
Filters are the key thing in Computer Vision(Processing image data). You would have probably used different kinds of filters like the blur filter, vintage filters, etc in photo editing apps. Ever thought about how those filters work? . How do they give the desired effect?
We all know images are represented as matrix of Red, Green and Blue combination in mathematics and computer vision. And image filters are the same small matrix applied to an entire image. As mentioned above, the popular blur filter is represented as the image below.

This is the 3×3 matrix when applied to an entire image will actually blur the image. So what does this “applied” means?.
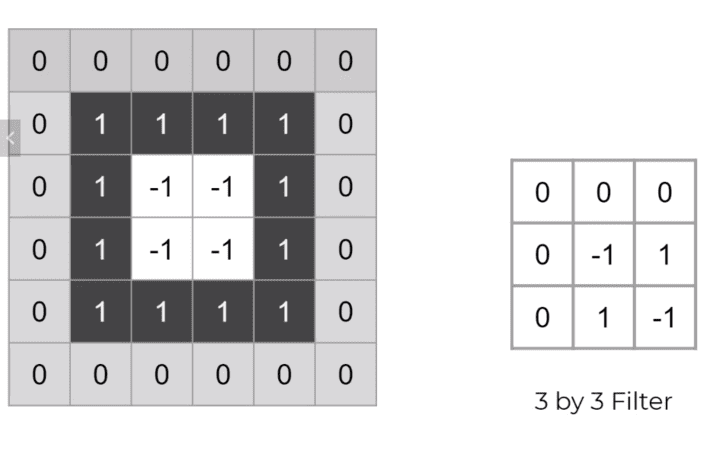
Filters actually help us to transform this image. For example see the image below. It is a gray-scale image in which 0 represents “Gray”, 1 represents “Black” and -1 represents “White”.

Now, let’s apply 3×3 filter as shown below.
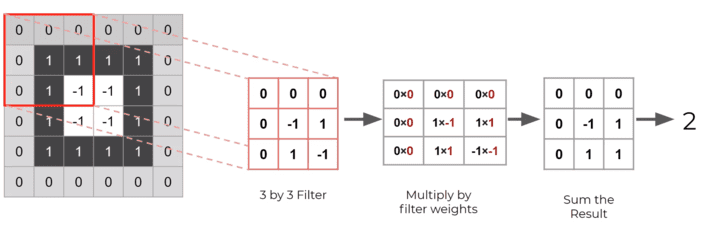
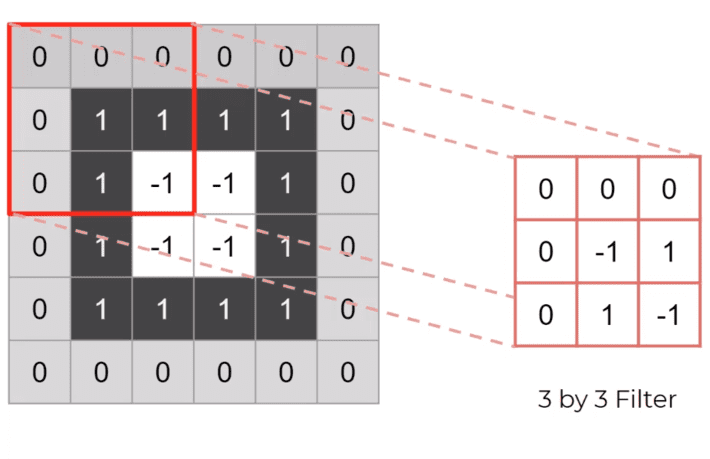
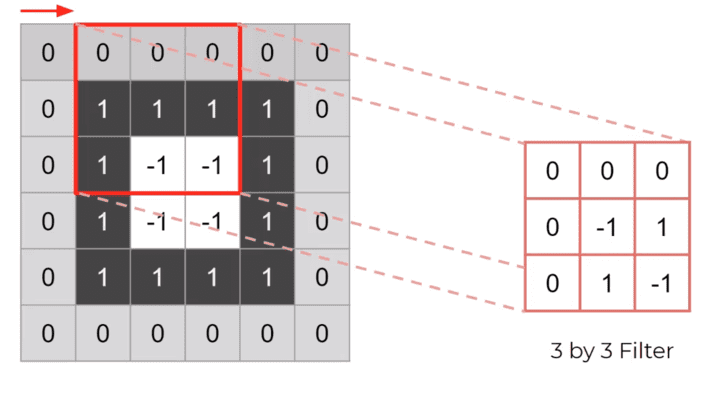
Now, to actually apply the filter we put the filter at the top left(as shown below) and slide it along
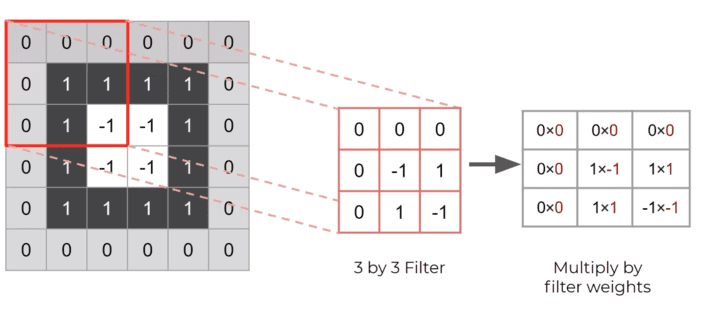
After that, we multiply the pixel value of the gray scale image by the filter values as shown below. We also represent filter values as filter weights.
We get some result, and then we sum the result as shown below. Having some final output value(Here it is 2).
Now notice how resolution is getting decreased as we are taking 9 input values and giving out 1 output values.
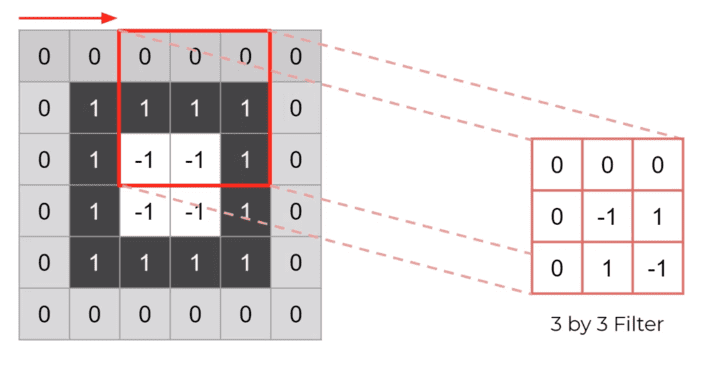
Eventually we are going to repeat the same process across the entire image by striding through the image one pixel by one pixel. We can control the stride distance, by default we have the stride distance =1.
When we take stride =2
If we talk about filters in the context of convolutional neural networks these filters are referred to convolutional kernels and the process of passing them over an image is known as convolution.
One important thing to remember in this process
During the process of convolution it may actually happen that we lose the borders of the image as shown below.
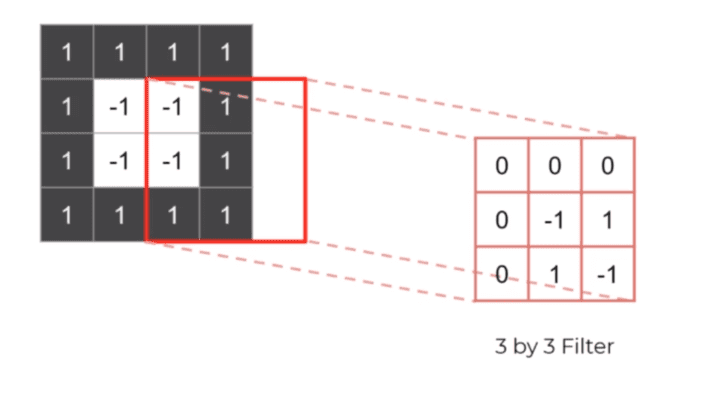
As we see we don’t have the value their we pad the image by the most common choice 0 like shown below.
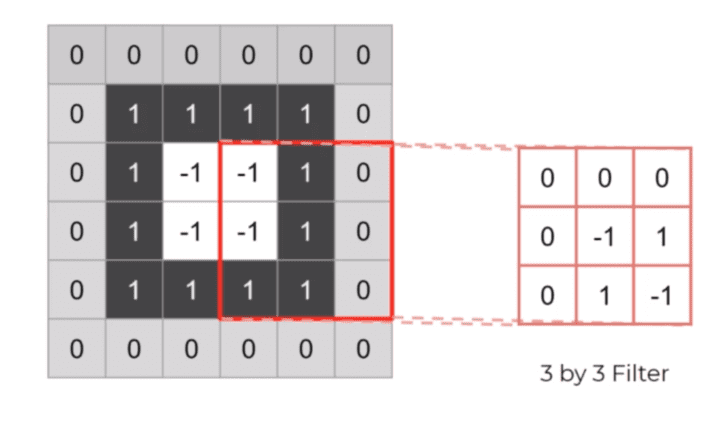
This is called padding which allows us to preserve the image size.
So you see how the concept of filter is important in the field of computer vision. Now in the architecture CNN’s it allows the neural network to come up with the best weights of a filter automatically. You don’t have worry about filter weights CNN will do it for you, but it is better to know what is happening under the hood.
Comment down what you think ?
,%20what%20are%20they%20and%20how%20they%20work%20in%20easy%20way.){kind=link}