Benefits and Costs
To think through the MLOps hybrid approach for a team, which is implementing it, one needs to assess the possible outcomes. Hence, we’ve developed a generalized pros-and-cons list, which may not apply to every scenario.
MLOps Pros:
- Automatic updating of multiple pipelines, which is terrific as it is not about a simple single code file task
- ML Models scalability and management depending on scope, thousands of model can be under control
- CI and CD orchestrated to serve ML Models (depending on MLOps’ maturity level)
- ML Model’s health and governance simplified management of the model after deployment
- A useful technique for people, process, and technology to optimize ML products development
We assume that it might take some time for any team to adapt to the MLOps and develop its modus operandi. Hence, we are proposing a list of possible stumbling stones to foresee:
MLOps Costs:
- Development: more frequent parameters, features, and models manipulation, non-linear experimental approach compared to DevOps
- Testing: includes data and model validation, model quality testing
- Production and Monitoring: MLOps needs continuous monitoring and auditing for accuracy
- memory monitoring memory usage monitoring when performing predictions
- model performance monitoring models retraining applies with time as data can change, which can affect the results
- infrastructure monitoring continuous collection and review of the relevant data
- Team: invest time and efforts for data scientists and engineers to adopt

Getting Started with MLOps: Actionable Steps
MLOps requires knowledge about data biases and needs high discipline within the organization, which decides to implement it.

As a result, every company should develop its own set of practices to adjust MLOps to its development and automation of the AI force. We hope that the guidelines mentioned contribute to the smooth adoption of this philosophy into your team.
The article was originally posted on SciFoce blog.
{kind=link}