
Internet of Things (IoT) has generated a ton of excitement and furious activity. However, I sense some discomfort and even dread in the IoT ecosystem about the future – typical when a field is not growing at a hockey-stick pace . . .
“History may not repeat itself but it rhymes”, Mark Twain may have said. What history does IoT rhyme with?
I have often used this diagram to crisply define IoT.

Even 10 years ago, the first two blocks in the diagram were major challenges; in 2017, sensors, connectivity, cloud and Big Data are entirely manageable. But extracting insights and more importantly, applying the insights in, say an industrial environment, is still a challenge. While there are examples of business value generated by IoT, the larger value proposition beyond these islands of successes is still speculative. How do you make it real in the fastest possible manner?
In a slogan form, the value proposition of IoT is ”Do more at higher quality with better user experience”. Let us consider a generic application scenario in industrial IoT.
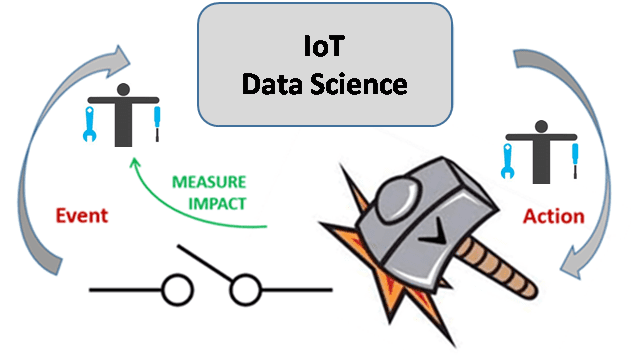
IoT Data Science prescribes actions (“prescriptive analytics”) which are implemented, outcomes of which are monitored and improved over time. Today, humans are involved in this chain, either as observers or as actors (picking a tool from the shelf and attaching it to the machine).
BTW, when I mentioned “Better UX” in the slogan, I was referring to this human interaction elements improved by “Artificial Intelligence” via natural language or visual processing.
Today and for the foreseeable future, IoT Data Science is achieved through Machine Learning which I think of as “competence without comprehension” (Dennett, 2017). We cannot even agree on what human intelligence or comprehension is and I want to distance myself from such speculative (but entertaining) parlor games!
Given such a description of the state of IoT art in 2017, it appears to me that what is preventing us from hockey-stick growth is the state of IoT Data Science. The output of IoT Data Science has to serve two purposes: (1) insights for the humans in the loop and (2) lead us to closed-loop automation, BOTH with the business objective of “Do More at Higher Quality” (or increased throughput and continuous improvement).
Machine Learning has to evolve and evolve quickly to meet these two purposes. One, IoT Data Science has to be more “democratized” so that it is easy to deploy for the humans in the loop – this work is underway by many startups and some larger incumbents. Two, Machine Learning has to become *continuous* learning for continuous improvement which is also at hand (NEXT Machine Learning Paradigm: “DYNAMICAL” ML).
With IoT defined as above, when it comes to “rhyming with history”, I make the point (in Neural Plasticity & Machine Learning blog) that the current Machine Learning revolution is NOT like the Industrial Revolution (of steam engine and electrical machines) which caused productivity to soar between 1920 and 1970; it is more like the Printing Press revolution of the 1400s!
Printing press and movable type played a key role in the development of Renaissance, Reformation and the Age of Enlightenment. Printing press created a disruptive change in “information spread” via augmentation of “memory”. Oral tradition depended on how much one can hold in one’s memory; on the printed page, memories last forever (well, almost) and travel anywhere.
Similarly, IoT Data Science is in the early stages of creating disruptive change in “competence spread” via Machine Learning (which is *competence without comprehension*) based on Big Data analysis. Humans can process only a very limited portion of Big Data in their heads; Data Science can make sense of Big Data and provide competence for skilled actions.
To make the correspondence explicit, “information spread” in the present case is “competence spread”; “memory” analog is “learning” and “printed page” is “machine learning”.
Just like Information Spread was enhanced by “augmented memory” (via printed page), Competence Spread will be enhanced by Machine Learning. Information Spread and the Printing Press “revolution” resulted in Michelangelo paintings, fractured religions and a new Scientific method. What will Competence Spread and IoT Data Science “revolution” lead to?!
From an abstract point of view, Memory involves more organization in the brain and hence a reduction in entropy. Printed page can hold a lot more “memories” and hence the Printing Press revolution gave us an external way to reduce entropy of “the human system”. Competence is also an exercise in entropy reduction; data get analyzed and organized; insights are drawn. IoT Data Science is very adept at handling tons of Big Data and extracting insights to increase competence; thus, IoT Data Science gives us an external way to reduce entropy.
What does such reduction in entropy mean in practical terms? Recognizing that entropy reduction happens for Human+IoT as a *system*, the immediate opportunity will be in empowering the human element with competence augmentation. What I see emerging quickly is, instead of a “personal” assistant, a Work Assistant which is an individualized “machine learner” enhancing our *work* competence which no doubt, will lead each of us to “do more at higher quality”. Beyond that, there is no telling what amazing things “competence-empowered human comprehension” will create . . .
I am no Industrial IoT futurist; in the Year 1440, Gutenberg could not have foreseen Michelangelo paintings, fractured religions or a new Scientific method! Similarly, standing here in 2017, it is not apparent what new disruptions IoT revolution will spawn that drop entropy precipitously. I for one am excited about the possibilities and surprises in store in the next few decades.
PG Madhavan, Ph.D. – “LEADER . . . of a life in pursuit of excellence . . . in IoT Data Science”
{kind=link}