
Choosing features to improve a performance of a particular algorithm is a difficult question. Currently here is PCA, which is difficult to understand (although it can be used out-of-the-box), requires centralizing and scaling of features and is not easy to interpret. In addition, it does not allows to improve prediction performance for a particular outcome (if its accuracy is lower than for others or it has a particular importance). My method enables to use features without preprocessing. Therefore a resulting prediction is easy to explain. Plus it can be used to improve a performance of a some outcome value. It based on comparison of feature densities and has a good visual interpretation, which does not require thorough knowledge of linear algebra or calculus. I have an example of the method application with adding chosen features completely worked out with R code here:
a long blog post (includes source code and datasets)
The method can be used to evaluate consistency of feature differences during boosting or cross-validation as well.
Regretfully there is no definite rule which tells how to use the method to get a specified accuracy, for example, 99%. I believe if enough people are interested it may be worked out.
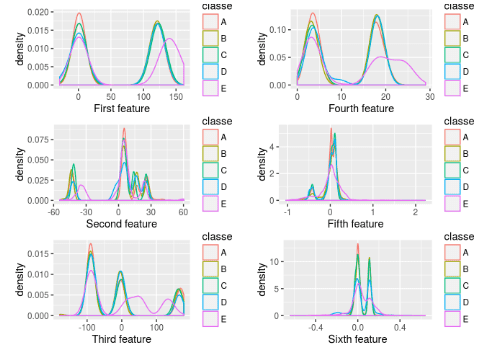
Chart from the long article
{kind=link}