

Machine learning (ML) is a hot topic nowadays. Everyone speaks about the new programming paradigm, models are implemented in very different domains, more and more startups are relying mainly on ML.
At the same time, machine learning is a complex field having several different dimensions. Sometimes even experienced technical specialists can hardly imagine the whole ML universe and their place in this universe. Lots of people are just curious about ML and are not deeply immersed in the subject. For those, it is also important to understand the structure of machine learning.
Visualization of concepts is one of the best ways to ensure correct understanding and memorization of the particular domains. This is exactly what mindmaps help to do. We have prepared the machine learning mindmap that we hope will be useful for you. Note that machine learning is a subfield of data science, that is the more wide area. For those who are interested in data science, we can recommend another our material – Data Science for Managers Mindmap.
When building our ML mindmap we used the following approach. We looked at ML from 3 different perspectives: types of tasks, applications, and approaches.
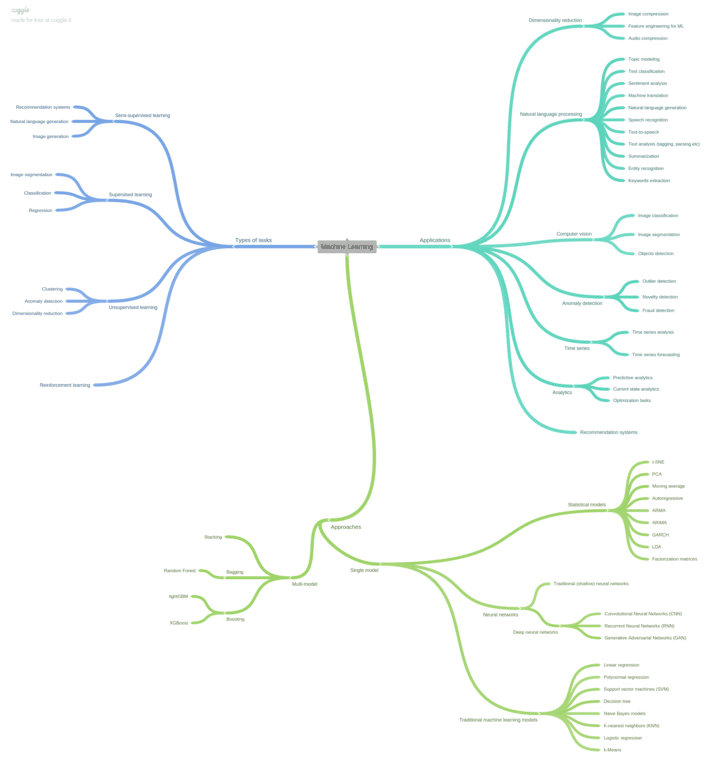
Types of tasks branch
There are several types of tasks in machine learning. The most common are supervised and unsupervised learning. Other types include semi-supervised learning and reinforcement learning.
Supervised learning is a type of task where your data is represented by input features and output correct answers. You want to teach your ML model to predict the right output answers based on the input features on the new (unseen) data. The examples of supervised learning tasks are classification (predicting the class/category) and regression (predicting the value/number). Also, image segmentation is an example of supervised learning as during training a model should look at correctly segmented images. You should note that some tasks that are not vivid examples of classification or regression actually belong to one of these types. For instance, object detection can be considered as a classification task because we look at the image (or separate part of the image) and try to answer the question: “Is there an object or not?”. This question is a binary classification.
Unsupervised learning is a situation where you have only input data and don’t have any correct answers (outputs). Clustering, anomaly detection, or dimensionality reduction are typical examples of unsupervised learning. Think about clustering: we have data and we need to detect clusters in it. We don’t have labeled data beforehand, so we don’t know which data point belongs to which cluster. The ML model should learn how to detect clusters without any prior knowledge. This means unsupervised learning.
Semi-supervised learning combines features from supervised and unsupervised learning. When you create a recommendation system you usually have some part of labeled data and some part of unlabeled data. Natural language generation models use the preceding context of the sentences to generate the next word. But their predictions have the probabilistic nature which gives us a reason to include them into semi-supervised learning type. Image generation is a task, based on Generative Adversarial Networks that are unsupervised learning algorithms that use a supervised loss as part of the training.
Reinforcement learning is a special type of task where your model should use a reward (the feedback from the environment) to learn how to do the right things on their own. For example, you can set up the environment for playing a game. If the model will play poorly, it will not get any reward points. But the aim of the model is to maximize the reward. So, the model will change its behavior in the next round of the game and if this behavior will generate more rewards than the previous, then the model will switch to this model. In the next round the model will try to change something else to increase its gain even more, and so on. Reinforcement learning is an interesting but complex subfield of machine learning.
Approaches branch
Now let’s explore the green branch of the mindmap – Approaches. In this branch, we have included methods that are used to solve different tasks. All methods we divided into single-model based and multi-model based. Single models are methods that use only one model. They can be divided into statistical models, traditional machine learning models, and neural networks.
Statistical methods are among the first ways to solve tasks similar to machine learning. They include methods for dimensionality reduction, methods for regression prediction, methods for analyzing data, etc. For example, Principal component analysis (PCA) is a well-known method for reducing dimensionality. Factorization matrices are widely used in building recommendation systems. Latent Dirichlet allocation (LDA) is an algorithm for topic modeling. A moving average can be used both for analyzing the previous time-series data and for making predictions for the future.
Traditional machine learning methods are probably those algorithms coming to minds of the majority of the beginners when they start to learn ML. Many methods can be used both for classification and regression (such as, say, support vector machines (SVM), decision tree, k-nearest neighbors (KNN)). However, some of them are more suitable for solving a specific type of task. Eventually, there are models that can be used only for a specific task. For instance, K-means is an algorithm for solving exclusively clustering task and logistic regression is a pure classification algorithm (don’t be confused by its name).
Neural networks are an area where the most ML hype is concentrated. In the same way, a neural network is nothing more but the mathematical algorithm with the specific structure. There are simple neural networks (sometimes they are called perceptrons) and deep neural networks. Deep neural networks are on the edge of ML advancements nowadays. All those cool things in computer vision and natural language processing are primarily done with the help of deep neural networks. The most popular types of deep neural networks are convolutional neural networks, recurrent neural networks, and generative adversarial networks.
The multi-model approach requires using several single models to solve a task. Stacking is when we use several different ML models (for example, from the category of traditional models) and then use their answers (outputs) as the input to another model(s). There can be several layers of models. Such a strategy often produces great results. However, the whole system becomes complex and it can be hard to deploy it in production.
Bagging means taking several models and average their predictions. For example, a random forest is an ensemble of decision trees. This allows reducing the variance while retaining the bias on a stable level. More about the bias-variance tradeoff you can read in our article.
Boosting is a method of ensembling which also uses many base models to improve the overall result. The difference from bagging is that boosting is a directed composition of algorithms. This means that every next model is being built in a way to reduce the error of the previously created composition of base models. The most popular implementations of gradient boosting are XGBoost and lightGBM.
Applications branch
Now we will move to applications – the last global branch of our mindmap. We are speaking about the areas where ML is used. This is not about industries where ML can be useful. This is rather about types of ML applications. But if you are interested in ML use cases you can look at our “Top X Data Science Use Cases in Y” blog posts series.
Generally, the types of ML applications are as follows: dimensionality reduction, natural language processing (NLP), computer vision (CV), anomaly detection, time series, analytics, and recommendation systems.
Dimensionality reduction allows reducing your data while keeping the most relevant information. It is used in image and audio compression, and for feature engineering in machine learning models creation pipeline.
Natural language processing (NLP) is a wide area that becomes more and more separate from other machine learning applications. Many experts even consider NLP as an independent subject. The applications of ML in NLP are as follows: topic modeling, text classification, sentiment analysis, machine translation, natural language generation, speech recognition, text-to-speech, text analysis, summarization, entity recognition, keywords extraction.
Computer vision (CV), like NLP, is becoming a huge separate subject. Most well-known CV applications are image classification, image segmentation, and object detection.
Anomaly detection is an application where the aim is to recognize something unexpected, non-typical in the data. Anomaly detection splits into novelty detection, outliers detection, and fraud detection. Also, it may happen that it is not novelty nor outliers, but a certain strange pattern in the data. We don’t include this situation in the mindmap, but if we did, we would call it as simple “anomaly detection”.
Time series is the area when we work with data that is based on time. For example, stock exchange prices, weather data, IoT sensors data, etc. We can either analyze the time series or predict the possible future values.
Analytics is the classical field of exploring the nature and patterns of data. There are predictive analytics (predict what can happen in future or on the unseen data), current state analytics (what insights can we derive from the current data without building predictive models), and optimization problems (for example, to explore how to get from point A to point B with the least consumption of different resources).
Finally, recommendation systems are the applications where you have a set of users and some content, and you want to create a system that would be able to recommend the relevant content for users. Such systems use special ML methods (like factorization machines) to utilize known data about the users and content items.
Conclusion
The mindmap we have developed is an attempt to explain the structure of machine learning for people who are not deeply engaged in this field. We demonstrated that machine learning can be considered from three different aspects: types of tasks, approaches (methods), and types of applications. It is clear that our mindmap cannot embrace all information about such a complex area as machine learning. There are some types of tasks, applications, and especially algorithms which are not included in the scheme. Also, we think that there is enough space for discussion about some points. We encourage a sound discussion about our mindmap but we want to remind you that the mindmap is the subjective opinion of the team of authors. Hopefully, this mindmap will help someone along an interesting journey towards machine learning.
{kind=link}