
This article was written by Timothy B. Lee.
New research from Google’s UK-based DeepMind subsidiary demonstrates that deep neural networks have a remarkable capacity to understand a scene, represent it in a compact format, and then “imagine” what the same scene would look like from a perspective the network hasn’t seen before.
Human beings are good at this. If shown a picture of a table with only the front three legs visible, most people know intuitively that the table probably has a fourth leg on the opposite side and that the wall behind the table is probably the same color as the parts they can see. With practice, we can learn to sketch the scene from another angle, taking into account perspective, shadow, and other visual effects.
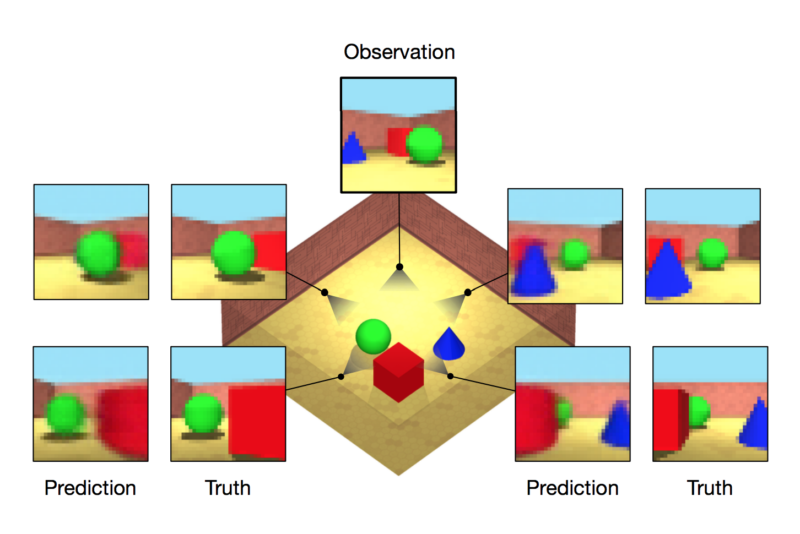
A DeepMind team led by Ali Eslami and Danilo Rezende has developed software based on deep neural networks with these same capabilities—at least for simplified geometric scenes. Given a handful of “snapshots” of a virtual scene, the software—known as a generative query network (GQN)—uses a neural network to build a compact mathematical representation of that scene. It then uses that representation to render images of the room from new perspectives—perspectives the network hasn’t seen before.
The researchers didn’t hard-code any prior knowledge about the kind of environments they would be rendering into the GQN. Human beings are aided by years of experience looking at real-world objects. The DeepMind network develops its own similar intuition simply by examining a bunch of images from similar scenes.
“One of the most surprising results [was] when we saw it could do things like perspective and occlusion and lighting and shadows,” Eslami told us in a Wednesday phone interview. “We know how to write renderers and graphics engines,” he said. What’s remarkable about DeepMind’s software, however, is that the programmers didn’t try to hard-code these laws of physics into the software. Instead, Eslami said, the software started with a blank slate that was able to “effectively discover these rules by looking at images.”
It’s the latest demonstration of the incredible versatility of deep neural networks. We already know how to use deep learning to classify images, win at Go, and even play Atari 2600 games. Now we know they have a remarkable capacity for reasoning about three-dimensional spaces.
How DeepMind’s generative query network works
Here’s a simple schematic from DeepMind that helps provide an intuition about how the GQN is put together:
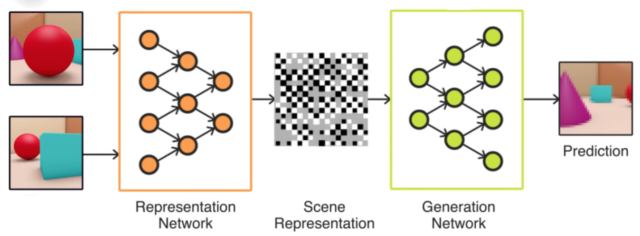
Under the hood, the GQN is really two different deep neural networks connected together. On the left, the representation network takes in a collection of images representing a scene (together with data about the camera location for each image) and condenses these images down to a compact mathematical representation (essentially a vector of numbers) of the scene as a whole.
Then it’s the job of the generation network to reverse this process: starting with the vector representing the scene, accepting a camera location as input, and generating an image representing how the scene would look like from that angle.
Obviously, if the generation network is given a camera location corresponding to one of the input images, it should be able to reproduce the original input image. But this network can also be provided with other camera positions—positions for which the network has never seen a corresponding image. The GQN is able to produce images from these locations that closely match the “real” image that would be taken from the same location.
To read the rest of the article, click here.
{kind=link}