
INTRODUCTION
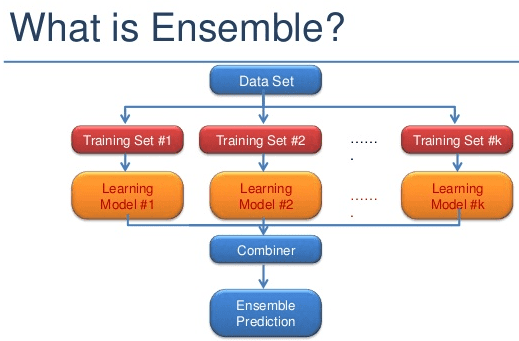
“Alone we can do so little and together we can do much” – a phrase from Helen Keller during 50’s is a reflection of achievements and successful stories in real life scenarios from decades. Same thing applies with most of the cases from innovation with big impacts and with advanced technologies world. The machine Learning domain is also in the same race to make predictions and classification in a more accurate way using so called ensemble method and it is proved that ensemble modeling offers one of the most convincing way to build highly accurate predictive models. Ensemble methods are learning models that achieve performance by combining the opinions of multiple learners. Typically, an ensemble model is a supervised learning technique for combining multiple weak learners or models to produce a strong learner with the concept of Bagging and Boosting for data sampling.
BAGGING (Bootstrap Aggregation)
Bagging or Bootstrap aggregation of sample data can be used for reducing the problem of overfitting and also variance. It is a special case of model averaging by generating additional data for model to learn most effectively from our original dataset using different combinations to produce multi-datasets of the same size as our original data. It is the case of taking some sample data uniformly and with replacement without generating arbitrary data. The type of bootstrap sampling is expected to have the fraction (1-1/e) which is nearly equivalent to 63.2% unique records and other being duplicates. This concept is mostly used in decision tree methods.
BOOSTING
Boosting can be used primarily for reducing bias and also variance. It is a weighted average approach, i.e. by iteratively learning and forming multiple weak learner and combining them to make a final strong learner. Adding of each weak learner to make a strong learner is related to the accuracy of each learner. The weight is recalculated after each weak learner is added to overcome the problem of misclassified gain weight.
Multiple boosting algorithms are available to use such as AdaBoost, Gradient Boost, XGBoost, LPBoost, BrownBoost etc. Different boosting algorithm has its own advantages over different types of dataset. By tuning multiple algorithms with a wider range of input data, classification or good predictive modeling can be build.
For example, Adaboost performs well in case of binary class classification problems. But it is sensitive to noisy data and outliers.
The steps followed for Adaboost algorithm:
- Assign equal weight to all the training examples.
- Selection of a base algorithm or making of a first Decision stump
- Reweight to misclassified observation or resample the instances in training set.
- Keep repeating from step 2 each time for producing a new classifier to get full accuracy.
- To make the final strong classifier, count the “vote” across all learning classifiers build from step 2
In case of continuous variables regression booster such as the Gradient boost algorithm is suitable.
The steps followed in Gradient Boost appraoch:
- Learn a model
- Compute errors of each observation from the mean
- Find the variables that can split the errors perfectly and find the value for the split.
- Learn a new model which can reduce the previous errors with each split.
- Repeat the above steps until cost function is optimized.
- Form the final model by combine weighted mean of all the classifier.
STACKING (Stacked Generalization)
Stacking is a different approach of combining multiple models with the concept of meta – learning. Though the appraoch don’t have empirical formula for weight function the final functionality is same as bagging and boosting.
The steps followed in Stacking approach:
- Split two disjoint the training sets
- Train several base learners on one part
- Test the base learners on the second part
- Using the predictions from above step as the inputs, and the correct responses as the outputs, train a higher level learner.
Which models should be ensemble
Let us consider models A, B and C with an accuracy of 87%, 82%, 72% respectively. Suppose, A and B are highly correlated and C is not at all correlated with both A & B. In this type of scenarios instead of combining models A & B, model C should be combined with model A or model B to reduce generalized errors.
Proper way to identify the weight of different models:
In ensembling approach some standard way should be used while giving weight to different models.
Few of the techniques are:
- Find collinearity of different models to identify the base models and to remove highly correlated models so that final model can handle generalized errors.
- Neural Network can also be used to find the weight between input variable to nodes and then from nodes to output variables.
- For finding optimal weight, other approaches such as bagging of ensemble method, forward selection of learners etc. Can be used.
CONCLUSION
Ensemble method is a combination of multiple models, that helps to improve the generalization errors which might not be handled by a single modeling approach.
Originally Posted Here.
{kind=link}