
In the beginning, there was data
The intent of anonymization is to ensure the privacy of data. Companies use it to protect sensitive data. This category of data encompasses:
- personal data,
- business information such as financial information or trade secrets,
- classified information such as military secrets or governmental information.
So, anonymization is for instance a way of complying with the privacy regulations related to personal data. Personal data and business data types can overlap. This is where lies customer information. But not all business data falls under regulations. I’ll focus here on the protection of personal data.
Example of sensitive data types
In Europe, regulators define as “personal data” any information that relates to someone (your name for example). Information linking to a person in any way also falls under that definition.
As personal data collection democratized over the previous century, the question of data anonymization started to rise. The regulations coming into effect around the world sealed the importance of the matter.
What is data anonymization and why should we care?
Let’s begin with the classic definition. The EU’s General Data Protection Regulation (GDPR) defines anonymized information as follow:
“information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable.”
The “identifiable” and “no longer” parts are essential. It doesn’t only mean that your name shouldn’t appear in the data anymore. It also means that we shouldn’t be able to figure out who you are from the rest of the data. This refers to the process of re-identification (sometimes de-anonymization).
The same GDPR recital also states a very important fact:
“[…] data protection should therefore not apply to anonymous information”.
So, if you manage to anonymize your data, you are no longer subject to GDPR data protection laws. You could perform any processing operations such as analysis or sales. This opens quite some opportunities:
- Selling data is an obvious first use. Around the world, privacy regulations are restricting the trade of personal data. Anonymized data offers an alternative for companies.
- It represents an opportunity for collaborative work. Many companies share data for innovation or research purposes. They can limit risks by using anonymized data.
- It also creates opportunities for data analysis and Machine Learning. Getting access to private, yet compliant, data is hard. Anonymized data represents a safe raw material for statistical analysis and model training.
The opportunities are clear. But truly anonymized data is often not what we think.
The spectrum of data privacy mechanisms
Privacy-preservation of data is a spectrum. Over the years, experts developed a collection of methods, mechanisms, and tools. These techniques produce data with various levels of privacy and various risk levels of re-identification. We could say it ranges from personally identifiable data to truly anonymized data.
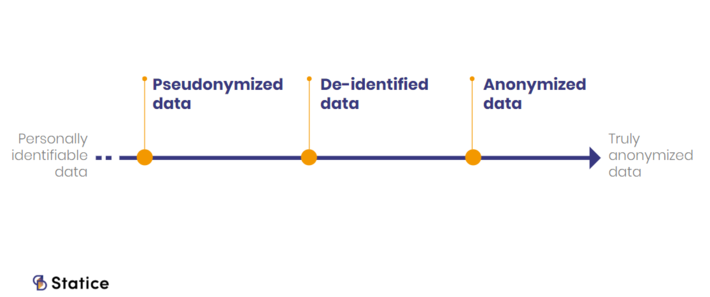
A spectrum of data privacy
On one end, you have data that contains direct personal identifiers. Those are elements from which we can identify you like name, address or telephone number. On the other end, you have the anonymous data that GDPR refers to.
But there is an intermediary category of data. It lives between identifiable and anonymized data: pseudonymized and de-identified data. Note that I’m not certain of this delimitation. Some presentations make pseudonymization a part of de-identification, some don’t.
In itself, there is nothing wrong with the techniques to produce this “intermediary data”. They are efficient data minimization techniques. Depending on the requirements of one’s use-cases, they will be relevant and useful.
What we need to keep in mind is the fact they don’t produce truly anonymous data. Their mechanisms do not have the guarantee to prevent re-identification. And referring to the data they produce as “anonymous data”, is misleading.
There is anonymous and “anonymous”
Pseudonymization and de-identification are indeed a way of preserving certain aspects of data privacy. But they don’t produce anonymized data, per the GDPR definition.
Pseudonymization techniques remove or replace the direct personal identifiers from the data. For instance, you delete all the names and emails from a dataset. You can’t identify someone directly from pseudonymized data.
But you can do it indirectly. Indeed, the rest of the data often retains indirect identifiers. These are information that you can combine to create direct identifiers. They could date of birth, zip codes, or gender for example.
For that matter, pseudonymization has a separate definition within the GDPR framework.
“[…] the processing of personal data in such a way that the data can no longer be attributed to a specific data subject without the use of additional information”.
Contrary to anonymous data, pseudonymous data falls under the GDPR regulations.
De-identifications techniques remove both direct and indirect personal identifiers from the data. On paper, the frontier between de-identified data and anonymized data is simple. The latest offers technical safeguards that guarantee that data can never be re-identified. It’s a “true until proven false” kind of situation. De-identified data is somehow anonymous until it’s not.
And experts are pushing the line further every time they re-identify data that was de-identified.
Data re-identifications keep on redefining anonymous
The mechanism types described above do not have the same effectiveness for privacy-preservation. Hence, what you intend to do with the data matters. Companies regularly release or sell data that they claim “anonymous”. It becomes a problem when the methods they used don’t guarantee that.
Many events showed that pseudonymized data was a poor privacy-preservation mechanism. The indirect identifiers in the data create a strong risk for re-identification. And as available data volumes grow, so does the opportunities to cross-reference datasets:
- In 1990, an MIT graduate re-identified the Massachusetts Governor. He used de-identified medical dataset and census data.
- In 2006, AOL shared de-identified search data as part of a research initiative. Researchers were able to link search queries with the individuals behind them.
- In 2009, Netflix released an anonymized movie rating dataset as part of a contest. Texas researchers successfully re-identified the users.
- In 2009, researches predict an individual’s Social Security Number using only publicly available information.
Recently, studies showed that de-identified data also was, in fact, re-identifiable. Researchers at UCL in Belgium and Imperial College London found that:
“99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes”.
Another study, conducted on anonymized cellphone data, showed that:
“four spatio-temporal points are enough to uniquely identify 95% of the individuals”.
Technology is improving. More data is being created. As a result, researchers are pushing the delimitation between de-identified and anonymous data. In 2017, researchers released a study stating that:
“web-browsing histories can be linked to social media profiles using only publicly available data.”
Another alarming point arises from the exposition of personal data through breaches. The amount of personal information leaked keeps on growing.
Taken separately some datasets aren’t re-identifiable. But combined with leaked data, they represent a larger threat. Students from Harvard University were able to re-identify de-identi… using leaked data.
In conclusion, what we consider “anonymous data”, is often not. Not all data sanitization methods generate truly anonymous data. Each presents its own advantages, but none offer the same level of privacy as anonymization. As we produce more data, it becomes harder to create truly anonymized data. And the risks of companies releasing potentially re-identifiable personal data grows.
{kind=link}