
Consider a problem where you are working on a machine learning classification problem. You get an accuracy of 98% and you are very happy. But that happiness doesn’t last long when you look at the confusion matrix and realize that majority class is 98% of the total data and all examples are classified as majority class. Welcome to the real world of imbalanced data sets!!
Some of the well-known examples of imbalanced data sets are
1 – Fraud detection: where number of fraud cases could be much smaller than non-fraudulent transactions.
2- Prediction of disputed / delayed invoices: where the problem is to predict default / disputed invoices.
3- Predictive maintenance data sets, etc
In all the above examples, the cost of mis-classifying minority class could very high. That means, if I am not able to identify the fraud cases correctly, the model won’t be useful.
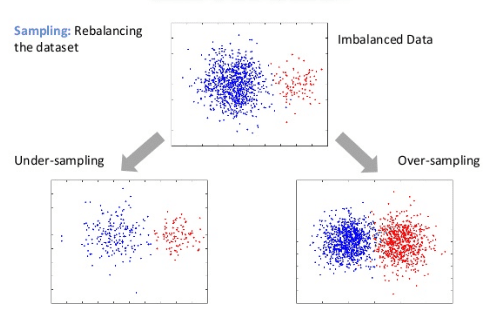
There are multiple ways of handling unbalanced data sets. Some of them are : collecting more data, trying out different ML algorithms, modifying class weights, penalizing the models, using anomaly detection techniques, oversampling and under sampling techniques etc.
I am focusing mainly on SMOTE based oversampling techniques in this article. As a data scientist you might not have direct control over collection of more data which might need various approvals from client, top management and could also take more time etc. Also, applying class weights or too much parameter tuning can lead to overfitting. Undersampling technique can lead to loss of important information. But that might not be the case with oversampling techniques. Oversampling methods can be easily tried and embedded in your framework.
Over Sampling Algorithms based on SMOTE
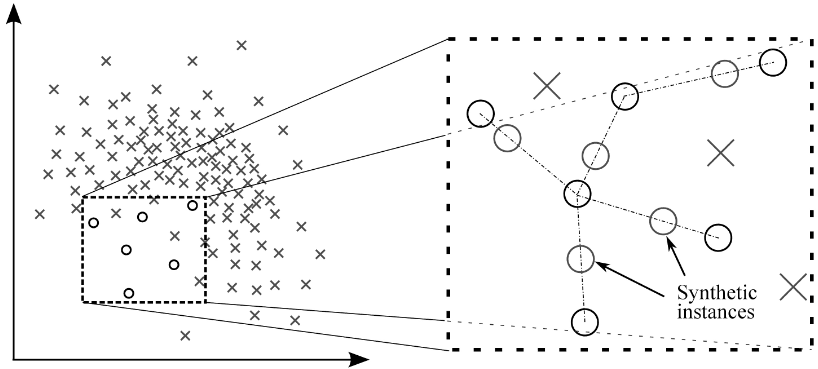
1-SMOTE: Synthetic Minority Over sampling Technique (SMOTE) algorithm applies KNN approach where it selects K nearest neighbors, joins them and creates the synthetic samples in the space. The algorithm takes the feature vectors and its nearest neighbors, computes the distance between these vectors. The difference is multiplied by random number between (0, 1) and it is added back to feature. SMOTE algorithm is a pioneer algorithm and many other algorithms are derived from SMOTE.
Reference: SMOTE
R Implementation: smotefamily, unbalanced, DMwR
Python Implementation: imblearn
2- ADASYN: ADAptive SYNthetic (ADASYN) is based on the idea of adaptively generating minority data samples according to their distributions using K nearest neighbor. The algorithm adaptively updates the distribution and there are no assumptions made for the underlying distribution of the data. The algorithm uses Euclidean distance for KNN Algorithm. The key difference between ADASYN and SMOTE is that the former uses a density distribution, as a criterion to automatically decide the number of synthetic samples that must be generated for each minority sample by adaptively changing the weights of the different minority samples to compensate for the skewed distributions. The latter generates the same number of synthetic samples for each original minority sample.
Reference: ADASYN
R Implementation: smotefamily
Python Implementation: imblearn
3- ANS: Adaptive Neighbor Synthetic (ANS) dynamically adapts the number of neighbors needed for oversampling around different minority regions. This algorithm eliminates the parameter K of SMOTE for a dataset and assign different number of neighbors for each positive instance. Every parameter for this technique is automatically set within the algorithm making it become parameter free.
Reference: ANS
R Implementation: smotefamily
4- Border SMOTE: Borderline-SMOTE generates the synthetic sample along the borderline of minority and majority classes. This also helps in separating out the minority and majority classes.
Reference – Border SMOTE
R Implementation: smotefamily
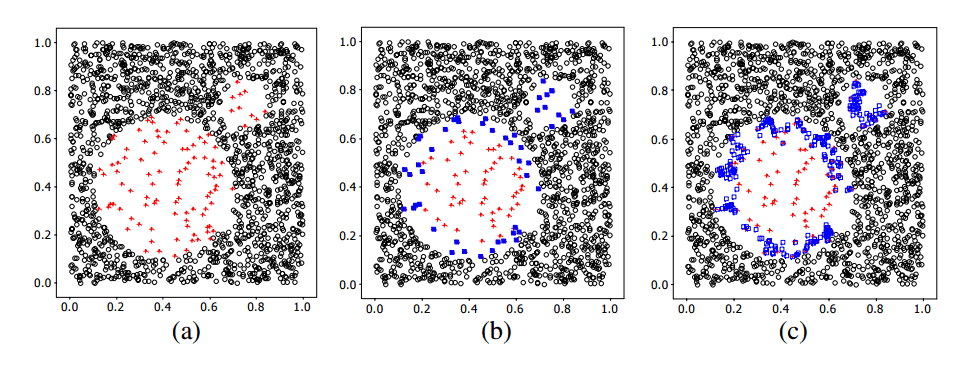
5-Safe Level SMOTE: Safe level is defined as the number of a positive instances in k nearest neighbors. If the safe level of an instance is close to 0, the instance is nearly noise. If it is close to k, the instance is considered safe. Each synthetic instance is generated in safe position by considering the safe level ratio of instances. In contrast, SMOTE and Borderline-SMOTE may generate synthetic instances in unsuitable locations, such as overlapping regions and noise regions.
Reference: SLS
R Implementation: smotefamily
6- DBSMOTE: Density-Based Synthetic Minority Over-sampling Technique is based on clustering algorithm DBSCAN. The clusters are discovered by DBSCAN Algorithm. DBSMOTE generates synthetic instances along a shortest path from each positive instance to a pseudo-centroid of a minority-class cluster
Reference: DBSMOTE
R Implementation: smotefamily
Combining Oversampling and Undersampling:
1-SMOTETomek: Tomek links can be used as an under-sampling method or as a data cleaning method. Tomek links to the over-sampled training set as a data cleaning method. Thus, instead of removing only the majority class examples that form Tomek links, examples from both classes are removed
Reference: SMOTE Tomek
Python Implementation: imblearn

2-SMOTEENN: Just like Tomek, Edited Nearest Neighbor removes any example whose class label differs from the class of at least two of its three nearest neighbors. The ENN method removes the instances of the majority class whose prediction made by KNN method is different from the majority class. ENN method can remove both the noisy examples as borderline examples, providing a smoother decision surface. ENN tends to remove more examples than the Tomek links does, so it is expected that it will provide a more in depth data cleaning
Below is the list of packages and algorithms available in python and R.
Python
1- Imblearn
The under sampling has following algorithms implemented:
- Cluster Centroids
- Condensed Nearest Neighbor
- Edited Nearest Neighbors
- Repeated Edited Nearest Neighbors
- All KNN
- Instance Hardness Threshold
- Near Miss
- Neighborhood Cleaning Rule
- One Sided Selection
- Random Under Sampler
- Tomek Links
While Over Sampling has following algorithms implemented:
1.ADASYN
2.Random Over Sampler
3.SMOTE
The combination of oversampling and undersampling covers SMOTEENN and SMOTETomek
Link : – IMBLEARN
R:
1- ROSE: The package only implements the algorithm Random Over Sampling
Link: ROSE
2- DMwR: The package reads as “Data Mining with R” and comes with implementation of SMOTE algorithm. SMOTE algorithm uses nearest neighbor concept to oversample the minority class.
Link: DMwR
3- unbalanced: The unbalanced package has implementation of following algorithms
- Tomek Link,
- Condensed Nearest Neighbor(CNN),
- One Sided Selection(OSS),
- Edited Nearest Neighbor(ENN),
- Neighborhood Cleaning Rule (NCL),
- SMOTE.
Link: unbalanced
The unbalanced package also offers the implementation of racing algorithm which suggest best method for unbalanced dataset.
4- smotefamily :
- ADASYN
- ANS
- BorderSMOTE
- DBSMOTE
- RSLS
- LS
- SMOTE
Link: smotefamily
{kind=link}