
 Manufacturing Line, Wikimedia Commons, 2014
Manufacturing Line, Wikimedia Commons, 2014
Fakery certainly isn’t limited to news and social media. The Organisation for Economic Co-operation and Development (OECD) estimated in 2016 that 6.8 percent of physical goods imported by the EU were fakes.
Most documented fakes involve name-brand apparel, electronics and related goods, but fake pharmaceuticals are a major concern as well.
90 percent of manufactured product fakes originate in China, according to Michigan State’s Center for Anti-Counterfeiting and Product Protection, which estimated in 2020 that counterfeit exports from China increased 10,000 percent since 2000. The value of counterfeits exported from that country alone in 2020 were estimated at $400 billion.
To combat fakes and alleviate bottlenecks, suppliers have been struggling together for decades to comprehensively and reliably track and trace raw materials and components as they move through the supply chain. Supply replenishment, production and assembly, end product packaging and the points of sale are all in need of more transparency.
One of the main inhibitors to supply chain data sharing is centralization or a walled garden approach to the system intended for that sharing and collaboration.
How decentralized data storage is helping with supply chain data sharing
When data storage is inherently centralized and overly siloed, boundary crossing and scaling becomes a huge issue. This inability to share at scale is exacerbated by application-centric architectures that hoard the logic that data needs to connect and provide context. Both physical goods and digital assets from advertising to content to online credentials are subject to the same unresolved supply chain provenance issues as a result.
Trust and interoperability throughout the chain are key to effective asset provenance, whether those assets are physical or not. Imagine if you’re tracking shipments of vaccines against COVID-19 through the chain, and you lose track at a particular link in the chain. The whole shipment would be suspect and therefore compromised. Supply chain consortia and regulatory bodies have been focused on specifically addressing this issue. And they have been especially receptive to blockchain-based solutions, which harness the power of decentralization and peer-to-peer architecture.
Since the early 2010s, blockchains (both enterprise distributed ledgers and the permissionless blockchains supporting Bitcoin and Ether coin exchange, for example) have been touted as a way to alleviate the problems materials and product supplies have faced. How do pharmacies, for example, ensure their prescriptions are genuine as claimed and meet their standards with the help of end-to-end tracking and tracing?
The cryptography and immutability by blockchains do help with verification essential to data trust. And they are well suited for use by loosely knit consortia in industries involving a plethora of suppliers, shippers, etc.
But blockchains on their own aren’t enough. For one thing, they only store miniscule amounts of data–the Bitcoin blockchain, for example, only held around 360 gigabytes of data as of October 2021. What blockchains store is mainly confirmatory signatures and related one-time messaging.
For another, these chains are slow and expensive, particularly those that require proof-of-work (or coin mining-style) consensus (as Bitcoin and Ethereum do). The energy expenditure of one Ethereum blockchain transaction is equivalent to that of 1,000 VISA card transactions, according to Raynor de Best of Statista. Proof of stake and other less energy-intensive consensus mechanisms are becoming more popular. Blockchains in general are rapidly evolving, with Ethereum and others pondering a move to less energy-hungry consensus methods and more efficient means of tamperproof transaction processing.
The data these chains do store immutably and in a tamperproof fashion are verifying messages and digital signatures. These messages and signatures help substantially with confirming that information elsewhere hasn’t been tampered with. But the voluminous information needed for other than confirmatory purposes is stored off-chain.
90 percent of data is less structured, according to author and futurist Bernard Marr. Less-structured data includes, but is hardly limited to, the following:
- Emails
- Text files
- Photos
- Video files
- Audio files
- Webpages and blog posts
- Social media sites
- Presentations
- Call center transcripts/recordings
- Open-ended survey responses
Bernard Marr, “What Is Unstructured Data And Why Is It So Important To Businesses?” Retrieved December 17, 2021, https://bernardmarr.com/
This is the kind of data (or content) that investigators love, because it tells the story of the context that is so critical to specificity and understanding. Less-structured data relevant to provenance that hasn’t been stripped of its richness can be married to transactions, data that should be stored as semantically articulated, relationship-rich data in knowledge graphs that are linked to blockchains. Some well-designed P2P data networks are suited to storing and managing knowledge graph data. They are also attractive for supply chain applications because they can connect to blockchains or other distributed hash table (DHT) addressing.
In fact, P2P data networks and blockchains are synergistic and complementary, and both should be in view when painting pictures of how web 3.0 systems are coming together. While the heterogeneous graph data networks are the yang, the more deterministic, tightly structured transactional blockchains are the yin.
Case studies
Trace Labs (who are behind OriginTrail.io) is one of the few technology companies I’ve come across who has worked to harness the power of both standards-based semantic knowledge graphs and blockchains together. In addition, they are supporting the W3C verifiable credentials (VC) standard, which makes it possible to confirm the credentials individuals hold to do everything from drive legally to conduct open heart surgery as a qualified MD in near real time via decentralized messaging.
The VC standard also makes it feasible to store, protect and correlatable identifiers in an encrypted hub (such as on a phone), where they can be verified while staying in place, so that organizations don’t have to duplicate and store that sensitive information themselves.
Here are a few examples highlighted by CTO Branimir Rakić of Trace Labs on how the OriginTrail decentralized knowledge graph has been used with blockchains such as Ethereum for supply chain and other asset development/production/distribution process tracking and verification purposes.
- 400,000 of the British Standards Institution’s training certificates reside on OriginTrail’s decentralized knowledge graph, where they become discoverable and queryable. Discoverability is not limited to a single or a handful of datasets, but all the datasets that can be semantically linked and contextualized. The connected blockchain (Ethereum) is used to verify that the training certificates remain tamperproof. That same data is discoverable and queryable with the help of the larger OriginTrail system.
- The new Church of Oak distillery is located on the restored site of a much older distillery called Monasterevin in Kildare, a small town about 50 km west of Dublin, Ireland. The whiskey produced at this facility is tracked and traced from “grain to glass” using a decentralized knowledge graph that connects to various blockchains, including Ethereum. With this method, aficionados of single malt can use a mobile app to review the provenance of the individual bottles of whisky they may buy, as well as check the British Standards Institution’s service quality verification. The tracking and tracing not only ensures the genuineness met with the end product, it provides a means of proving the eco-friendly nature of the distillery’s methods and processes
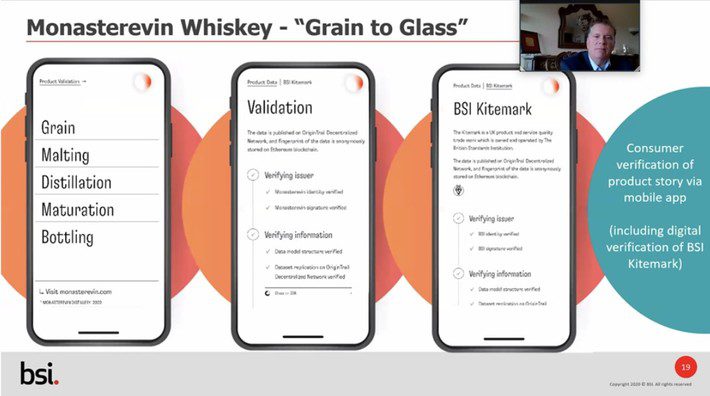
OriginTrail, https://twitter.com/origin_trail/status/1339606640887152642?s=20, Dec. 2020
- SBB Swiss Federal Railways uses OriginTrail to track various railway assets across country boundaries. Among other things, they collect data on rail conditions at many different points along the multi-enterprise rail network in order to predict when rails are prone to splitting and need to be replaced.
Supply chain provenance and predictive analytics in edge computing
As it expands, the global economy needs to scale to meet the needs of more and more people in more and more places, including remote locales that can’t be served adequately with older legacy supply chain methods and architectures. That’s where edge computing comes into play. Rail companies such as Union Pacific in the US use edge computing to capture and analyze detailed imagery of railcar wheels to be able to predict failures.
At a system level, supply consortia are keen on predicting and addressing supply bottlenecks as quickly as possible, and at the same time ensuring product or asset quality. But the system level is where the biggest challenge arises.
What some may not have understood yet is how essential it will soon be to work across supply networks. That means networking and aligning data entity by entity for the purpose of comparisons as well as mere connections or associations.
Going beyond mere associations between entities implies new relationship logic built into inherently networked knowledge graphs. As we move from batch to more and more streaming data, there’s no point to networking just dumb, undercontextualized, static, aging data intended for a single, transitory purpose. What we’ll need to network is the smart, self-describing, evolving variety–sharable data + logic mingled in dynamic graphs architected for articulation, discoverability, many different purposes, and scale.
{kind=link}